从 Pandas DataFrame 中随机选择列
在本文中,我们将讨论如何从 Pandas Dataframe 中随机选择列。
根据我们的要求,我们可以从 pandas 数据库方法中随机选择列,其中 pandas df.sample() 方法帮助我们随机选择行和列。
pandas sample() 方法的语法:
从对象的轴返回随机选择的元素。为了可重复性,您可以使用 random_state 参数。
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
Parameters:
- n: int value, Number of random rows to generate.
- frac: Float value, Returns (float value * length of data frame values ). frac cannot be used with n.
- replace: Boolean value, return sample with replacement if True.
- random_state: int value or numpy.random.RandomState, optional. if set to a particular integer, will return same rows as sample in every iteration.
- axis: 0 or ‘row’ for Rows and 1 or ‘column’ for Columns.
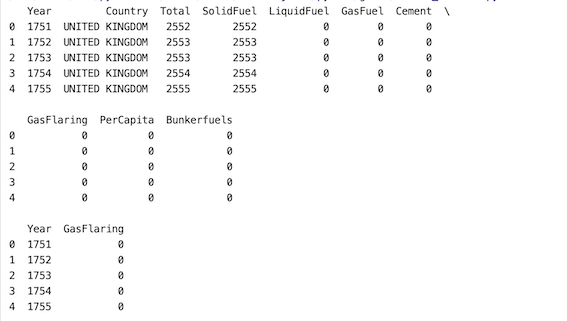
方法一:随机选择一列
在这种方法中,首先读取 Pandas 包,使用 pd.read_csv() 方法导入给定的 CSV 文件用于读取数据集。 df.sample() 方法用于随机选择行和列。 axis =' columns' 表示我们正在选择列。当未指定“n”时,该方法默认返回一个随机列。
要下载 CSV 文件,请单击此处
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
# randomly selecting columns
df = df.sample(axis='columns')
print(df)Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns')
print(df.head())Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns',replace='True')
print(df.head())Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(frac=0.25, axis='columns')
print(df.head())输出:
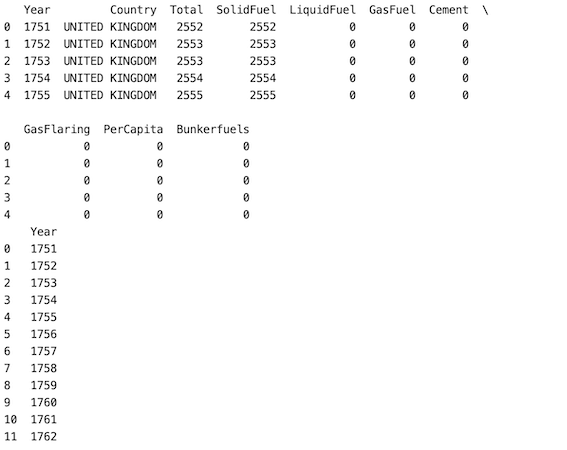
方法二:随机选择多列
在这种方法中,如果用户想要选择超过 1 的特定数量的列,我们为此使用参数“n”。在下面的示例中,我们将 n 设为 5。从数据库中随机选择 5 列。
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns')
print(df.head())
输出:
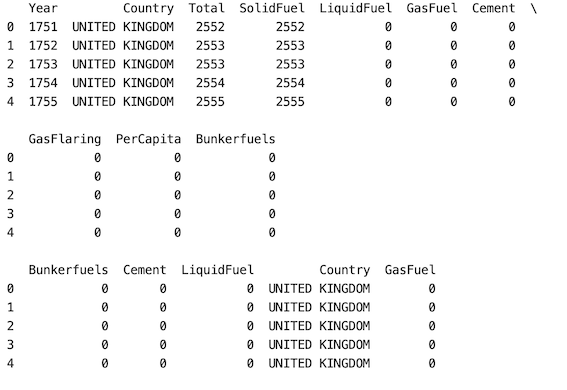
方法3:允许多次随机选择同一列(通过设置replace=True)
在这里,在这种方法中,如果用户想要多次选择一列,或者如果我们的选择需要可重复性,我们应该在 df.sample() 方法中将替换参数设置为“True”。 'Bunkerfields' 列重复了两次。
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns',replace='True')
print(df.head())
输出:
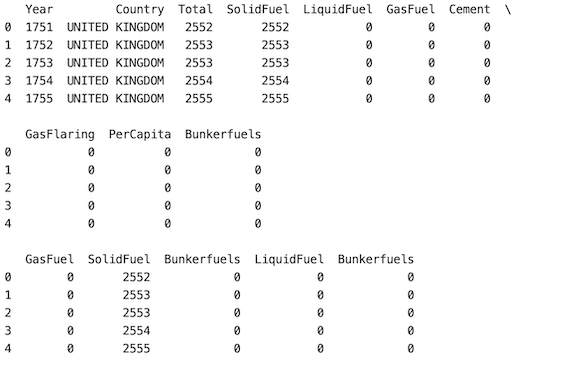
方法四:随机选择总列数的一部分:
在这种方法中,如果用户想要选择数据集的一部分,则应使用 frac 参数。在下面的示例中,我们的数据集有 10 列。 10 的 0.25 是 2.5,进一步四舍五入为 2。返回一年和 GasFlaring 列。
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(frac=0.25, axis='columns')
print(df.head())
输出: