📌 相关文章
📜 并行算法-排序
📅 最后修改于: 2020-12-13 15:16:07 🧑 作者: Mango
排序是将元素按特定顺序(即升序,降序,字母顺序等)排列在组中的过程。在这里,我们将讨论以下内容-
- 枚举排序
- 奇偶换位排序
- 并行合并排序
- 超快速排序
对元素列表进行排序是非常常见的操作。当我们必须对大量数据进行排序时,顺序排序算法可能不够高效。因此,在分类中使用并行算法。
枚举排序
枚举排序是一种通过查找已排序列表中每个元素的最终位置来排列列表中所有元素的方法。通过将每个元素与所有其他元素进行比较并找到具有较小值的元素数量来完成此操作。
因此,对于任何两个元件,一个i和j的下列情形之一必须为真-
- 我< j
- i > a j
- a i = a j
算法
procedure ENUM_SORTING (n)
begin
for each process P1,j do
C[j] := 0;
for each process Pi, j do
if (A[i] < A[j]) or A[i] = A[j] and i < j) then
C[j] := 1;
else
C[j] := 0;
for each process P1, j do
A[C[j]] := A[j];
end ENUM_SORTING
奇偶换位排序
奇偶转置排序基于气泡排序技术。如果第一个数字大于第二个数字,它将比较两个相邻的数字并切换它们,以获取升序列表。相反的情况适用于降序序列。奇偶转置排序分为两个阶段-奇数阶段和偶数阶段。在两个阶段中,进程都会在右侧与其相邻编号交换编号。
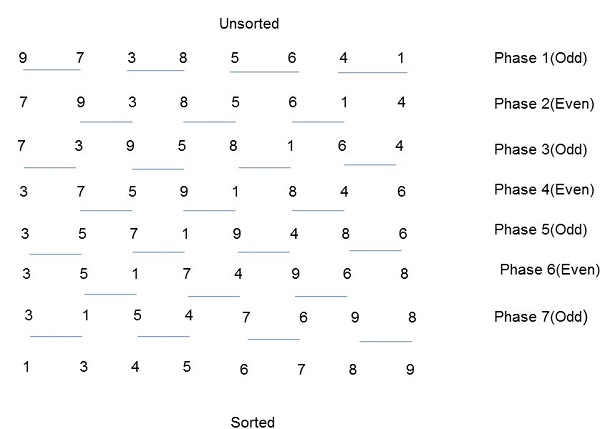
算法
procedure ODD-EVEN_PAR (n)
begin
id := process's label
for i := 1 to n do
begin
if i is odd and id is odd then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
if i is even and id is even then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
end for
end ODD-EVEN_PAR
并行合并排序
合并排序首先将未排序的列表划分为可能的最小子列表,将其与相邻列表进行比较,然后按排序顺序进行合并。通过遵循分而治之算法,它可以很好地实现并行性。

算法
procedureparallelmergesort(id, n, data, newdata)
begin
data = sequentialmergesort(data)
for dim = 1 to n
data = parallelmerge(id, dim, data)
endfor
newdata = data
end
超快速排序
超快速排序是对超多维数据集的快速排序的实现。其步骤如下-
- 在每个节点之间划分未排序的列表。
- 在本地对每个节点进行排序。
- 从节点0广播中间值。
- 在本地拆分每个列表,然后在最大维度上交换两半。
- 并行重复执行步骤3和4,直到尺寸达到0。
算法
procedure HYPERQUICKSORT (B, n)
begin
id := process’s label;
for i := 1 to d do
begin
x := pivot;
partition B into B1 and B2 such that B1 ≤ x < B2;
if ith bit is 0 then
begin
send B2 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B1 U C;
endif
else
send B1 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B2 U C;
end else
end for
sort B using sequential quicksort;
end HYPERQUICKSORT