如何从 Pandas DataFrame 中随机选择行
让我们讨论如何从 Pandas DataFrame 中随机选择行。可以通过不同的方式从 DataFrame 中随机选择行。
使用列表字典创建一个简单的数据框。
Python3
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# select all columns
dfPython3
# Selects one row randomly using sample()
# without give any parameters.
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Select one row randomly using sample()
# without give any parameters
df.sample()Python3
# To get 3 random rows
# each time it gives 3 different rows
# df.sample(3) or
df.sample(n = 3)Python3
# Fraction of rows
# here you get .50 % of the rows
df.sample(frac = 0.5)Python3
# fraction of rows
# here you get 70 % row from the df
# make put into another dataframe df1
df1 = df.sample(frac =.7)
# Now select 50 % rows from df1
df1.sample(frac =.50)Python3
# Dataframe df has only 4 rows
# if we try to select more than 4 row then will come error
# Cannot take a larger sample than population when 'replace = False'
df1.sample(n = 3, replace = False)Python3
# Select more than rows with using replace
# default it is False
df1.sample(n = 6, replace = True)Python3
# Weights will be re-normalized automatically
test_weights = [0.2, 0.2, 0.2, 0.4]
df1.sample(n = 3, weights = test_weights)Python3
# Accepts axis number or name.
# sample also allows users to sample columns
# instead of rows using the axis argument.
df1.sample(axis = 0)Python3
# With a given seed, the sample will always draw the same rows.
# If random_state is None or np.random,
# then a randomly-initialized
# RandomState object is returned.
df1.sample(n = 2, random_state = 2)Python3
# Import pandas & Numpy package
import numpy as np
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Choose how many index include for random selection
chosen_idx = np.random.choice(4, replace = True, size = 6)
df2 = df.iloc[chosen_idx]
df2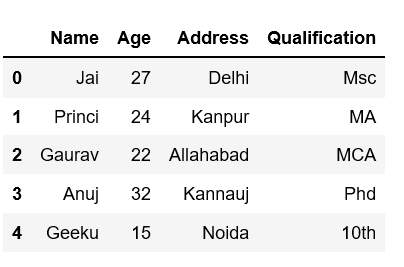
方法 #1:使用sample()方法
Sample method returns a random sample of items from an axis of object and this object of same type as your caller.
示例 1:
Python3
# Selects one row randomly using sample()
# without give any parameters.
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Select one row randomly using sample()
# without give any parameters
df.sample()
输出:

示例 2:使用参数n ,它随机选择n行。
使用 sample(n) 或 sample(n=n) 随机选择n行。每次你运行这个,你会得到 n 不同的行。
Python3
# To get 3 random rows
# each time it gives 3 different rows
# df.sample(3) or
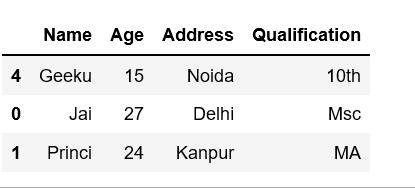
df.sample(n = 3)
输出:
示例 3:使用 frac 参数。
一个人可以做部分轴项目并获得行。例如,如果 frac= .5 则 sample 方法返回 50% 的行。
Python3
# Fraction of rows
# here you get .50 % of the rows
df.sample(frac = 0.5)
输出:

示例 4:
首先选择整个df数据帧的 70% 行,然后放入另一个数据帧df1 ,然后我们从df1中选择 50% frac 。
Python3
# fraction of rows
# here you get 70 % row from the df
# make put into another dataframe df1
df1 = df.sample(frac =.7)
# Now select 50 % rows from df1
df1.sample(frac =.50)
输出:
示例 5:使用 replace = false 随机选择一些行
参数替换允许多次选择一行(如)。 sample() 方法的 replace 参数的默认值为 False,因此您永远不会选择超过总行数。
Python3
# Dataframe df has only 4 rows
# if we try to select more than 4 row then will come error
# Cannot take a larger sample than population when 'replace = False'
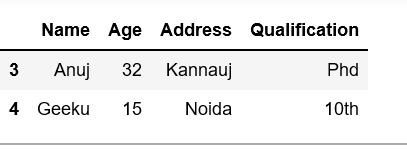
df1.sample(n = 3, replace = False)
输出:
示例 6:在替换的帮助下选择多于n行,其中n是总行数。
Python3
# Select more than rows with using replace
# default it is False
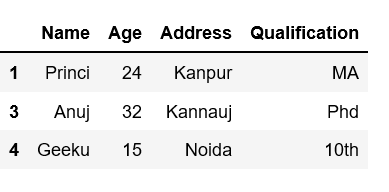
df1.sample(n = 6, replace = True)
输出:
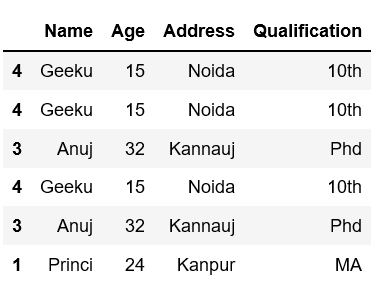
示例 7:使用权重
Python3
# Weights will be re-normalized automatically
test_weights = [0.2, 0.2, 0.2, 0.4]
df1.sample(n = 3, weights = test_weights)
输出:

示例 8:使用轴
轴接受数字或名称。 sample() 方法还允许用户使用轴参数对列而不是行进行采样。
Python3
# Accepts axis number or name.
# sample also allows users to sample columns
# instead of rows using the axis argument.
df1.sample(axis = 0)
输出:

示例 9:使用 random_state
对于给定的 DataFrame,样本将始终获取相同的行。如果 random_state 为 None 或 np.random,则返回一个随机初始化的 RandomState 对象。
Python3
# With a given seed, the sample will always draw the same rows.
# If random_state is None or np.random,
# then a randomly-initialized
# RandomState object is returned.
df1.sample(n = 2, random_state = 2)
输出:

方法 #2:使用 NumPy
Numpy 选择包含多少索引以进行随机选择,我们可以允许替换。
Python3
# Import pandas & Numpy package
import numpy as np
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj', 'Geeku'],
'Age':[27, 24, 22, 32, 15],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj', 'Noida'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd', '10th']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Choose how many index include for random selection
chosen_idx = np.random.choice(4, replace = True, size = 6)
df2 = df.iloc[chosen_idx]
df2
输出:
