不同分类模型的优缺点
分类是典型的监督学习任务。我们在必须预测分类类型的情况下使用它,即特定示例是否属于某个类别(与用于预测连续值的回归不同)。例如,情感分析、将电子邮件分类为垃圾邮件、预测某人是否购买 SUV 或未提供包含工资的训练集以及购买 SUV。
分类模型的类型:
- Logistic 回归是一种线性分类模型(因此,预测边界是线性的),用于对二元因变量进行建模。它用于预测事件发生的概率 (p)。如果 p >= 0.5,则输出为 1,否则为 0。 sigmoid函数将概率值映射到离散类(0 和 1)。例如,假设我们的逻辑回归模型是在包含一个人的工资以及他是否购买 SUV 的数据集上进行训练的。现在,给定此人的薪水,我们的模型会预测此人是否购买 SUV。逻辑回归的几个假设是——预测变量之间没有高度相关性,结果的 sigmoid 与预测变量之间存在线性关系。
- K – Nearest Neighbors是一个非线性分类器(因此,预测边界是非线性的),它通过识别新测试数据点的 k 个最近邻居的类别来预测它属于哪个类别。我们根据欧几里德距离选择这 k 个最近的邻居。在这 k 个邻居中,计算每个类别中数据点的数量,并将新数据点分配给我们得到最多邻居的类别。
- 支持向量机 (SVM)用作基于所使用内核的线性或非线性分类器。如果我们使用线性核,那么分类器和预测边界都是线性的。在这里,要将两个类分开,我们需要画一条线。这条线有一个最大边距。这条线与两组等距绘制。我们在两边再画两条线,它们被称为支持向量。 SVM 从支持向量中学习,不像其他机器学习模型从正确和不正确的数据中学习。例如,假设我们有两个类——苹果和橙子。在这种情况下,SVM 学习在苹果中最右边(类似橙子的苹果)和橙子中最左边(类似苹果的橙子)的那些样本;也就是说,他们着眼于极端情况。因此,它们在大多数情况下表现更好。
- 当数据不是线性可分时,核 SVM特别有用。因此,我们将我们的非线性可分数据集映射到更高维度,得到一个线性可分数据集,调用 SVM 分类器,为数据构建决策边界,然后将其投影回原始维度。这种映射在计算上可能很昂贵,因此我们使用内核技巧,它给出了类似的结果。可用的内核有 – 高斯 RBF 内核、Sigmoid 内核、多项式内核(内核的默认值为“RBF”)。这也称为非线性 SVM。
- 朴素贝叶斯分类器基于贝叶斯定理工作。 所做的基本假设是所有特征都相互独立并且对结果的贡献相等;所有这些都同等重要。但是这些假设在现实生活中并不总是有效(朴素贝叶斯的缺点)。它是一个概率分类器模型,其关键是贝叶斯定理。
- 决策树分类是最强大的分类器。决策树是类似于树结构的流程图,其中每个内部节点表示对属性(条件)的测试,每个分支表示测试的结果(真或假),每个叶节点(终端节点)持有一个类标签。基于此树,进行拆分以区分给定原始数据集中的类。分类器根据决策树预测新数据点属于哪个类。预测边界是水平线和垂直线。下面是数据分布及其对应的决策树。
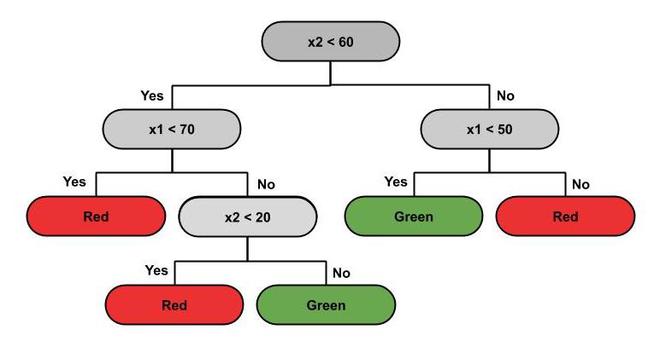
决策树
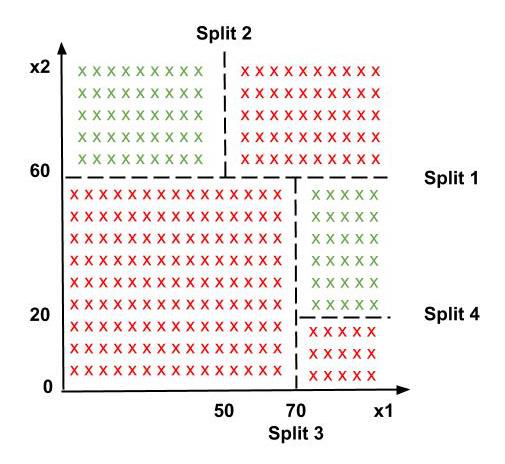
使用决策树拆分数据集
- 随机森林分类是集成学习的一个例子,其中将多种机器学习算法组合在一起以创建一个更大、性能更好的 ML 算法。我们从训练集中随机选择“k”个数据点,构建与这些 k 个点相关联的决策树。然后,我们选择要构建和重复的树的数量“n”。对于新的数据点,我们采用每个“n”决策树的预测,并将其分配给多数票类别。
Classification Model | Advantages | Disadvantages |
Logistic Regression | Probabilistic Approach, gives information about statistical significance of features. | The assumptions of logistic regression. |
K – Nearest Neighbours | Simple to understand, fast and efficient. | Need to manually choose the number of neighbours ‘k’. |
Support Vector Machine (SVM) | Performant, not biased by outliers, not sensitive to overfitting. | Not appropriate for non-linear problems, not the best choice for large number of features. |
Kernel SVM | High performance on non – linear problems, not biased by outliers, not sensitive to overfitting. | Not the best choice for large number of features, more complex. |
Naive Bayes | Efficient, not biased by outliers, works on non – linear problems, probabilistic approach. | Based in the assumption that the features have same statistical relevance. |
Decision Tree Classification | Interpretability, no need for feature scaling, works on both linear / non – linear problems. | Poor results on very small datasets, overfitting can easily occur. |
Random Forest Classification | Powerful and accurate, good performance on many problems, including non – linear. | No interpretability, overfitting can easily occur, need to choose the number of trees manually. |
我们如何为给定的问题选择正确的分类模型?
分类模型的准确性是根据误报和否定的数量来衡量的。
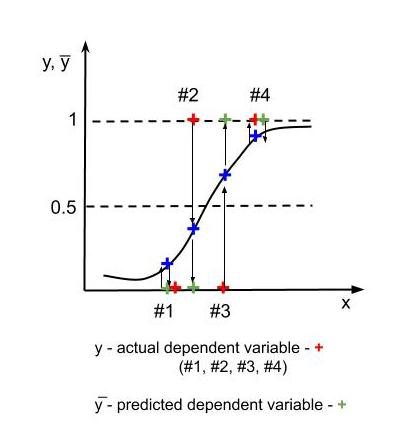
假阳性和假阴性
上图中,对于1, 4 – y = y̅(实际值=预测值)。 3 处的错误是假阳性或类型 1 错误(我们预测了阳性结果,但它是错误的——我们预测了没有发生的效果)。 2 处的错误是假阴性或类型 2 错误(我们预测的结果是错误的,这在现实中会发生——这有点像预测癌症患者没有患癌症,这对患者的健康非常危险。我们使用混淆矩阵表示误报、漏报和正确预测结果的数量。

从混淆矩阵计算精度
假设最初,模型正确地将 9700 个观察结果预测为真,100 个观察结果为假,150 个为 1 类错误(假阳性),其余 50 个为 2 类错误(假阴性)。因此,准确率 = (9800/10000)*100 = 98%。
现在,让我们停止模型进行预测并说我们的预测 y̅ = 0 总是。在这种情况下,误报的数量减少到 0 并添加到正确预测的真实观察中,而先前正确预测的错误观察减少到 0。它增加了误报。因此,现在我们有 – 9850 个观察结果被正确预测为真,150 个观察结果为假阴性。因此,准确率 = (9850/10000)*100 = 98.5%,比之前的模型更高!但实际上,我们的模型根本没有经过训练。它总是预测 0。这被称为准确性悖论。
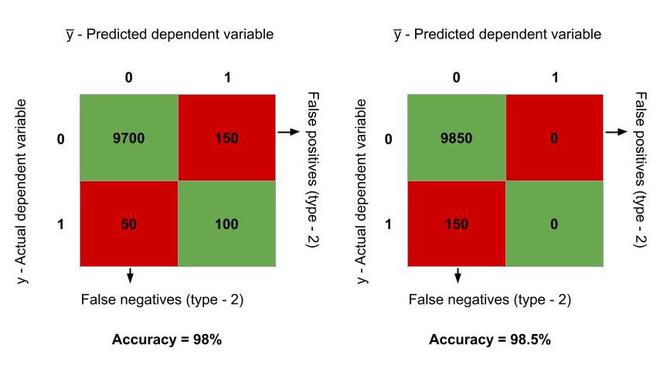
准确性悖论
因此,我们需要比准确率更准确的方法来分析我们的模型。为此,我们使用 CAP 曲线。模型的准确率是使用 CAP 曲线分析计算的。准确率是模型 CAP 和随机 CAP 之间包围的面积 (aR) 与完美 CAP 和随机 CAP 之间包围的面积 (aP) 的比值。准确率越接近 1,模型越好。一个好的模型的 CAP 曲线介于完美 CAP 和随机 CAP 之间。
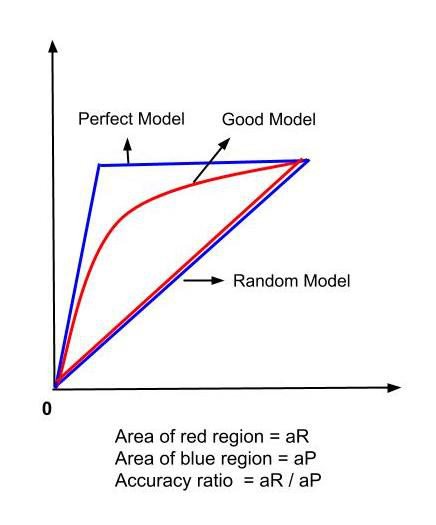
CAP曲线分析
通过考虑因变量和自变量之间的关系类型(线性或非线性),为问题选择特定分类模型的利弊,以及通过上述方法建立模型的准确性,我们选择分类最适合要解决的问题的问题。