使用 KNN 和 KDTree 进行信息检索的介绍指南
什么是信息检索(IR)?
它可以定义为一种软件程序,用于从大型集合(通常存储在计算机上)中查找满足信息需求的非结构化性质(通常是文本)的材料(通常文档)。它可以帮助用户找到他们所需的信息,但不会明确返回他们问题的答案。它提供有关可能包含所需信息的文档的存在和位置的信息。
信息检索用例
信息检索可用于许多场景,其中一些是:
- 网络搜索
- 电子邮件搜索
- 搜索您的笔记本电脑
- 法律信息检索等
信息检索过程

要了解有关信息检索的更多信息,您可以参考这篇文章。
在这里,我们将讨论用于信息检索的两种算法:
- K-最近邻(KNN)
- K维树(KDTree)
K-最近邻 (KNN)
它是一种有监督的机器学习分类算法。分类提供有关某物属于哪个组的信息,例如,肿瘤类型、一个人最喜欢的运动等。 KNN 中的 K代表分类器将用于进行预测的最近邻居的数量。
我们有可以预测查询数据的训练数据。对于需要分类的查询记录,KNN 算法计算查询记录与所有训练数据记录之间的距离。然后它查看训练数据中最近的 K 个数据记录。
如何选择K值?
在选择 K 值时,请记住以下几点:
- 如果 K=1 ,则将类划分为区域,查询记录根据其所在的区域属于一个类。
- 为 2 类问题选择 K 的奇数值。
- K不能是类数的倍数。K 不等于 'ni',其中 n 是类数,i = 1, 2, 3 ...。
距离度量:可以使用的不同距离度量是:
- 欧几里得距离
- 曼哈顿距离
- 汉明距离
- 闵可夫斯基距离
- 切比雪夫距离
让我们通过一个例子来详细了解 KNN 算法是如何工作的。下面给出的是一个小数据集,用于预测人们在必胜客和多米诺骨牌之外更喜欢哪个比萨店。NAME AGE CHEESE CONTENT PIZZA OUTLET Riya 30 6.2 Pizza Hut Manish 15 8 Dominos Rachel 42 4 Pizza Hut Rahul 20 8.4 Pizza Hut Varun 54 3.3 Dominos Mark 47 5 Pizza Hut Sakshi 27 9 Dominos David 17 7 Dominos Arpita 8 9.2 Pizza Hut Ananya 35 7.6 Dominos
出口是根据人的年龄和奶酪含量选择的 这个人喜欢吗(10 级)。
这些数据可以用图形表示为:

注意:如果我们有离散数据,我们首先必须将其转换为数值数据。例如:性别是男性和女性,我们可以将其转换为数字 0 和 1。
- 由于我们有2 个类——必胜客和多米诺骨牌,我们将取K=3 。
- 我们使用欧几里得距离来计算距离——

预测:根据以上数据我们需要找出查询的结果:NAME AGE CHEESE CONTENT PIZZA OUTLET Harry 46 7 ???
- 现在找出记录 Harry 到所有其他记录的距离。
下面给出了从 Harry 到 Riya 的距离的计算:

同样,所有记录的距离是:NAME PIZZA OUTLET DISTANCE Riya Pizza Hut 16.01 Manish Dominos 31.01 Rachel Pizza Hut 5 Rahul Pizza Hut 26.03 Varun Dominos 8.81 Mark Pizza Hut 2.23 Sakshi Dominos 19.10 David Dominos 29 Arpita Pizza Hut 38.06 Ananya Dominos 11.01
从表中我们可以看出,距离 K(3) 最近的距离是Mark 、 Rachel和Varun ,他们更喜欢的Pizza Outlet分别是 Pizza Hut、Pizza Hut和Dominos 。因此,我们可以做出Harry 更喜欢 Pizza Hut的预测。
使用 KNN 算法的优点:
- 无训练阶段
- 它可以轻松学习复杂的模型
- 它对嘈杂的训练数据具有鲁棒性
使用 KNN 算法的缺点:
- 确定参数 K 的值可能很困难,因为不同的 K 值会给出不同的结果。
- 很难应用于高维数据
- 计算成本很高,因为对于每个查询,它必须遍历所有花费 O(N) 时间的记录,其中 N 是记录数。如果我们维护一个优先级队列来返回最近的 K 条记录,那么时间复杂度将为 O(log(K)*N)。
由于计算成本高,我们使用了一种时间效率高且方法相似的算法——KDTree 算法。
K维树(KDTree)
KDTree 是一种空间分区数据结构,用于在 K 维空间中组织点。它是对 KNN 的改进。它对于有效地表示数据很有用。在 KDTree 中,数据点是根据一些特定条件进行组织和分区的。
算法的工作原理:
为了理解这一点,让我们以我们在前面的例子中考虑的 Pizza Outlet 的样本数据为例。基本上,我们进行一些轴对齐切割并创建不同的区域,保持位于这些区域中的点的轨迹。每个区域由树中的一个节点表示。
- 在观测值的平均值处分割区域。
对于第一次切割,我们将找到所有 X 坐标(在本例中为奶酪含量)的平均值。

现在在这两个区域上,我们将计算 Y 坐标的平均值以进行切割等,重复这些步骤直到每个区域中的点数小于给定的数量。您可以选择小于数据集中记录数的任意数字,否则我们将只有 1 个区域。完整的树结构将是:

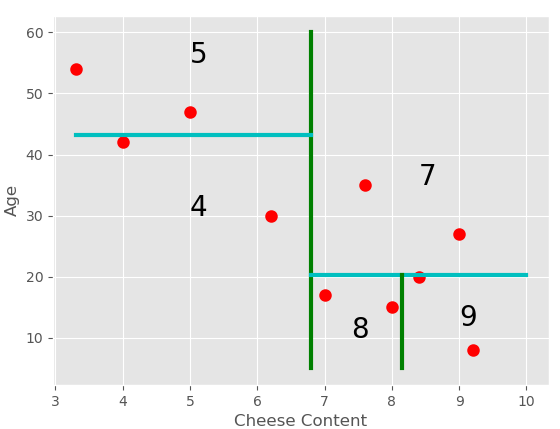
这里每个区域少于3个点。
现在如果有新的查询点出现,我们需要找出该点将在哪个区域,我们可以遍历树。在这种情况下,查询点(随机选择)位于第 4 个区域。

我们可以发现它是这个区域中最近的邻居。

但这可能不是整个数据集中此查询的实际最近邻。因此,我们遍历回节点 2,然后检查该节点的剩余子树。

我们得到节点 5 的最紧密框,其中包含该区域中的所有点。之后,我们检查这个框的距离是否比当前最近的邻居更接近查询点。

在这种情况下,盒子的距离更小。因此,区域点中有一个点比当前最近的邻居更接近查询点。我们找到那个点,然后我们再次遍历树到节点 3 并检查它。
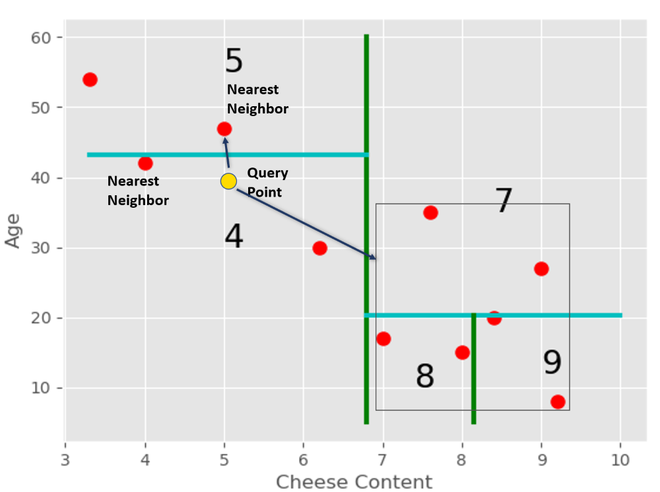
现在距离大于与新的最近邻居的距离。因此,我们到此为止,我们不需要搜索这个子树。我们可以修剪树的这一部分。
注意:只有在找到 K 个点并且该分支的点不能比 K 个当前最佳点中的任何一个点更近时,才会消除树的一个分支。
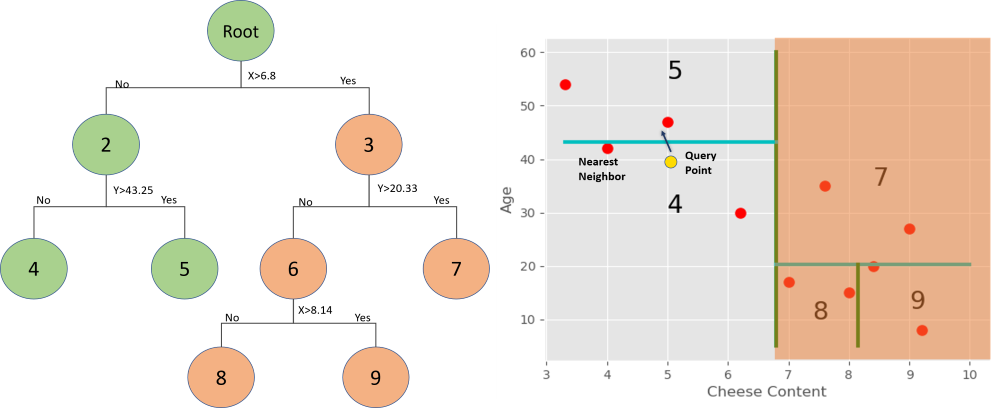
KDtree 实现:
我们将执行文档检索,这是信息检索最广泛使用的用例。为此,我们制作了一个示例数据集,其中包含互联网上有关名人的文章。输入姓名后,您会得到与给定姓名相似的名人姓名。这里K 值取为 3 。我们将获得输入的文档名称的三个最近邻。
您可以从这里获取数据集。
代码:
#import the libraries required
import numpy as np
import pandas as pd
import nltk
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.neighbors import KDTree
#Reading the dataset
person = pd.read_csv('famous_people.csv')
#Printing first five rows of the dataset
print(person.head())
输出:

代码:
#Counting the frequency of occurance of each word
count_vector = CountVectorizer()
train_counts = count_vector.fit_transform(person.Text)
#Using tf-idf to reduce the weight of common words
tfidf_transform = TfidfTransformer()
train_tfidf = tfidf_transform.fit_transform(train_counts)
a = np.array(train_tfidf.toarray())
#obtaining the KDTree
kdtree = KDTree(a ,leaf_size=3)
#take the name of the personality as input
person_name=input("Enter the name of the Person:- ")
#Using KDTree to get K articles similar to the given name
person['tfidf']=list(train_tfidf.toarray())
distance, idx = kdtree.query(person['tfidf'][person['Name']== person_name].tolist(), k=3)
for i, value in list(enumerate(idx[0])):
print("Name : {}".format(person['Name'][value]))
print("Distance : {}".format(distance[0][i]))
print("URI : {}".format(person['URI'][value]))
输出:
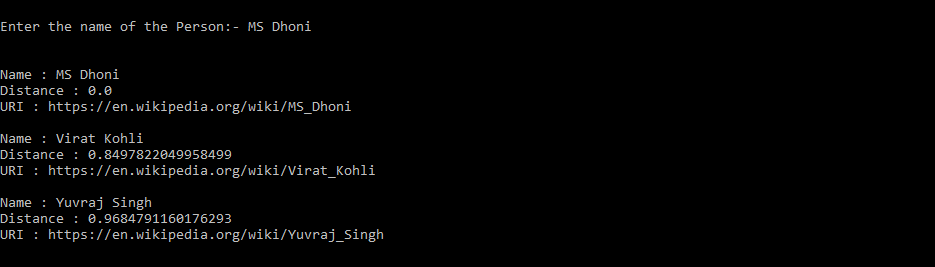
我们得到MS Dhoni 、 Virat Kohli和Yuvraj Singh作为 MS Dhoni的 3 个最近邻居。
使用 KDTree 的优点
- 在树的每一层,KDTree 将域的范围分成两半。因此它们对于执行范围搜索很有用。
- 如前所述,它是 KNN 的改进。
- 复杂度介于 O(log N) 到 O(N) 之间,其中 N 是树中的节点数。
使用 KDTree 的缺点
- 使用高维数据时性能下降。算法将需要访问更多分支。如果数据集的维数为K,则节点数N>>(2^K)。
- 如果查询点远离数据集中的所有点,那么我们可能必须遍历整棵树以找到最近的邻居。
如有任何疑问,请在下面发表评论。