- PostgreSQL串行(1)
- PostgreSQL – 串行
- 安装串行 python (1)
- DBMS 中串行和非串行调度的计算(1)
- DBMS 中串行和非串行调度的计算(1)
- DBMS 中串行和非串行调度的计算
- DBMS 中串行和非串行调度的计算
- 安装串行 python 代码示例
- 串行开始 - C# (1)
- 串行开始 - C# 代码示例
- DBMS中串行和非串行日程表的计算(1)
- DBMS中串行和非串行日程表的计算
- postgresql 删除内容后重置串行计数器 - SQL (1)
- postgresql 删除内容后重置串行计数器 - SQL 代码示例
- 如何在颤振中添加串行新行 (1)
- PostgreSQL-锁(1)
- PostgreSQL-锁
- postgreSQL (1)
- 在 python 代码示例中发送串行命令
- 如何在颤振中添加串行新行 - 任何代码示例
- Arduino串行。print()(1)
- Arduino串行。print()
- Arduino-键盘串行
- 如何串行打印换行符 - Python (1)
- 如何串行打印换行符 - Python 代码示例
- 8085微处理器中的串行I O线(1)
- 8085微处理器中的串行I / O线
- PostgreSQL数组(1)
- PostgreSQL数组
📅 最后修改于: 2020-11-30 07:38:15 🧑 作者: Mango
PostgreSQL串行
在本节中,我们将了解PostgreSQL串行伪类型的工作原理,该模型允许我们在表中定义自动递增列。我们还看到了PostgreSQL Serial伪类型的示例。
什么是PostgreSQL串行伪类型?
在PostgreSQL中,我们有一种特殊的数据库对象生成器,称为Serial ,它用于创建一系列Integer ,这些Integer经常用作表中的主键。
在创建新表时,可以借助SERIAL伪类型生成序列,如以下命令所示:
CREATE TABLE table_name(
ID SERIAL
);
如果我们向ID列提供SERIAL伪类型,则PostgreSQL将执行以下操作:
- 首先,PostgreSQL将创建一个序列对象,然后将由序列创建的下一个值建立为特定列的预定义值。
- 之后,PostgreSQL将增强对ID列的NOT NULL约束,因为序列始终会产生一个非null值的整数。
- 最后,PostgreSQL将序列的所有者提供给ID列;作为输出,当删除表或ID列时,将删除序列对象。
注意:我们可以同时使用这两个命令来指定Serial伪类型,因为下面的命令彼此相似。
CREATE TABLE table_name(
ID SERIAL
);
CREATE SEQUENCE table_name_ID_seq;
CREATE TABLE table_name (
ID integer NOT NULL DEFAULT nextval('table_name_ID_seq')
);
ALTER SEQUENCE table_name_ID_seq
OWNED BY table_name.ID;
PostgreSQL串行伪类型已分为以下三种类型:
- 小串行
- 序列号
- 大系列
我们有下表,其中包含PostgreSQL支持的所有串行伪类型规范:
| Name | Storage Size | Range |
|---|---|---|
| SMALLSERIAL | 2 bytes | 1 to 32767 |
| SERIAL | 4 bytes | 1 to 2147483647 |
| BIGSERIAL | 8 bytes | 1 to 9223372036854775807 |
PostgreSQL串行伪类型的语法
PostgreSQL串行伪类型的语法如下:
variable_name SERIAL
PostgreSQL SERIAL类型的例子
让我们来看不同的示例,以了解PostgreSQL串行伪类型的工作方式。
注意:我们可以为SERIAL列定义PRIMARY KEY约束,因为SERIAL类型不会间接在列上创建索引或将列设为主键列。
我们将在CREATE命令的帮助下创建一个新表,并使用INSERT命令插入一些值。
在下面的示例中,我们使用CREATE命令将Cars表生成到Organization数据库中:
CREATE TABLE Cars(
Car_id SERIAL PRIMARY KEY,
Car_name VARCHAR NOT NULL,
Car_model VARCHAR NOT NULL
);
输出量
执行上述命令后,已成功创建Cars表,如以下屏幕截图所示:
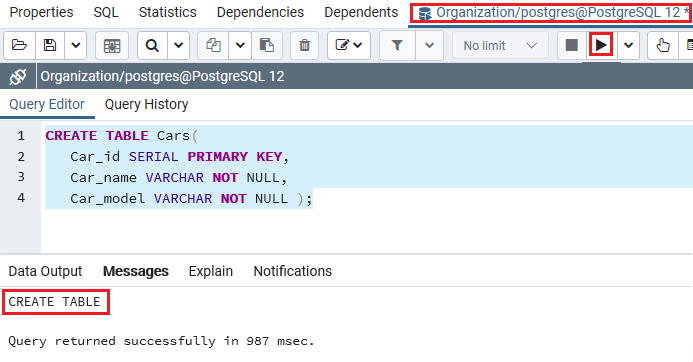
生成Cars表后,我们可以使用INSERT命令将一些值插入其中。而且我们可以在INSERT命令中使用DEFAULT关键字,或者省略列名(Car_id) 。
INSERT INTO Cars(Car_name, Car_model)
VALUES('Porche','911 Carrera');
输出量
执行上述命令后,我们将获得以下消息,并且该值已成功插入到Cars表中:
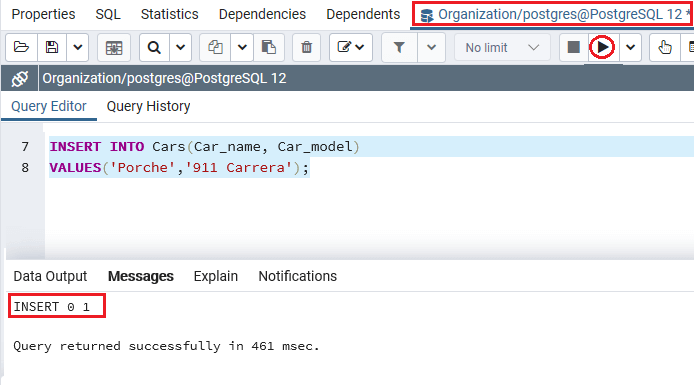
或将DEFAULT关键字与列名(Car_id)一起使用:
INSERT INTO Cars(Car_id, Car_name, Car_model)
VALUES(DEFAULT,'Audi','A8');
输出量
执行上述命令后,我们将获得以下消息;该值已成功插入到Cars表中:
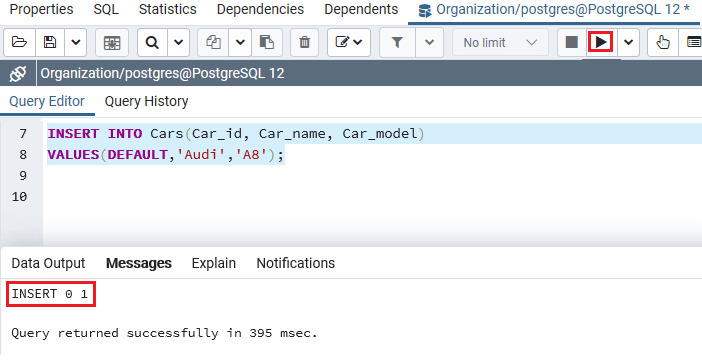
从上面的屏幕截图中可以看到,PostgreSQL在Cars表中插入了两行,其中Car_id列的值为1和2 。
创建并插入Cars表的值之后,我们将使用SELECT命令返回Cars表的所有行:
SELECT * FROM Cars;
输出量
成功执行上述命令后,我们将得到以下结果:

我们可以使用pg_get_serial_sequence()函数来获取指定表中SERIAL列的序列名,如下面的语法所示:
pg_get_serial_sequence('table_name','column_name')
为了获得由序列创建的当前值,我们可以将序列名称传递给currval()函数。
在以下示例中,我们使用currval()函数返回由Cars表Car_id_seq对象生成的当前值:
SELECT currval(pg_get_serial_sequence('Cars', 'car_id'));
输出量
执行上述命令后,我们将获得以下输出:
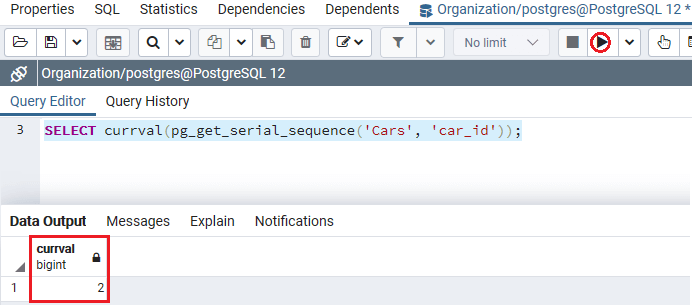
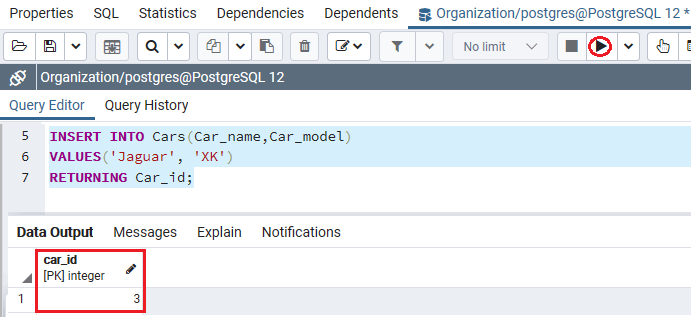
如果要在表中插入新行时获取序列创建的值,可以在INSERT命令中使用RETURNING Car_id子句。
以下命令用于在Cars表中插入新行,并返回为Car_id列生成的记录。
INSERT INTO Cars(Car_name,Car_model)
VALUES('Jaguar', 'XK')
RETURNING Car_id;
输出量
执行上述命令后,我们将获得以下输出,该输出将Car_id返回为3 :
注意:
- 如上所述,序列生成器操作不是事务安全的,这意味着如果两个并行数据库连接尝试从序列中获取下一个值,则每个用户将获得不同的值。
- 如果一个用户可以回滚交易,该用户的序列号将处于空闲状态,并在序列中造成缺口。
例2
让我们再看一个示例,以详细了解Serial伪类型。
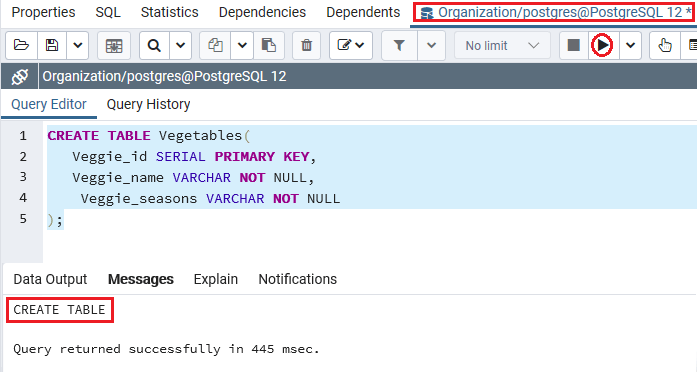
因此,我们将借助CREATE命令将另一个新表创建为Vegetables表,并将其创建为类似的数据库,该数据库是Organisation ,其Veg_id列为SERIAL伪类型。
CREATE TABLE Vegetables(
Veggie_id SERIAL PRIMARY KEY,
Veggie_name VARCHAR NOT NULL,
Veggie_seasons VARCHAR NOT NULL
);
输出量
执行上述命令后,蔬菜表已成功创建,如以下屏幕截图所示:
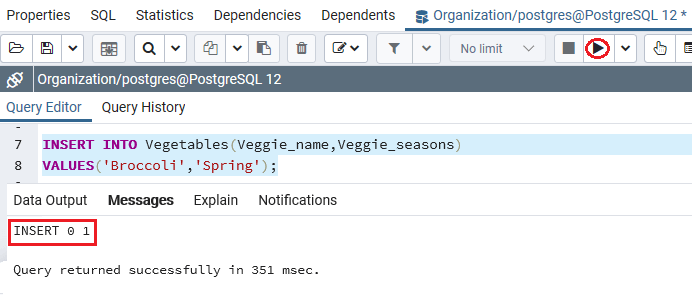
生成蔬菜表后,我们将使用INSERT命令在其中插入一些值,并省略Veggies_id列,如以下命令所示:
INSERT INTO Vegetables(Veggie_name,Veggie_seasons)
VALUES('Broccoli','Spring');
输出量
我们将获得有关执行上述命令的以下消息:该值已成功插入到Vegetables表中。
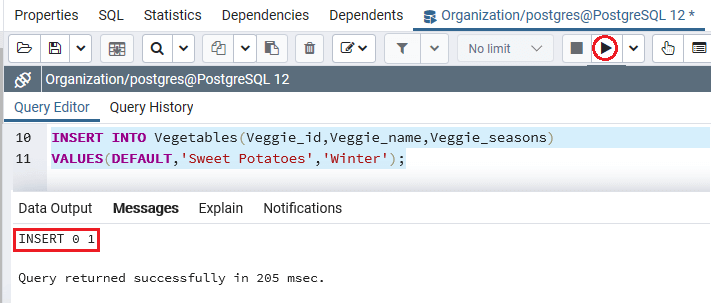
或者,我们也可以使用Default关键字并使用Veggie_id列,如以下命令所示:
INSERT INTO Vegetables (Veggie_id,Veggie_seasons, Veggie_seasons)
VALUES(DEFAULT, 'Sweet Potatoes','Winter');
输出量
执行完上述命令后,我们将获得以下消息,该消息表明我们可以使用Default关键字或忽略列名,我们将获得类似的输出:
因此,在以下命令的帮助下,我们将向Cars表添加更多值:
INSERT INTO Vegetables(Veggie_name,Veggie_seasons)
VALUES('Jalapeno Peppers','Fall'),
('Cucumbers','Summer'),
('Winter Squash','Winter'),
('Snow Peas','Spring'),
('Black Radish','All seasons'),
('Pumpkin','Fall');
输出量
执行上述命令后,我们将获得以下消息,该消息显示该值已成功插入到Vegetables表中。
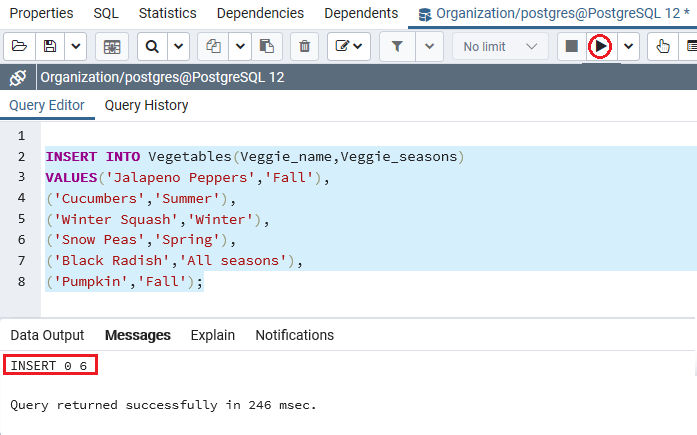
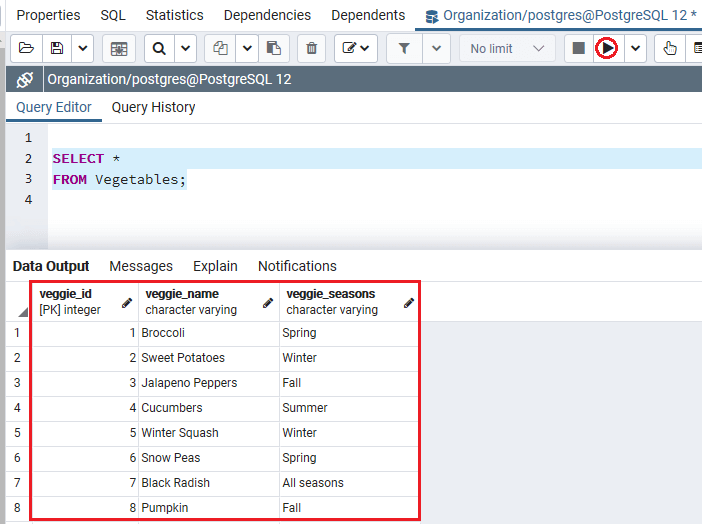
创建并插入蔬菜表的值后,我们将使用SELECT命令返回蔬菜表的所有行:
SELECT *
FROM Vegetables;
输出量
成功执行上述命令后,我们将获得以下输出:
总览
在PostgreSQL串行伪类型部分中,我们学习了串行伪类型功能,该功能主要用于为特定表创建自动增加列值。