R 编程中的聚类
R编程语言中的聚类是一种无监督学习技术,其中数据集根据它们的相似性被划分为多个称为聚类的组。数据分割后会产生几个数据簇。集群中的所有对象都具有共同的特征。在数据挖掘和分析过程中,聚类用于寻找相似的数据集。
聚类在 R 编程语言中的应用
- 营销:在 R 编程中,聚类有助于营销领域。它有助于找到市场模式,从而有助于找到可能的买家。使用聚类获得客户的兴趣并展示他们感兴趣的相同产品可以增加购买该产品的机会。
- 医学:在医学领域,每天都有新的药物和治疗发明。有时,研究人员和科学家也会发现新物种。它们的类别可以通过使用基于相似性的聚类算法轻松找到。
- 游戏:也可以使用聚类算法根据用户的兴趣向用户展示游戏。
- 互联网:用户根据自己的兴趣浏览很多网站。可以聚合浏览历史以对其进行聚类,并根据聚类结果生成用户的个人资料。
聚类方法
R编程中有两种类型的聚类:
- 硬聚类:在这种类型的聚类中,数据点要么完全属于集群,要么不属于集群,数据点只分配给一个集群。用于硬聚类的算法是k-means聚类。
- 软聚类:在软聚类中,数据点的概率或可能性被分配到集群中,而不是将每个数据点放在一个集群中。每个数据点以一定的概率存在于所有集群中。用于软聚类的算法是模糊聚类方法或软 k-means。
R编程语言中的K-Means聚类
K-Means 是一种使用无监督学习算法的迭代硬聚类技术。其中,聚类的总数由用户预先定义,并根据每个数据点的相似性,对数据点进行聚类。该算法还找出了集群的质心。
算法:
- 指定簇数 (K):让我们以 k = 2 和 5 个数据点为例。
- 将每个数据点随机分配给一个集群:在下面的示例中,红色和绿色显示 2 个集群,它们各自的随机数据点分配给它们。
- 计算簇质心:叉号表示对应簇的质心。
- 将每个数据点重新分配到它们最近的簇质心:绿色数据点分配给红色簇,因为它靠近红色簇的质心。
- 重新计算集群质心
Syntax: kmeans(x, centers, nstart)
where,
- x represents numeric matrix or data frame object
- centers represents the K value or distinct cluster centers
- nstart represents number of random sets to be chosen
例子:
R
# Library required for fviz_cluster function
install.packages("factoextra")
library(factoextra)
# Loading dataset
df <- mtcars
# Omitting any NA values
df <- na.omit(df)
# Scaling dataset
df <- scale(df)
# output to be present as PNG file
png(file = "KMeansExample.png")
km <- kmeans(df, centers = 4, nstart = 25)
# Visualize the clusters
fviz_cluster(km, data = df)
# saving the file
dev.off()
# output to be present as PNG file
png(file = "KMeansExample2.png")
km <- kmeans(df, centers = 5, nstart = 25)
# Visualize the clusters
fviz_cluster(km, data = df)
# saving the file
dev.off()输出:
When k = 4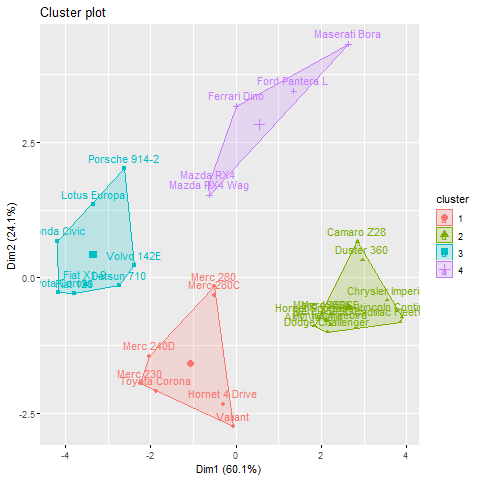
When k = 5 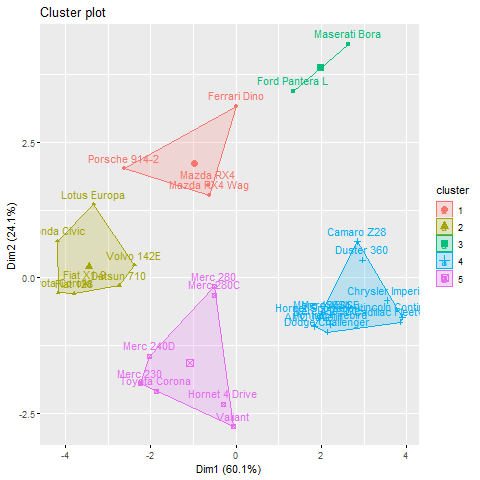
通过相似性聚合聚类
通过相似性聚合进行聚类也称为关系聚类或孔多塞方法,它将每个数据点与所有其他数据点成对进行比较。对于一对值 A 和 B,这些值分配给向量 m(A, B) 和 d(A, B)。 A 和 B 在 m(A, B) 中相同,但在 d(A, B) 中不同。

where, S is the cluster
在第一个条件下,构建集群,在下一个条件下,计算全局 Condorcet 标准。它以迭代方式进行,直到未完成指定的迭代或全局 Condorcet 标准没有产生任何改进。