- CNTK-序列分类
- CNTK-序列分类(1)
- CNTK-神经网络分类
- CNTK-回归模型
- CNTK-回归模型(1)
- CNTK-神经网络二进制分类(1)
- CNTK-神经网络二进制分类
- CNTK-监视模型(1)
- CNTK-监视模型
- CNTK-Logistic回归模型
- CNTK-Logistic回归模型(1)
- R分类(1)
- 胺的分类
- 桶分类
- R分类
- 桶分类(1)
- CNTK-内存中和大数据集(1)
- CNTK-内存中和大数据集
- 分类算法的分类
- 分类算法的分类(1)
- Python块分类
- Python块分类(1)
- 5.4.7 分类python(1)
- 不同分类模型的优缺点(1)
- 不同分类模型的优缺点
- CNTK-递归神经网络
- CNTK-递归神经网络(1)
- CNTK-评估效果(1)
- CNTK-评估效果
📅 最后修改于: 2020-12-10 05:07:48 🧑 作者: Mango
本章将帮助您了解如何衡量CNTK中分类模型的性能。让我们从混淆矩阵开始。
混淆矩阵
混淆矩阵-包含预期输出与预期输出的表是衡量分类问题性能的最简单方法,其中输出可以是两种或多种类型的类别。
为了了解其工作原理,我们将为二进制分类模型创建一个混淆矩阵,该模型可预测信用卡交易是正常交易还是欺诈交易。它显示如下-
| Actual fraud | Actual normal | |
|---|---|---|
|
Predicted fraud |
True positive |
False positive |
|
Predicted normal |
False negative |
True negative |
可以看到,上面的样本混淆矩阵包含2列,一列用于类别欺诈,另一列用于类别正常。以同样的方式,我们有2行,为行欺诈添加了一行,为正常课添加了另一行。以下是与混淆矩阵相关的术语的解释-
-
真实正值-当数据点的实际类别和预测类别均为1时。
-
真否定-当数据点的实际类别和预测类别均为0时。
-
误报-当数据点的实际类别为0且数据点的预测类别为1时。
-
假阴性-当数据点的实际类别为1且数据点的预测类别为0时。
让我们看看,如何从混淆矩阵中计算出不同事物的数量-
-
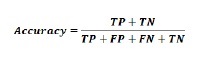
准确性-这是我们的ML分类模型做出的正确预测的数量。可以借助以下公式进行计算-
-
精度-它告诉我们在我们预测的所有样本中正确预测了多少个样本。可以借助以下公式进行计算-
-
回忆或敏感度-回忆是我们的ML分类模型返回的阳性数。换句话说,它告诉我们模型实际上检测到数据集中有多少个欺诈案件。可以借助以下公式进行计算-
-
特异性-与召回相反,它给出了我们的ML分类模型返回的负数。可以借助以下公式进行计算-

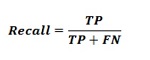

F测量
我们可以使用F度量作为混淆矩阵的替代方案。这背后的主要原因是,我们无法同时最大化查全率和查准率。这些指标之间有很强的关系,可以通过以下示例来理解-
假设我们要使用DL模型将细胞样本分类为癌性或正常。在这里,为了达到最高的精度,我们需要将预测数减少到1。虽然,这可以使我们达到100%左右的精度,但是召回率会非常低。
另一方面,如果我们想最大程度地提高召回率,则需要做出尽可能多的预测。虽然,这可以使我们达到100%左右的召回率,但是精确度确实会降低。
在实践中,我们需要找到一种在精度和召回率之间取得平衡的方法。 F量度指标允许我们这样做,因为它表示精度和召回率之间的谐波平均值。
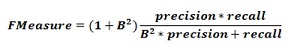
该公式称为F1量度,其中将称为B的额外项设置为1,以得到相等的精度和查全率。为了强调回忆,我们可以将系数B设置为2。另一方面,为了强调精度,我们可以将系数B设置为0.5。
使用CNTK衡量分类绩效
在上一节中,我们使用鸢尾花数据集创建了一个分类模型。在这里,我们将使用混淆矩阵和F-measure度量来测量其性能。
创建混淆矩阵
我们已经创建了模型,因此可以在其中开始包含混淆矩阵的验证过程。首先,我们将借助scikit-learn的confusion_matrix函数创建混淆矩阵。为此,我们需要测试样品的真实标签和相同测试样品的预测标签。
让我们通过使用以下Python代码来计算混淆矩阵-
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)
输出
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]
我们还可以使用热图函数来可视化混淆矩阵,如下所示:
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()

我们还应该有一个性能数字,可以用来比较模型。为此,我们需要使用classification_error函数来计算分类错误,从指标包CNTK为完成在创建分类模型。
现在要计算分类误差,请使用数据集对损失函数执行测试方法。之后,CNTK将采用我们提供的样本作为此函数的输入,并根据输入特征X_ test进行预测。
loss.test([X_test, y_test])
输出
{'metric': 0.36666666666, 'samples': 30}
实施F措施
为了实现F-措施,CNTK还包括称为f-措施的函数。我们可以在定义标准工厂函数时通过调用cntk.losses.fmeasure替换单元cntk.metrics.classification_error来训练NN时使用此函数,如下所示:
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metric
使用cntk.losses.fmeasure函数,对于loss.test方法调用,我们将获得不同的输出,如下所示:
loss.test([X_test, y_test])
输出
{'metric': 0.83101488749, 'samples': 30}