📅 最后修改于: 2020-12-13 15:14:41 🧑 作者: Mango
要正确应用任何算法,选择合适的数据结构非常重要。这是因为与对另一数据结构执行的相同操作相比,对数据结构执行的特定操作可能会花费更多时间。
示例-要使用数组访问集合中的第i个元素,可能需要花费恒定的时间,但是通过使用链表,执行相同操作所需的时间可能变为多项式。
因此,必须考虑要执行的操作的体系结构和类型来完成数据结构的选择。
以下数据结构是并行编程中常用的-
- 链表
- 数组
- 超立方体网络
链表
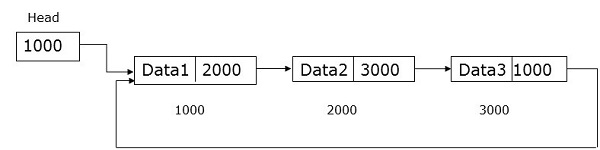
链表是一种数据结构,具有零个或多个通过指针连接的节点。节点可能会或可能不会占用连续的内存位置。每个节点都有两个或三个部分-一个数据部分存储数据,另外两个是链接字段,存储前一个或下一个节点的地址。第一个节点的地址存储在称为head的外部指针中。最后一个节点,称为tail,通常不包含任何地址。
链表有三种类型-
- 单链表
- 双链表
- 通报链表
单链表
单链列表的一个节点包含数据和下一个节点的地址。名为head的外部指针存储第一个节点的地址。

双链表
双向链表的节点包含数据和上一个节点和下一个节点的地址。称为head的外部指针存储第一个节点的地址,称为tail的外部指针存储最后一个节点的地址。

通报链表
循环链表与单链表非常相似,不同之处在于最后一个节点保存了第一个节点的地址。
数组
数组是一种数据结构,我们可以在其中存储相似类型的数据。它可以是一维或多维的。可以静态或动态创建数组。
-
在静态声明的数组中,在编译时已知数组的尺寸和大小。
-
在动态声明的数组中,运行时已知数组的尺寸和大小。
对于共享内存编程,可以将数组用作公用内存,对于数据并行编程,可以将其划分为子数组来使用。
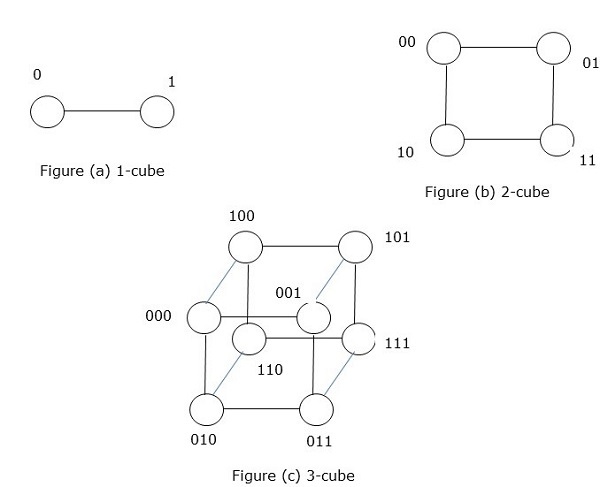
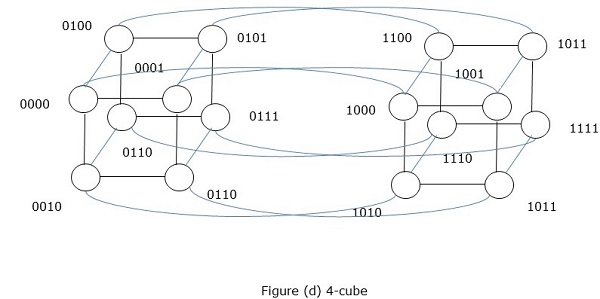
超立方体网络
Hypercube体系结构对于其中每个任务必须与其他任务进行通信的那些并行算法很有帮助。 Hypercube拓扑可以轻松嵌入其他拓扑,例如环形和网格。也称为n立方体,其中n是维数。可以递归构造一个超立方体。