- 聚类算法-分层聚类
- 缺陷聚类概述
- 聚类算法-K-均值算法
- 不同类型的聚类算法
- 不同类型的聚类算法
- 不同类型的聚类算法(1)
- 不同类型的聚类算法(1)
- R 编程中的聚类(1)
- R 编程中的聚类
- 聚类算法-均值漂移算法
- 聚类算法-均值漂移算法(1)
- Python 中的 K-Means 聚类 - 3 个聚类 - Python (1)
- 数据结构和算法-概述(1)
- 数据结构和算法-概述
- Python 中的 K-Means 聚类 - 3 个聚类 - Python 代码示例
- k-means 聚类和禁用聚类 - Python 代码示例
- 回归算法-概述
- 回归算法-概述(1)
- F#-概述
- 坞站概述
- C++概述(1)
- C#-概述
- C++概述
- F#-概述(1)
- R-概述
- R-概述(1)
- Julia 中的聚类(1)
- Julia 中的聚类
- Julia 中的聚类
📅 最后修改于: 2020-12-10 05:39:40 🧑 作者: Mango
集群介绍
聚类方法是最有用的无监督ML方法之一。这些方法用于查找数据样本之间的相似性以及关系模式,然后基于特征将这些样本聚类为具有相似性的组。
聚类很重要,因为它决定了当前未标记数据之间的固有分组。他们基本上对数据点进行一些假设以构成它们的相似性。每个假设将构建不同但有效的集群。
例如,以下是显示集群系统的图,该集群系统将不同集群中的同类数据分组在一起-
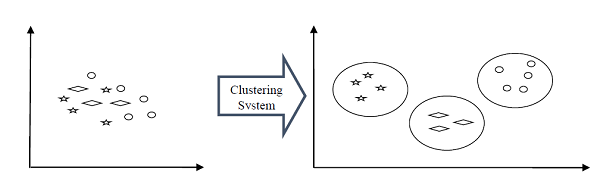
团簇形成方法
簇不必形成球形。以下是其他一些集群形成方法-
基于密度
在这些方法中,簇形成为密集区域。这些方法的优点是它们具有良好的准确性以及合并两个聚类的良好能力。例如带噪声的应用程序的基于密度的空间聚类(DBSCAN),识别聚类结构的订购点(OPTICS)等。
基于层次的
在这些方法中,群集基于层次结构形成为树型结构。它们有两类,即凝聚(自下而上的方法)和分裂(自上而下的方法)。例如使用代表进行聚类(CURE),使用层次结构进行平衡的减少迭代聚类(BIRCH)等。
分区
在这些方法中,通过将对象分成k个簇来形成簇。群集数将等于分区数。例如K均值,基于随机搜索(CLARANS)对大型应用程序进行聚类。
格
在这些方法中,簇形成为网格状结构。这些方法的优点是在这些网格上完成的所有聚类操作都是快速的,并且与数据对象的数量无关。例如统计信息网格(STING),任务中的聚类(CLIQUE)。
衡量集群性能
关于ML模型的最重要考虑因素之一是评估其性能,或者可以说模型的质量。在监督学习算法的情况下,评估模型的质量很容易,因为我们已经为每个示例添加了标签。
另一方面,在无监督学习算法的情况下,我们没有那么幸运,因为我们处理的是未标记数据。但是,我们仍然有一些度量标准可以使从业者了解根据算法在集群中发生的变化。
在深入研究此类指标之前,我们必须了解,这些指标仅评估模型之间的比较性能,而不是评估模型预测的有效性。以下是我们可以在聚类算法上部署以衡量模型质量的一些指标-
轮廓分析
轮廓分析用于通过测量聚类之间的距离来检查聚类模型的质量。它基本上为我们提供了一种利用Silhouette得分评估参数(如聚类数)的方法。此分数衡量一个群集中的每个点与相邻群集中的点的接近程度。
轮廓分数分析
Silhouette得分的范围是[-1,1]。其分析如下-
-
+1分数-接近+1轮廓分数表示样本距离其邻近簇很远。
-
0得分− 0轮廓得分表示样本位于或非常接近分隔两个相邻聚类的决策边界上。
-
-1分数和负-1轮廓分数表示样本已分配给错误的聚类。
Silhouette得分的计算可以使用以下公式进行:
𝒔𝒄𝒐𝒓𝒆=(𝒑−𝒒)/𝐦𝐚𝐱(𝒑,𝒒)
𝑝=到最近簇的点的平均距离
并且,𝑞=到所有点的平均集群内距离。
戴维斯-布尔丁指数
DB索引是执行聚类算法分析的另一个很好的指标。借助数据库索引,我们可以了解有关聚类模型的以下几点:
-
天气群集之间的间距是否合适?
-
这些簇有多少密度?
我们可以借助以下公式计算数据库索引-
$$ DB = \ frac {1} {n} \ displaystyle \ sum \ limits_ {i = 1} ^ n max_ {j \ neq {i}} \ left(\ frac {\ sigma_ {i} + \ sigma_ {j }} {d(c_ {i},c_ {j})} \ right)$$
𝑛=簇数
σI =所有点的平均距离在簇𝑖从群集重心𝑐𝑖。
DB索引越少,集群模型越好。
邓恩指数
它的工作原理与数据库索引相同,但是在以下几点上,两者有所不同-
-
Dunn索引仅考虑最坏的情况,即靠近在一起的集群,而DB索引考虑聚类模型中所有集群的分散和分离。
-
Dunn索引随着性能的提高而增加,而当群集间隔适当且密集时,DB索引会变得更好。
我们可以借助以下公式来计算Dunn指数-
$$ D = \ frac {min_ {1 \ leq i <{j} \ leq {n}} P(i,j)} {mix_ {1 \ leq i ,,𝑗,𝑘=聚类的每个索引 𝑝=集群间距离 q =集群内距离 以下是最重要和最有用的ML聚类算法- 该聚类算法计算质心并进行迭代,直到找到最佳质心为止。它假定群集的数目是已知的。它也称为平面聚类算法。通过算法从数据中识别出的聚类数量以K均值中的“ K”表示。 它是在无监督学习中使用的另一种强大的聚类算法。与K均值聚类不同,它没有做任何假设,因此它是一种非参数算法。 这是另一种无监督的学习算法,用于将具有相似特征的未标记数据点分组在一起。 在接下来的章节中,我们将详细讨论所有这些算法。 我们发现聚类在以下领域很有用- 数据汇总和压缩-群集也广泛用于我们需要数据汇总,压缩和缩减的领域。示例是图像处理和矢量量化。 协作系统和客户细分-由于群集可用于查找相似的产品或相同类型的用户,因此可将其用于协作系统和客户细分领域。 用作其他数据挖掘任务的关键中间步骤-聚类分析可以生成数据的紧凑摘要,以进行分类,测试和假设生成;因此,它也是其他数据挖掘任务的关键中间步骤。 动态数据中的趋势检测-通过制作相似趋势的各种群集,聚类也可以用于动态数据中的趋势检测。 社交网络分析-聚类可用于社交网络分析。示例是在图像,视频或音频中生成序列。 生物数据分析-聚类还可以用于将图像和视频进行聚类,因此可以成功地用于生物数据分析。ML聚类算法的类型
K均值聚类
均值漂移算法
层次聚类
聚类的应用