- 回归与分类 (1)
- 回归与分类 - 无论代码示例
- 在Python中解决线性回归
- R 编程中分类变量的回归
- R 编程中分类变量的回归(1)
- ML |分类与回归
- ML |分类与回归(1)
- 毫升 |分类与回归
- TensorFlow中的线性回归(1)
- TensorFlow-线性回归(1)
- TensorFlow中的线性回归
- TensorFlow-线性回归
- 机器学习中的回归与分类
- TensorFlow中神经网络的分类
- TensorFlow中神经网络的分类(1)
- 胺的分类
- R分类(1)
- 桶分类
- R分类
- 桶分类(1)
- 分类算法-Logistic回归(1)
- 分类算法-Logistic回归
- 回归python(1)
- 使用Tensorflow进行线性回归(1)
- 使用Tensorflow进行线性回归
- 使用Tensorflow进行线性回归
- javascript中的循环问题解决(1)
- 分类算法的分类
- 分类算法的分类(1)
📅 最后修改于: 2020-09-01 05:57:48 🧑 作者: Mango
经过大肆宣传,Google最终发布了TensorFlow 2.0,它是Google旗舰深度学习平台的最新版本。TensorFlow 2.0中引入了许多期待已久的功能。本文非常简短地介绍了如何使用TensorFlow 2.0开发简单的分类和回归模型。
使用Tensorflow 2.0进行分类
如果您曾经与Keras库一起工作过,那一定会很愉快。TensorFlow 2.0现在使用Keras API作为训练分类和回归模型的默认库。在TensorFlow 2.0之前,TensorFlow的早期版本必须面对的主要批评之一是由于模型创建的复杂性。以前,您需要将图形,会话和占位符缝合在一起才能创建甚至简单的逻辑回归模型。使用TensorFlow 2.0,创建分类和回归模型已成为小菜一碟。
因此,事不宜迟,让我们使用TensorFlow开发分类模型。
数据集
可以从此链接免费下载分类示例的数据集。以CSV格式下载文件。如果打开下载的CSV文件,则会看到该文件不包含任何标题。列的详细信息可从UCI机器学习存储库中获得。我建议您从下载链接中详细阅读数据集信息。我将在本节中简要总结数据集。
数据集基本上由7列组成:
- price (the buying price of the car)
- maint ( the maintenance cost)
- doors (number of doors)
- persons (the seating capacity)
- lug_capacity (the luggage capacity)
- safety (how safe is the car)
- output (the condition of the car)
给定前6列,任务是预测第7列的值,即输出。输出列可以具有三个值之一,即“ unacc”(不可接受),“ acc”(可接受),好和非常好。
导入库
在将数据集导入到应用程序之前,我们需要导入所需的库。
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style="darkgrid")
在我们继续之前,我希望您确保您具有TensorFlow的最新版本,即TensorFlow 2.0。您可以使用以下命令检查TensorFlow版本:
print(tf.__version__)如果您尚未安装TensorFlow 2.0,则可以通过以下命令升级到最新版本:
$ pip install --upgrade tensorflow导入数据集
以下脚本导入数据集。根据更改您的CSV数据文件的路径。
cols = ['price', 'maint', 'doors', 'persons', 'lug_capacity', 'safety','output']
cars = pd.read_csv(r'/content/drive/My Drive/datasets/car_dataset.csv', names=cols, header=None)由于CSV文件默认情况下不包含列标题,因此我们将列标题列表传递给该pd.read_csv()方法。
现在让我们通过head()方法查看数据集的前5行。
cars.head()输出:

您可以在数据集中看到7列。
数据分析和预处理
让我们通过绘制一个饼图来简要分析数据集,该饼图显示输出的分布。以下脚本增加了默认图的大小。
plot_size = plt.rcParams["figure.figsize"]
plot_size [0] = 8
plot_size [1] = 6
plt.rcParams["figure.figsize"] = plot_size下面的脚本绘制显示输出分布的饼图。
cars.output.value_counts().plot(kind='pie', autopct='%0.05f%%', colors=['lightblue', 'lightgreen', 'orange', 'pink'], explode=(0.05, 0.05, 0.05,0.05))输出:
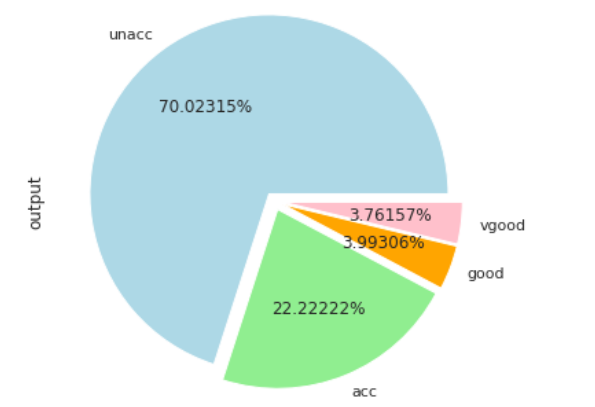
输出结果显示,大多数汽车(70%)处于不可接受的状态,而20%的汽车处于可接受的状态。处于良好和非常良好状态的汽车比例非常低。
我们数据集中的所有列都是分类的。深度学习基于统计算法,统计算法与数字一起工作。因此,我们需要将分类信息转换为数字列。有多种方法可以做到这一点,但是最常见的方法之一是单热编码。在一次性编码中,对于分类列中的每个唯一值,将创建一个新列。对于存在唯一值的实际列中的行,将1添加到为该特定值创建的列的相应行中。这听起来可能很复杂,但是下面的示例将使其变得清晰。
以下脚本将分类列转换为数字列:
price = pd.get_dummies(cars.price, prefix='price')
maint = pd.get_dummies(cars.maint, prefix='maint')
doors = pd.get_dummies(cars.doors, prefix='doors')
persons = pd.get_dummies(cars.persons, prefix='persons')
lug_capacity = pd.get_dummies(cars.lug_capacity, prefix='lug_capacity')
safety = pd.get_dummies(cars.safety, prefix='safety')
labels = pd.get_dummies(cars.output, prefix='condition')要创建功能集,我们可以水平合并前六列:
X = pd.concat([price, maint, doors, persons, lug_capacity, safety] , axis=1)让我们看看标签列现在的样子:
labels.head()输出:

标签列基本上是我们在数据集中拥有的输出列的一键编码版本。输出列具有四个唯一值:unacc,acc,good和非常好。在一键编码标签数据集中,您可以看到四列,其中一列对应输出列中的每个唯一值。您可以在该列中看到1,以了解该行中最初存在的唯一值。例如,在输出列的前五行中,该列的值为unacc。在标签列中,您可以在condition_unacc列的前五行中看到1。
现在让我们将标签转换成numpy数组,因为TensorFlow中的深度学习模型接受numpy数组作为输入。
y = labels.values我们可以训练TensorFlow 2.0分类模型的最后一步是将数据集分为训练集和测试集:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)模型训练
要训练模型,让我们导入TensorFlow 2.0类。执行以下脚本:
from tensorflow.keras.layers import Input, Dense, Activation,Dropout
from tensorflow.keras.models import Model就像我之前说的那样,TensorFlow 2.0使用Keras API训练模型。在上面的脚本我们基本上导入Input,Dense,Activation,并Dropout从课程tensorflow.keras.layers模块。同样,我们也是来自模块import的Model类tensorflow.keras.models。
下一步是创建我们的分类模型:
input_layer = Input(shape=(X.shape[1],))
dense_layer_1 = Dense(15, activation='relu')(input_layer)
dense_layer_2 = Dense(10, activation='relu')(dense_layer_1)
output = Dense(y.shape[1], activation='softmax')(dense_layer_2)
model = Model(inputs=input_layer, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])从脚本可以看出,该模型包含三个密集层。前两个密集层包含15个和10个具有relu激活功能的节点。最终的密集层包含4个节点(y.shape[1] == 4)和softmax激活函数,因为这是分类任务。使用categorical_crossentropy损失函数和adam优化器训练模型。评估指标是准确性。
以下脚本显示了模型摘要:
print(model.summary())输出:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 21)] 0
_________________________________________________________________
dense (Dense) (None, 15) 330
_________________________________________________________________
dense_1 (Dense) (None, 10) 160
_________________________________________________________________
dense_2 (Dense) (None, 4) 44
=================================================================
Total params: 534
Trainable params: 534
Non-trainable params: 0
_________________________________________________________________
None最后,要训练模型,请执行以下脚本:
history = model.fit(X_train, y_train, batch_size=8, epochs=50, verbose=1, validation_split=0.2)该模型将训练50个纪元,但为了节省空间,此处仅显示最后5个纪元的结果:
Epoch 45/50
1105/1105 [==============================] - 0s 219us/sample - loss: 0.0114 - acc: 1.0000 - val_loss: 0.0606 - val_acc: 0.9856
Epoch 46/50
1105/1105 [==============================] - 0s 212us/sample - loss: 0.0113 - acc: 1.0000 - val_loss: 0.0497 - val_acc: 0.9856
Epoch 47/50
1105/1105 [==============================] - 0s 219us/sample - loss: 0.0102 - acc: 1.0000 - val_loss: 0.0517 - val_acc: 0.9856
Epoch 48/50
1105/1105 [==============================] - 0s 218us/sample - loss: 0.0091 - acc: 1.0000 - val_loss: 0.0536 - val_acc: 0.9856
Epoch 49/50
1105/1105 [==============================] - 0s 213us/sample - loss: 0.0095 - acc: 1.0000 - val_loss: 0.0513 - val_acc: 0.9819
Epoch 50/50
1105/1105 [==============================] - 0s 209us/sample - loss: 0.0080 - acc: 1.0000 - val_loss: 0.0536 - val_acc: 0.9856到第50个纪元末,我们的训练准确性为100%,而验证准确性为98.56%,这令人印象深刻。
最后,让我们评估测试集上分类模型的性能:
score = model.evaluate(X_test, y_test, verbose=1)
print("Test Score:", score[0])
print("Test Accuracy:", score[1])这是输出:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: ,
346/346 [==============================] - 0s 55us/sample - loss: 0.0605 - acc: 0.9740
Test Score: 0.06045335989359314
Test Accuracy: 0.9739884 我们的模型在测试集上的准确性达到97.39%。尽管它略低于100%的训练精度,但考虑到我们随机选择层数和节点数的事实,它仍然非常好。您可以在具有更多节点的模型中添加更多层,并查看是否可以在验证和测试集上获得更好的结果。
使用TensorFlow 2.0进行回归
在回归问题中,目标是预测连续值。在本部分中,您将看到如何使用TensorFlow 2.0解决回归问题
数据集
可以从此链接免费下载该问题的数据集,需要科学上网。。下载CSV文件。
以下脚本导入数据集。不要忘记将路径更改为自己的CSV数据文件。
petrol_cons = pd.read_csv(r'/content/drive/My Drive/datasets/petrol_consumption.csv')让我们通过head()函数打印数据集的前五行:
petrol_cons.head()输出:

您可以看到数据集中有五列。回归模型将在前四列进行训练,即Petrol_tax,Average_income,Paved_Highways和Population_Driver_License(%)。将预测最后一列的值,即Petrol_Consumption。如您所见,输出列没有离散值,而预测值可以是任何连续值。
数据预处理
在数据预处理步骤中,我们将简单地将数据分为特征和标签,然后将数据分为测试集和训练集。最后,数据将被标准化。对于一般的回归问题以及深度学习的回归问题,强烈建议您对数据集进行标准化。最后,由于所有列都是数字,因此在这里我们不需要对列执行一键编码。
X = petrol_cons.iloc[:, 0:4].values
y = petrol_cons.iloc[:, 4].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)在以上脚本中,在功能集中X,包含了数据集的前四列。在标签集中y,仅包含第5列。接下来,通过模块的train_test_split方法将数据集分为训练量和测试量sklearn.model_selection。该test_size属性的值为0.2,这意味着测试集将包含原始数据的20%,而训练集将包含原始数据集的其余80%。最后,StandardScaler来自sklearn.preprocessing模块的类用于缩放数据集。
模型训练
下一步是训练我们的模型。这个过程非常类似于训练分类。唯一的变化将是损失函数和输出密集层中节点的数量。由于现在我们正在预测单个连续值,因此输出层将只有1个节点。
input_layer = Input(shape=(X.shape[1],))
dense_layer_1 = Dense(100, activation='relu')(input_layer)
dense_layer_2 = Dense(50, activation='relu')(dense_layer_1)
dense_layer_3 = Dense(25, activation='relu')(dense_layer_2)
output = Dense(1)(dense_layer_3)
model = Model(inputs=input_layer, outputs=output)
model.compile(loss="mean_squared_error" , optimizer="adam", metrics=["mean_squared_error"])
我们的模型由四个密集层组成,分别具有100、50、25和1个节点。对于回归问题,最常用的损失函数之一是mean_squared_error。以下脚本打印模型的摘要:
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 4)] 0
_________________________________________________________________
dense_10 (Dense) (None, 100) 500
_________________________________________________________________
dense_11 (Dense) (None, 50) 5050
_________________________________________________________________
dense_12 (Dense) (None, 25) 1275
_________________________________________________________________
dense_13 (Dense) (None, 1) 26
=================================================================
Total params: 6,851
Trainable params: 6,851
Non-trainable params: 0
最后,我们可以使用以下脚本训练模型:
history = model.fit(X_train, y_train, batch_size=2, epochs=100, verbose=1, validation_split=0.2)这是最近5个训练时期的结果:
Epoch 96/100
30/30 [==============================] - 0s 2ms/sample - loss: 510.3316 - mean_squared_error: 510.3317 - val_loss: 10383.5234 - val_mean_squared_error: 10383.5234
Epoch 97/100
30/30 [==============================] - 0s 2ms/sample - loss: 523.3454 - mean_squared_error: 523.3453 - val_loss: 10488.3036 - val_mean_squared_error: 10488.3037
Epoch 98/100
30/30 [==============================] - 0s 2ms/sample - loss: 514.8281 - mean_squared_error: 514.8281 - val_loss: 10379.5087 - val_mean_squared_error: 10379.5088
Epoch 99/100
30/30 [==============================] - 0s 2ms/sample - loss: 504.0919 - mean_squared_error: 504.0919 - val_loss: 10301.3304 - val_mean_squared_error: 10301.3311
Epoch 100/100
30/30 [==============================] - 0s 2ms/sample - loss: 532.7809 - mean_squared_error: 532.7809 - val_loss: 10325.1699 - val_mean_squared_error: 10325.1709
为了评估测试集上回归模型的性能,最常用的指标之一是均方根误差。我们可以通过模块的mean_squared_error类别找到预测值和实际值之间的均方误差sklearn.metrics。然后,我们可以求出所得均方误差的平方根。看下面的脚本:
from sklearn.metrics import mean_squared_error
from math import sqrt
pred_train = model.predict(X_train)
print(np.sqrt(mean_squared_error(y_train,pred_train)))
pred = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test,pred)))输出显示了训练集和测试集的均方误差。结果表明,训练集的模型性能更好,因为训练集的均方根误差值较小。我们的模型过拟合。原因很明显,数据集中只有48条记录。尝试使用更大的数据集训练回归模型以获得更好的结果。
50.43599665058207
84.31961060849562结论
TensorFlow 2.0是用于深度学习的Google TensorFlow库的最新版本。本文简要介绍了如何使用TensorFlow 2.0创建分类和回归模型。为了获得实际经验,我建议您练习本文中给出的示例,并尝试使用TensorFlow 2.0和其他一些数据集创建简单的回归和分类模型。