📌 相关文章
- Python的逻辑回归-测试(1)
- Python的逻辑回归-测试
- python中的逻辑回归算法(1)
- Python教程中的逻辑回归
- Python教程中的逻辑回归(1)
- Python的逻辑回归-简介(1)
- Python的逻辑回归-简介
- 逻辑回归 - R 编程语言(1)
- python代码示例中的逻辑回归算法
- 讨论Python的逻辑回归
- R 编程中的逻辑回归
- R 编程中的逻辑回归(1)
- 逻辑回归 - R 编程语言代码示例
- Julia 中的逻辑回归(1)
- Julia 中的逻辑回归
- Python的逻辑回归-拆分数据
- Python的逻辑回归-摘要(1)
- Python的逻辑回归-摘要
- 了解逻辑回归
- 了解逻辑回归(1)
- 理解逻辑回归
- 理解逻辑回归(1)
- ML-线性回归与逻辑回归
- ML-线性回归与逻辑回归(1)
- Python的逻辑回归-有用的资源(1)
- Python的逻辑回归-有用的资源
- Python的逻辑回归-准备数据
- Python的逻辑回归-准备数据(1)
- 毫升 |线性回归与逻辑回归
📜 Python的逻辑回归-获取数据
📅 最后修改于: 2020-12-13 14:01:15 🧑 作者: Mango
本章详细讨论了获取数据以在Python中执行逻辑回归的步骤。
下载数据集
如果尚未下载前面提到的UCI数据集,请立即从此处下载。单击数据文件夹。您将看到以下屏幕-

通过单击给定的链接下载bank.zip文件。压缩文件包含以下文件-

我们将使用bank.csv文件进行模型开发。 bank-names.txt文件包含您稍后将需要的数据库描述。 bank-full.csv包含更大的数据集,您可以将其用于更高级的开发。
在这里,我们已将bank.csv文件包含在可下载的源zip中。该文件包含逗号分隔的字段。我们还在文件中做了一些修改。建议您使用项目源zip中包含的文件进行学习。
加载数据中
要从刚才复制的csv文件中加载数据,请键入以下语句并运行代码。
In [2]: df = pd.read_csv('bank.csv', header=0)
您还可以通过运行以下代码语句来检查加载的数据:
IN [3]: df.head()
运行命令后,您将看到以下输出-
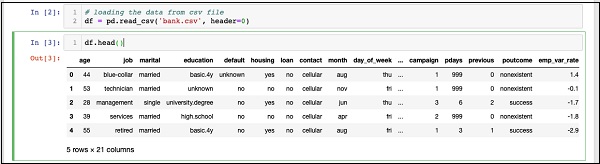
基本上,它已打印已加载数据的前五行。检查存在的21列。我们将仅使用其中的几列进行模型开发。
接下来,我们需要清理数据。数据可能包含带有NaN的某些行。要消除此类行,请使用以下命令-
IN [4]: df = df.dropna()
幸运的是,bank.csv不包含任何带有NaN的行,因此在我们的情况下,此步骤并不是必需的。但是,通常很难在庞大的数据库中发现这样的行。因此,运行上面的语句来清理数据总是更安全的。
注意-您可以使用以下语句在任何时间点轻松检查数据大小-
IN [5]: print (df.shape)
(41188, 21)
如上面第二行所示,行和列的数量将被打印在输出中。
接下来要做的是检查每列对我们尝试构建的模型的适用性。