- 并行算法-排序
- 并行算法-排序(1)
- 并行算法教程(1)
- 并行算法教程
- 并行算法-简介(1)
- 并行算法-简介
- 讨论并行算法
- 并行算法-结构
- 并行算法-结构(1)
- 并行算法-分析
- 并行算法-分析(1)
- 并行算法-设计技术(1)
- 并行算法-设计技术
- 并行算法-有用的资源(1)
- 并行算法-有用的资源
- 并行算法-矩阵乘法(1)
- 并行算法-矩阵乘法
- V模型
- V模型(1)
- V模型(1)
- V模型
- V模型和增量模型的区别
- V模型和增量模型的区别(1)
- 模型 d 或模型 o 点击测试 (1)
- 敏捷模型和 V 模型的区别
- 什么是 v 模型 (1)
- C#中的模型是什么(1)
- 模型 d 或模型 o 点击测试 - 任何代码示例
- 模型到 js - Javascript (1)
📅 最后修改于: 2020-12-13 15:13:22 🧑 作者: Mango
通过考虑用于划分数据和处理方法的策略并应用适当的策略来减少交互,来开发并行算法的模型。在本章中,我们将讨论以下并行算法模型-
- 数据并行模型
- 任务图模型
- 工作池模型
- 主从模型
- 生产者消费者或管道模型
- 混合模型
数据并行
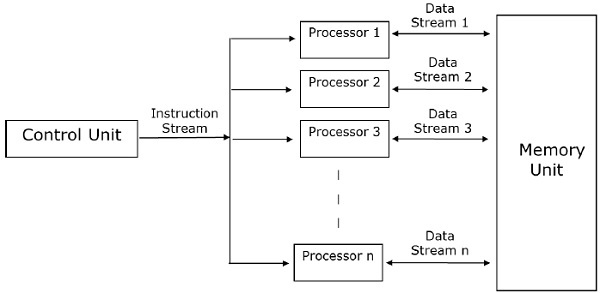
在数据并行模型中,将任务分配给进程,并且每个任务对不同的数据执行相似类型的操作。数据并行性是单个操作应用于多个数据项的结果。
数据并行模型可以应用于共享地址空间和消息传递范例。在数据并行模型中,可以通过选择保留局部性的分解,使用优化的集体交互例程或通过重叠计算和交互来减少交互开销。
数据并行模型问题的主要特征是,数据并行性的强度随问题的大小而增加,这反过来使得可以使用更多的过程来解决较大的问题。
示例-密集矩阵乘法。
任务图模型
在任务图模型中,并行性由任务图表示。任务图可以是平凡的或非平凡的。在此模型中,任务之间的相关性被用来提升局部性或最小化交互成本。强制执行此模型以解决与任务关联的计算量相比,与任务关联的数据量巨大的问题。分配任务是为了帮助提高任务之间的数据移动成本。
示例-并行快速排序,稀疏矩阵分解和通过分而治之方法得出的并行算法。
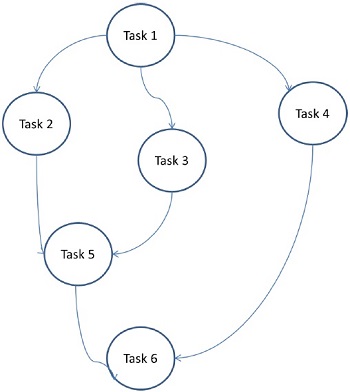
在这里,问题被分为基本任务,并以图形的形式实现。每个任务都是一个独立的工作单元,它依赖于一个或多个先前任务。任务完成后,先前任务的输出将传递到从属任务。具有先行任务的任务仅在其整个先行任务完成后才开始执行。当最后一个从属任务完成时(上图中的任务6),将收到图形的最终输出。
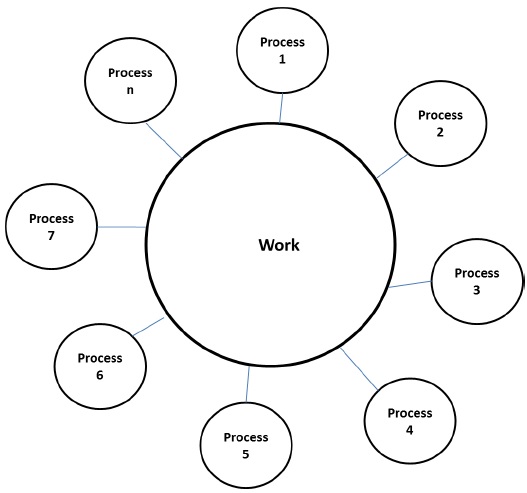
工作池模型
在工作池模型中,将任务动态分配给流程以平衡负载。因此,任何进程都可能潜在地执行任何任务。当与任务关联的数据量相对小于与任务关联的计算量时,使用此模型。
没有期望的任务预分配到流程。任务分配是集中式或分散式的。指向任务的指针保存在物理共享列表,优先级队列,哈希表或树中,也可以保存在物理分布式数据结构中。
该任务可能在一开始就可用,或者可以动态生成。如果任务是动态生成的,并且完成了任务的分散分配,则需要终止检测算法,以便所有进程实际上可以检测到整个程序的完成,并停止寻找更多任务。
示例-并行树搜索
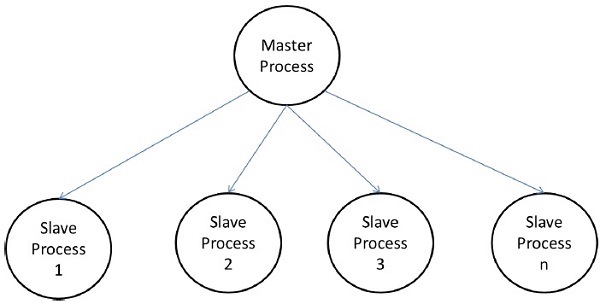
主从模型
在主从模型中,一个或多个主进程生成任务并将其分配给从属进程。如果满足以下条件,则可以预先分配任务:
- 主人可以估算任务量,或者
- 随机分配可以令人满意地平衡负载,或者
- 在不同的时间为从属分配较小的任务。
该模型通常同样适用于共享地址空间或消息传递范例,因为交互自然是两种方式。
在某些情况下,可能需要分阶段完成任务,并且必须先完成每个阶段中的任务,然后才能生成下一个阶段中的任务。主从模型可以概括为分层或多级主从模型,其中顶级主服务器将大部分任务提供给第二主服务器,第二主服务器进一步将任务细分为自己的从服务器,并可以执行任务本身的一部分。
使用主从模型的注意事项
应注意确保主站不会成为拥塞点。如果任务太小或工人速度相对较快,则可能会发生这种情况。
选择任务的方式应使执行任务的成本主导通信成本和同步成本。
异步交互可以帮助重叠交互以及与主机生成工作相关的计算。
管道模型
它也被称为生产者-消费者模型。这里,一组数据通过一系列过程传递,每个过程都对它执行一些任务。在这里,新数据的到达通过队列中的进程生成了新任务的执行。该过程可以形成具有或不具有循环的线性或多维阵列,树或一般图形形式的队列。
这种模式是生产者和消费者的链条。队列中的每个进程都可以被视为队列中它之前的进程的一系列数据项的使用者,并且可以看作队列中它之后的进程的数据生成者。队列不必是线性链;它可以是有向图。适用于此模型的最常见的交互最小化技术是交互与计算重叠。
示例-并行LU分解算法。
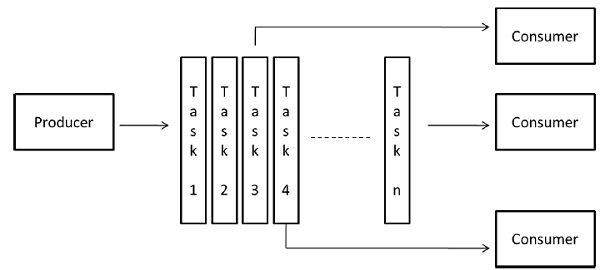
混合模型
当可能需要一个以上的模型来解决问题时,需要使用混合算法模型。
混合模型可以由分层应用的多个模型或顺序应用于并行算法的不同阶段的多个模型组成。
示例-并行快速排序