- 模糊逻辑-控制系统(1)
- 模糊逻辑控制系统(1)
- 模糊逻辑教程
- 模糊逻辑教程(1)
- 模糊逻辑-应用
- 模糊逻辑-应用(1)
- 模糊逻辑-简介(1)
- 模糊逻辑-简介
- 讨论模糊逻辑(1)
- 讨论模糊逻辑
- 模糊逻辑|介绍(1)
- 模糊逻辑 |介绍(1)
- 模糊逻辑|介绍
- 模糊逻辑 |介绍
- 模糊逻辑-数据库和查询
- 模糊逻辑-数据库和查询(1)
- 模糊逻辑-决策
- 模糊逻辑-决策(1)
- 模糊逻辑-有用的资源(1)
- 模糊逻辑-有用的资源
- 神经网络与模糊逻辑的区别
- 神经网络与模糊逻辑的区别(1)
- 版本控制系统
- 版本控制系统(1)
- 模糊逻辑-量化(1)
- 模糊逻辑-量化
- 控制系统教程(1)
- 控制系统教程
- 控制系统-简介(1)
📅 最后修改于: 2020-11-24 06:20:05 🧑 作者: Mango
模糊逻辑在各种控制应用中取得了巨大的成功。几乎所有的消费产品都具有模糊控制。其中的一些示例包括借助空调来控制室温,用于车辆的防抱死系统,对交通信号灯,洗衣机,大型经济系统等进行控制。
为什么在控制系统中使用模糊逻辑
控制系统是一种物理组件的布置,旨在改变另一个物理系统,以使该系统具有某些所需的特性。以下是在控制系统中使用模糊逻辑的一些原因-
-
在应用传统控制时,需要了解精确定义的模型和目标函数。这使得在很多情况下很难应用。
-
通过将模糊逻辑应用于控制,我们可以利用人类的专业知识和经验来设计控制器。
-
模糊控制规则(基本上是IF-THEN规则)可以在设计控制器时得到最佳利用。
模糊逻辑控制(FLC)设计中的假设
在设计模糊控制系统时,应做出以下六个基本假设:
-
工厂是可观察和可控制的-必须假定输入,输出以及状态变量可用于观察和控制目的。
-
知识主体的存在-必须假定存在一个具有语言规则的知识主体和一组可从中提取规则的输入输出数据集。
-
解决方案的存在-必须假定存在解决方案。
-
“足够好”的解决方案就足够了-控制工程必须寻找“足够好”的解决方案,而不是最佳解决方案。
-
精度范围-模糊逻辑控制器的设计必须在可接受的精度范围内。
-
关于稳定性和最优性的问题-稳定性和最优性的问题必须在设计模糊逻辑控制器时公开,而不是明确解决。
模糊逻辑控制架构
下图显示了模糊逻辑控制(FLC)的体系结构。
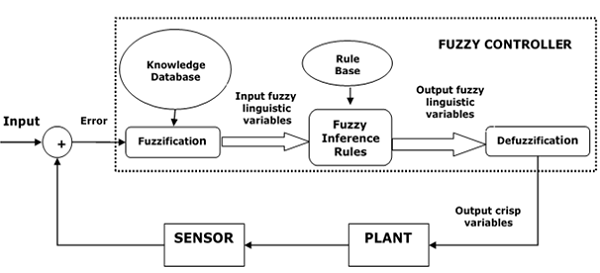
FLC的主要组成部分
以下是FLC的主要组成部分,如上图所示-
-
模糊器–模糊器的作用是将清晰的输入值转换为模糊值。
-
模糊知识库-它存储有关所有输入输出模糊关系的知识。它还具有隶属函数,该函数定义了模糊规则库的输入变量和控制下的工厂的输出变量。
-
模糊规则库-它存储有关域过程操作的知识。
-
推理引擎-它充当任何FLC的内核。基本上,它通过执行近似推理来模拟人类的决策。
-
反模糊器-反模糊器的作用是将模糊值转换为从模糊推理引擎得到的清晰值。
设计FLC的步骤
以下是设计FLC涉及的步骤-
-
变量的识别-在这里,必须识别正在考虑中的工厂的输入,输出和状态变量。
-
模糊子集配置-信息范围分为多个模糊子集,每个子集都分配有一个语言标签。始终确保这些模糊子集包含Universe的所有元素。
-
获得隶属度函数-现在获得在上述步骤中获得的每个模糊子集的隶属度函数。
-
模糊规则库配置-现在通过分配模糊输入和输出之间的关系来制定模糊规则库。
-
模糊化-在此步骤中开始模糊化过程。
-
合并模糊输出-通过应用模糊近似推理,定位模糊输出并将其合并。
-
去模糊化-最后,启动去模糊化过程以形成清晰的输出。
模糊逻辑控制的优点
现在让我们讨论模糊逻辑控制的优点。
-
更便宜-在性能方面,开发FLC比开发基于模型的控制器或其他控制器要便宜。
-
鲁棒性-FLC比PID控制器更鲁棒,因为它们能够覆盖很大范围的工作条件。
-
可定制的-FLC是可定制的。
-
模拟人的演绎思维-基本上,FLC旨在模拟人的演绎思维,人们用来从其所知中推断结论的过程。
-
可靠性-FLC比常规控制系统更可靠。
-
效率-在控制系统中应用时,模糊逻辑可提供更高的效率。
模糊逻辑控制的缺点
现在我们将讨论模糊逻辑控制的缺点。
-
需要大量数据-FLC需要大量数据。
-
在中等历史数据的情况下有用-FLC对于比历史数据小得多或大得多的程序无用。
-
需要高水平的人类专业知识-这是一个缺点,因为系统的准确性取决于人类的知识和专业知识。
-
需要定期更新规则-规则必须随时间更新。