超参数优化方法 – ML
超参数是我们为训练设置的参数。在训练模型时,超参数对准确性和效率有重大影响。因此,需要对其进行准确设置,以获得更好、更有效的结果。让我们首先讨论一些用于优化超参数的穷举搜索方法。
详尽的搜索方法
网格搜索:
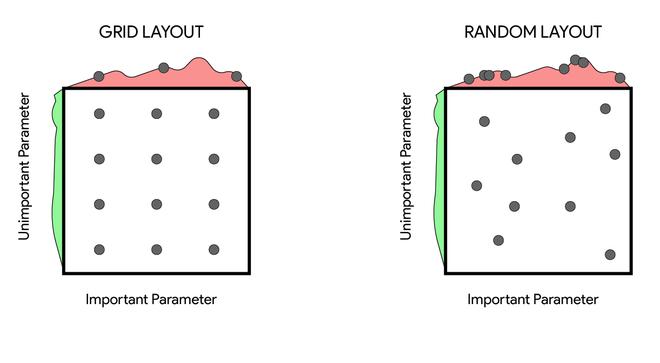
在网格搜索中,超参数的可能值被定义到集合中。然后使用笛卡尔积将这些可能的超参数值组合起来,形成一个多维网格。然后我们尝试网格中的所有参数并选择具有最佳结果的超参数设置。
随机搜索:
这是网格搜索的另一种变体,它不是尝试网格中的所有点,而是尝试随机点。这解决了网格搜索中的几个问题,例如我们不需要每次添加新的超参数都以指数方式扩展搜索空间
退税:
随机搜索和网格搜索很容易实现并且可以并行运行,但这些算法的一些缺点如下:
- 如果超参数搜索空间很大,则优化超参数需要花费大量时间和计算能力。
- 如果样本没有精心完成,则无法保证这些算法会找到局部最大值。
贝叶斯优化:
而不是随机猜测,在贝叶斯优化中,我们使用我们之前的知识来猜测超参数。他们利用这些结果以形成概率模型映射到超参数对目标函数得分的概率函数。这些概率函数定义如下。

该函数也称为目标函数的“代理”。优化比目标函数容易得多。以下是将贝叶斯优化应用于超参数优化的步骤:
- 建立目标函数的代理概率模型
- 找到在代理上表现最好的超参数
- 将这些超参数应用于原始目标函数
- 使用新结果更新代理模型
- 重复步骤 2-4 直到迭代次数为 n
基于序列模型的优化:
基于序列模型的优化 (SMBO) 是一种应用贝叶斯优化的方法。这里的顺序是指一个接一个地运行试验,每次都通过应用贝叶斯概率模型(代理)来改进超参数。
SMBO有5个重要参数:
- 的超参数域。
- 输出我们想要优化的分数的目标函数。
- 目标函数的代理分布
- 一个选择函数,用于选择接下来要选择的超参数。通常我们会考虑预期改进
- 数据结构包含先前迭代中使用的先前(分数、超参数)对的历史记录。
有许多不同版本的 SMBO 超参数优化算法。它们之间的这些共同区别是代理函数。一些替代函数,如高斯过程、随机森林回归、树 Prazen 估计器。在这篇文章中,我们将在下面讨论 Tree Prazen Estimator。
Tree Prazen 估计器:
Tree Prazen Estimators 使用树结构来优化超参数。使用这种方法可以优化许多超参数,例如层数、模型中的优化器、每层神经元的数量。在 tree prazen estimator 中,我们不是计算 P(y | x ),而是计算 P(x|y) 和 P(y)(其中 y 是一个中间分数,它决定了这个超参数值(例如验证损失)和 x 是超参数的好坏程度)。
在 Tree Prazen Estimator 的第一个中,我们通过随机搜索对验证损失进行采样以初始化算法。然后我们将观察结果分为两组:表现最好的一组(例如上四分位数)和其余的,将y*作为两组的拆分值。
然后我们计算超参数在每个组中的概率,例如
这两个密度和 g 是使用 Parzen 估计器(也称为核密度估计器)建模的,Parzen 估计器是以现有数据点为中心的核的简单平均值。
P(y) 是根据 p(y 使用贝叶法则(即 p(x, y) = p(y) p(x|y) ),可以证明预期改进的定义等价于 f(x)/g(x)。 在这最后一步中,我们尝试最大化 f(x)/g(x) 退税: Tree Prazen Estimator 的最大缺点是它选择彼此独立的超参数,这在某种程度上影响了所需的效率和计算,因为在大多数神经网络中它们是不同超参数之间的关系 超频 该算法的基本原理是,如果一个超参数配置在大量迭代后注定是最好的,那么在少量迭代后更有可能在配置的上半部分执行。下面是 Hyperband 的逐步实现。 缺点: 基于人口的训练 (PBT) 通过并行训练许多模型开始类似于基于随机的训练。但它不是独立训练网络,而是使用来自其余人口的信息来改进超参数并将计算资源引导到显示出前景的模型中。这从遗传算法中获得灵感,在遗传算法中,人口中的每个成员(称为工人)都可以利用来自其余人口的信息。例如,一个工人可能会从一个表现更好的工人那里复制模型参数。它还可以通过随机改变当前值来探索新的超参数。 BOHB(贝叶斯优化和HyperBand)是Hyperband 算法和贝叶斯优化的组合。首先,它使用 Hyperband 功能以较小的预算对许多配置进行采样,以快速有效地探索超参数搜索空间并很快获得有希望的配置,然后它使用贝叶斯优化器预测功能提出一组接近最优的超参数.该算法也可以并行运行(如 Hyperband),它克服了贝叶斯优化的一个严重缺陷。 参考:其他超参数估计算法:
基于人口的培训 (PBT):
贝叶斯优化和 HyperBand (BOHB):