通过聚类进行图像分割
通过聚类进行分割
它是一种执行逐像素分割的图像分割的方法。在这种类型的分割中,我们尝试对在一起的像素进行聚类。有两种通过聚类执行分割的方法。
- 通过合并聚类
- 按分裂聚类
通过合并或凝聚聚类进行聚类:
在这种方法中,我们遵循自底向上的方法,这意味着我们分配最接近集群的像素。执行凝聚聚类的算法如下:
- 将每个点作为一个单独的集群。
- 对于给定的时期数或直到聚类令人满意。
- 合并具有最小集群间距离 (WCSS) 的两个集群。
- 重复以上步骤
凝聚聚类由树状图表示。它可以通过 3 种方法执行:通过选择最近的对进行合并,通过选择最远的对进行合并,或通过选择平均距离(既不是最近也不是最远)的对。代表这些类型聚类的树状图如下:

最近聚类

平均聚类
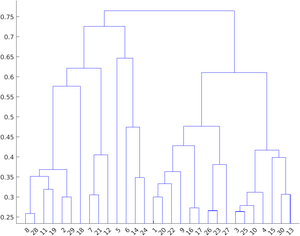
最远聚类
通过除法或分裂法进行聚类
在这种方法中,我们遵循自上而下的方法,这意味着我们分配最接近集群的像素。执行凝聚聚类的算法如下:
- 构建包含所有点的单个集群。
- 对于给定的时期数或直到聚类令人满意。
- 将集群拆分为两个集群间距离最大的集群。
- 重复以上步骤。
在本文中,我们将讨论如何执行 K-Means 聚类。
K-均值聚类
K-means 聚类是一种非常流行的聚类算法,当我们有一个标签未知的数据集时应用它。目标是根据数据中的某种相似性找到某些组,其中组的数量用 K 表示。该算法通常用于市场细分、客户细分等领域。但是,它也可以用于细分基于像素值的图像中的不同对象。
图像分割算法的工作原理如下:
- 首先,我们需要在K-means聚类中选择K的值。
- 为每个像素选择一个特征向量(颜色值,如 RGB 值、纹理等)。
- 定义一个相似性度量 b/w 特征向量,例如欧几里德距离来度量任何两点/像素的 b/w 相似性。
- 将 K-means 算法应用于聚类中心
- 应用连通分量的算法。
- 将大小小于阈值的任何组件组合到与其相似的相邻组件,直到您无法组合更多。
以下是应用 K-means 聚类算法的步骤:
- 选择 K 个点,并为每个点分配一个聚类中心。
- 直到聚类中心不会发生变化,执行以下步骤:
- 将每个点分配到最近的聚类中心,并确保每个聚类中心都有一个点。
- 用分配给它的点的平均值替换聚类中心。
- 结尾
K的最佳值?
对于某类聚类算法,有一个通常称为 K 的参数,用于指定要检测的聚类数。如果我们有关于数据包含多少类别的领域知识,我们可能有 K 的预定义值。但是,在计算 K 的最优值之前,我们首先需要为上述算法定义目标函数。目标函数可由下式给出:

其中 j 是集群的数量,i 将是属于第 j个集群的点。上述目标函数称为簇内平方和(WCSS)距离。
找到 K 的最佳值的一个好方法是暴力破解较小范围的值 (1-10) 并绘制 WCSS 距离与 K 的关系图。图形急剧向下弯曲的点可以认为是K. 这种方法称为肘法。
对于图像分割,我们绘制图像的直方图并尝试在其中找到峰值和谷值。然后,我们将对该直方图执行峰值测试。
执行
- 在这个实现中,我们将使用 K-Means 聚类执行图像分割。我们将使用 OpenCV k-Means API 来执行此聚类。
Python3
# imports
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (12,50)
# load image
img = cv.imread('road.jpg')
Z = img.reshape((-1,3))
# convert to np.float32
Z = np.float32(Z)
# define stopping criteria, number of clusters(K) and apply kmeans()
# TERM_CRITERIA_EPS : stop when the epsilon value is reached
# TERM_CRITERIA_MAX_ITER: stop when Max iteration is reached
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
fig, ax = plt.subplots(10,2, sharey=True)
for i in range(10):
K = i+3
# apply K-means algorithm
ret,label,center=cv.kmeans(Z,K,None,criteria,attempts = 10,
cv.KMEANS_RANDOM_CENTERS)
# Now convert back into uint8, and make original image
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
# plot the original image and K-means image
ax[i, 1].imshow(res2)
ax[i,1].set_title('K = %s Image'%K)
ax[i, 0].imshow(img)
ax[i,0].set_title('Original Image')
K=3,4,5 的图像分割

K=6,7,8 的图像分割

参考:
- 纽约大学幻灯片
- OpenCV K-means