Pandas 中的分层数据
在pandas中,我们可以从现有的数据框中排列数据框内的数据。例如,我们有相同的名字,但有不同的特征,而不是一直写名字,我们只能写一次。我们可以使用 Pandas 从现有数据框中创建分层数据。
例子:
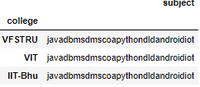
查看学生科目详细信息。在这里我们可以看到学生的名字总是重复。
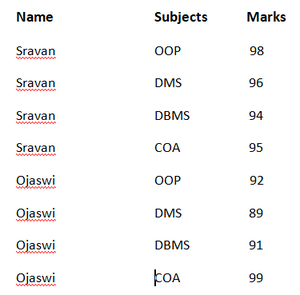
有了这个,我们需要内存来存储多个名称。我们可以通过使用数据层次结构来减少这种情况。
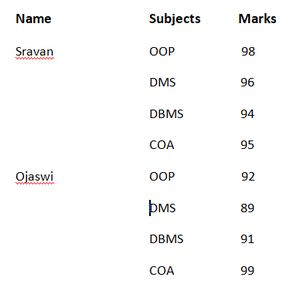
例子:
Python3
# import pandas module for data frame
import pandas as pd
# Create dataframe for student data in different colleges
subjectsdata = {'Name': ['sravan', 'sravan', 'sravan', 'sravan',
'sravan', 'sravan', 'sravan', 'sravan',
'Ojaswi', 'Ojaswi', 'Ojaswi', 'Ojaswi',
'Ojaswi', 'Ojaswi', 'Ojaswi', 'Ojaswi',
'Rohith', 'Rohith', 'Rohith', 'Rohith',
'Rohith', 'Rohith', 'Rohith', 'Rohith'],
'college': ['VFSTRU', 'VFSTRU', 'VFSTRU', 'VFSTRU',
'VFSTRU', 'VFSTRU', 'VFSTRU', 'VFSTRU',
'VIT', 'VIT', 'VIT', 'VIT', 'VIT', 'VIT',
'VIT', 'VIT', 'IIT-Bhu', 'IIT-Bhu', 'IIT-Bhu',
'IIT-Bhu', 'IIT-Bhu', 'IIT-Bhu', 'IIT-Bhu',
'IIT-Bhu'],
'subject': ['java', 'dbms', 'dms', 'coa', 'python', 'dld',
'android', 'iot', 'java', 'dbms', 'dms', 'coa',
'python', 'dld', 'android', 'iot', 'java',
'dbms', 'dms', 'coa', 'python', 'dld', 'android',
'iot']
}
# Convert into data frame
df = pd.DataFrame(subjectsdata)
# print the data(student records)
print(df)Python3
# Set the hierarchical index
df = df.set_index(['Name', 'college'], drop=False)
# print data frame
dfPython3
# setting index
df = df.set_index(['Name', 'college'])
# print data frame
dfPython3
# Swap the levels in the index
df.swaplevel('Name', 'college')Python3
# Summarize the results by college
df.sum(level='college')输出:

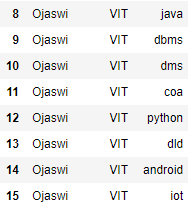
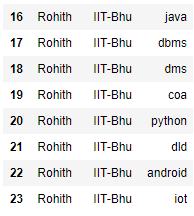
蟒蛇3
# Set the hierarchical index
df = df.set_index(['Name', 'college'], drop=False)
# print data frame
df
输出:
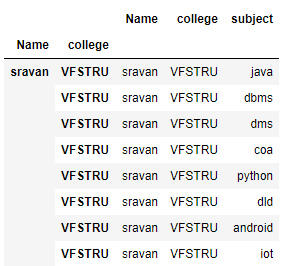
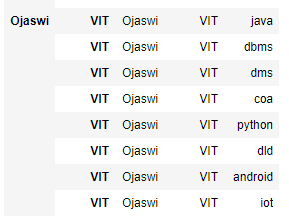

下一步是删除名称。
蟒蛇3
# setting index
df = df.set_index(['Name', 'college'])
# print data frame
df
输出:
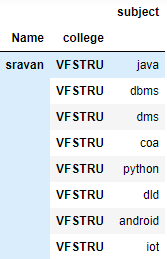
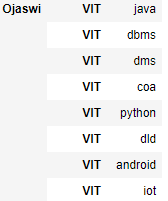
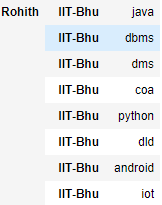
现在使用交换级别将大学作为索引。
蟒蛇3
# Swap the levels in the index
df.swaplevel('Name', 'college')
输出:

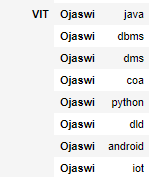

现在总结一下结果
蟒蛇3
# Summarize the results by college
df.sum(level='college')
输出: