用 R DataFrame 中的列均值替换缺失值
在本文中,我们将看到如何在 R 编程语言中用列均值替换缺失值。数据集中的缺失值通常表示为NaN或NA 。这些值必须用另一个值替换或删除。这种替换另一个值代替缺失数据的过程称为数据插补。
创建具有缺失值的数据框:
R
# creating a dataframe
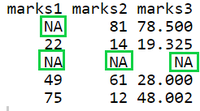
data <- data.frame(marks1 = c(NA, 22, NA, 49, 75),
marks2 = c(81, 14, NA, 61, 12),
marks3 = c(78.5, 19.325, NA, 28, 48.002))
dataR
# compute each column's mean using mean() function
m <- c()
for(i in colnames(data)){
# compute mean for all columns
mean_value <- mean(data[,i],na.rm = TRUE)
m <- append(m,mean_value)
}
# adding column names to matrix
a <- matrix(m,nrow=1)
colnames(a) <- colnames(data)
aR
# replacing NA with each column's mean
for(i in colnames(data))
data[,i][is.na(data[,i])] <- a[,i]
dataR
# imputing mean for 1st column of dataframe
data[,"marks1"][is.na(data[,"marks1"])] <- a[,"marks1"]
dataR
# using colMeans()
mean_val <- colMeans(data,na.rm = TRUE)
# replacing NA with mean value of each column
for(i in colnames(data))
data[,i][is.na(data[,i])] <- mean_val[i]
dataR
# computing mean of all columns using apply()
all_column_mean <- apply(data, 2, mean, na.rm=TRUE)
# imputing NA with the mean calculated
for(i in colnames(data))
data[,i][is.na(data[,i])] <- all_column_mean[i]
data输出:
方法 1:使用 mean()函数替换列
让我们看看如何使用数据框和 mean()函数用每列的均值来估算缺失值。 mean()函数用于计算作为参数传递给它的数字向量元素的算术平均值。
Syntax of mean() : mean(x, trim = 0, na.rm = FALSE, …)
Arguments:
- x – any object
- trim – observations to be trimmed from each end of x before the mean is computed
- na.rm – FALSE to remove NA values
示例 1:使用mean()函数替换所有列的 NA
电阻
# compute each column's mean using mean() function
m <- c()
for(i in colnames(data)){
# compute mean for all columns
mean_value <- mean(data[,i],na.rm = TRUE)
m <- append(m,mean_value)
}
# adding column names to matrix
a <- matrix(m,nrow=1)
colnames(a) <- colnames(data)
a
输出:
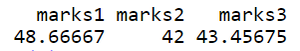
示例 2:使用 for-Loop 替换所有列中的缺失数据
电阻
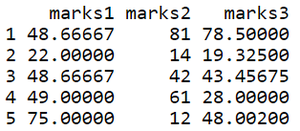
# replacing NA with each column's mean
for(i in colnames(data))
data[,i][is.na(data[,i])] <- a[,i]
data
输出:
示例 3 :为一列替换 NA。
让我们计算第一列的平均值,即marks1
电阻
# imputing mean for 1st column of dataframe
data[,"marks1"][is.na(data[,"marks1"])] <- a[,"marks1"]
data
输出:

方法 2:使用 colMeans()函数替换列
colMeans()函数用于计算矩阵或数组的每一列的均值
Syntax of colMeans() : colMeans(x, na.rm = FALSE, dims = 1 …)
Arguments:
- x: object
- dims: dimensions are regarded as ‘columns’ to sum over
- na.rm: TRUE to ignore NA values
这里我们将使用 colMeans函数来替换列中的 NA。
电阻
# using colMeans()
mean_val <- colMeans(data,na.rm = TRUE)
# replacing NA with mean value of each column
for(i in colnames(data))
data[,i][is.na(data[,i])] <- mean_val[i]
data
输出:

方法 3:使用apply()函数替换 NA
在此方法中,我们将使用 apply()函数来替换列中的 NA。
Syntax of apply() : apply(X, MARGIN, FUN, …)
Arguments:
- X – an array, including a matrix
- MARGIN – a vector
- FUN – the function to be applied
代码:
电阻
# computing mean of all columns using apply()
all_column_mean <- apply(data, 2, mean, na.rm=TRUE)
# imputing NA with the mean calculated
for(i in colnames(data))
data[,i][is.na(data[,i])] <- all_column_mean[i]
data
输出:
