📌 相关文章
- 统计-点图
- 统计-点图(1)
- 如何在 Excel 中创建点图?
- 如何在 Excel 中创建点图?(1)
- 如何在 R 中创建堆叠点图?(1)
- 如何在 R 中创建堆叠点图?
- 在控制台 C# 中绘制表格 (1)
- 在控制台 C# 中绘制表格 - 无论代码示例
- R编程中创建点图——dotchart()函数
- R编程中创建点图——dotchart()函数(1)
- 如何在自述文件中绘制表格 (1)
- 如何从 json ajax 绘制表格 - Javascript (1)
- 如何从 json ajax 绘制表格 - Javascript 代码示例
- python 绘制树 (1)
- 绘制 a 对 b - Python (1)
- 如何在自述文件中绘制表格 - 无论代码示例
- 如何使用 JavaScript 删除表格中的表格行?
- 如何使用表格来构建表格?(1)
- 如何使用表格来构建表格?
- 如何使用jQuery在表格中添加表格行?(1)
- 如何使用jQuery在表格中添加表格行?
- HTML-表格
- HTML-表格(1)
- HTML-表格
- 绘制 a 对 b - Python 代码示例
- 纯 CSS 表格(1)
- 纯 CSS 表格
- 纯 CSS 表格
- 如何在 HTML 表格中创建嵌套表格?(1)
📜 绘制-点图和表格
📅 最后修改于: 2020-11-29 07:06:12 🧑 作者: Mango
在这里,我们将学习Plotly中的点图和表格函数。首先,让我们从点图开始。
点图
点图以非常简单的比例显示点。它仅适用于少量数据,因为大量的点会使它看起来非常混乱。点图也称为克利夫兰点图。它们显示两个(或多个)时间点之间或两个(或多个)条件之间的变化。
点图类似于水平条形图。但是,它们可以减少混乱,并且可以更轻松地比较条件。该图绘制了将模式属性设置为标记的散布轨迹。
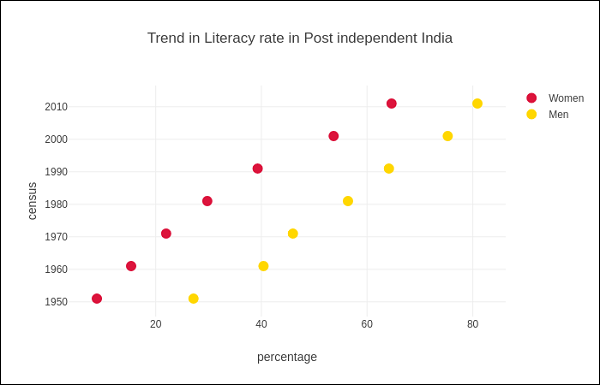
下例显示了印度独立后各次人口普查中记录的男女识字率的比较。图表中的两条痕迹代表了1951年至2011年期间每次普查中男女的识字率。
from plotly.offline import iplot, init_notebook_mode
init_notebook_mode(connected = True)
census = [1951,1961,1971,1981,1991,2001, 2011]
x1 = [8.86, 15.35, 21.97, 29.76, 39.29, 53.67, 64.63]
x2 = [27.15, 40.40, 45.96, 56.38,64.13, 75.26, 80.88]
traceA = go.Scatter(
x = x1,
y = census,
marker = dict(color = "crimson", size = 12),
mode = "markers",
name = "Women"
)
traceB = go.Scatter(
x = x2,
y = census,
marker = dict(color = "gold", size = 12),
mode = "markers",
name = "Men")
data = [traceA, traceB]
layout = go.Layout(
title = "Trend in Literacy rate in Post independent India",
xaxis_title = "percentage",
yaxis_title = "census"
)
fig = go.Figure(data = data, layout = layout)
iplot(fig)
输出将如下所示-
地表
Plotly的Table对象由go.Table()函数返回。表跟踪是一个图形对象,可用于在行和列的网格中查看详细数据。表使用的是列优先顺序,即网格表示为列向量的向量。
go.Table()函数的两个重要参数是表头(表的第一行)和形成其余行的单元格。这两个参数都是字典对象。标头的values属性是列标题的列表和列表的列表,每个列表对应于一行。
进一步的样式定制是通过linecolor,fill_color,font和其他属性完成的。
以下代码显示了最近结束的2019年板球世界杯的循环赛积分表。
trace = go.Table(
header = dict(
values = ['Teams','Mat','Won','Lost','Tied','NR','Pts','NRR'],
line_color = 'gray',
fill_color = 'lightskyblue',
align = 'left'
),
cells = dict(
values =
[
[
'India',
'Australia',
'England',
'New Zealand',
'Pakistan',
'Sri Lanka',
'South Africa',
'Bangladesh',
'West Indies',
'Afghanistan'
],
[9,9,9,9,9,9,9,9,9,9],
[7,7,6,5,5,3,3,3,2,0],
[1,2,3,3,3,4,5,5,6,9],
[0,0,0,0,0,0,0,0,0,0],
[1,0,0,1,1,2,1,1,1,0],
[15,14,12,11,11,8,7,7,5,0],
[0.809,0.868,1.152,0.175,-0.43,-0.919,-0.03,-0.41,-0.225,-1.322]
],
line_color='gray',
fill_color='lightcyan',
align='left'
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)
输出如下所示-
表数据也可以从Pandas数据框中填充。让我们创建一个逗号分隔的文件( points-table.csv ),如下所示:
| Teams | Mat | Won | Lost | Tied | NR | Pts | NRR |
|---|---|---|---|---|---|---|---|
| India | 9 | 7 | 1 | 0 | 1 | 15 | 0.809 |
| Australia | 9 | 7 | 2 | 0 | 0 | 14 | 0.868 |
| England | 9 | 6 | 3 | 0 | 0 | 14 | 1.152 |
| New Zealand | 9 | 5 | 3 | 0 | 1 | 11 | 0.175 |
| Pakistan | 9 | 5 | 3 | 0 | 1 | 11 | -0.43 |
| Sri Lanka | 9 | 3 | 4 | 0 | 2 | 8 | -0.919 |
| South Africa | 9 | 3 | 5 | 0 | 1 | 7 | -0.03 |
| Bangladesh | 9 | 3 | 5 | 0 | 1 | 7 | -0.41 |
Teams,Matches,Won,Lost,Tie,NR,Points,NRR
India,9,7,1,0,1,15,0.809
Australia,9,7,2,0,0,14,0.868
England,9,6,3,0,0,12,1.152
New Zealand,9,5,3,0,1,11,0.175
Pakistan,9,5,3,0,1,11,-0.43
Sri Lanka,9,3,4,0,2,8,-0.919
South Africa,9,3,5,0,1,7,-0.03
Bangladesh,9,3,5,0,1,7,-0.41
West Indies,9,2,6,0,1,5,-0.225
Afghanistan,9,0,9,0,0,0,-1.322
现在,我们从此csv文件构造一个dataframe对象,并使用它来构造表跟踪,如下所示-
import pandas as pd
df = pd.read_csv('point-table.csv')
trace = go.Table(
header = dict(values = list(df.columns)),
cells = dict(
values = [
df.Teams,
df.Matches,
df.Won,
df.Lost,
df.Tie,
df.NR,
df.Points,
df.NRR
]
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)