- 数据挖掘中的KDD流程(1)
- 数据挖掘中的KDD流程
- 数据挖掘中的 KDD 过程
- 数据挖掘中的 KDD 过程(1)
- 数据挖掘:数据仓库流程
- 数据挖掘:数据仓库流程(1)
- 数据挖掘 | 2套
- 数据挖掘
- 数据挖掘(1)
- 数据挖掘 | 2套(1)
- 数据挖掘
- 工作流程流程(1)
- 工作流程流程
- 数据挖掘-问题
- 数据挖掘-问题(1)
- 流程,父流程和子流程之间的差异
- 流程,父流程和子流程之间的差异(1)
- 数据挖掘与大数据
- 数据挖掘与大数据(1)
- 文本数据挖掘(1)
- 文本数据挖掘
- 数据挖掘图和网络
- 数据挖掘图和网络(1)
- 数据挖掘套装2
- 数据挖掘套装2(1)
- 数据挖掘模型
- 数据挖掘模型
- 数据挖掘模型(1)
- 数据挖掘教程(1)
📅 最后修改于: 2020-12-21 09:47:06 🧑 作者: Mango
KDD-数据库中的知识发现
术语KDD代表数据库中的知识发现。它涉及发现数据知识的广泛过程,并强调了特定数据挖掘技术的高级应用。它是各个领域的研究人员感兴趣的领域,包括人工智能,机器学习,模式识别,数据库,统计信息,专家系统的知识获取以及数据可视化。
KDD流程的主要目标是在大型数据库的上下文中从数据中提取信息。它通过使用数据挖掘算法来识别什么被认为是知识。
数据库中的知识发现被认为是对大型数据存储库的编程,探索性分析和建模。KDD是从庞大和复杂的数据集中识别有效,有用和可理解的模式的组织过程。数据挖掘是KDD过程的基础,包括推断用于研究数据,开发模型并查找以前未知模式的算法。该模型用于从数据中提取知识,分析数据和预测数据。
如今,数据的可用性和丰富性使知识发现和数据挖掘成为具有重大意义和需求的问题。在该领域的最新发展中,专家和专家目前可以使用各种各样的技术也就不足为奇了。
KDD流程
知识发现过程(在给定图中进行说明)是迭代且交互的,包括九个步骤。该过程在每个阶段都是迭代的,这意味着可能需要返回到先前的操作。从一个人不能提出一个公式或对每个步骤和应用程序类型的正确决策进行完整的科学分类的意义上来说,该过程具有许多富有想象力的方面。因此,需要了解该过程以及每个阶段的不同要求和可能性。
该过程从确定KDD目标开始,到发现知识的实施结束。那时,循环关闭,并且活动数据挖掘开始。随后,将需要在应用程序域中进行更改。例如,向手机用户提供各种功能以减少流失。这样就结束了循环,然后对新数据存储库和KDD流程进行了评估。以下是九步KDD流程的简要描述,从管理步骤开始:
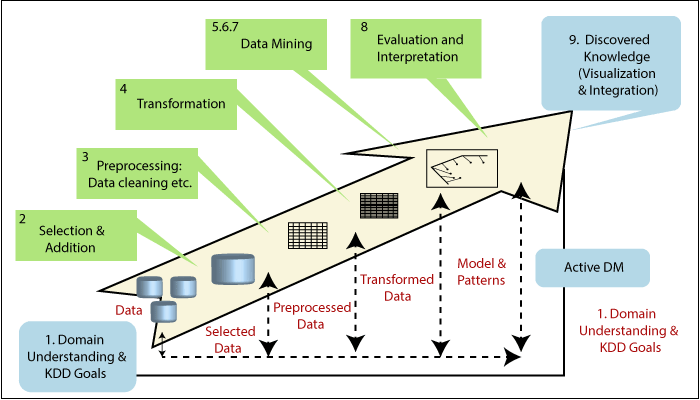
1.建立对应用程序领域的了解
这是初步的初步步骤。它为了解如何应对各种决策(例如转换,算法,表示形式等)而开发了一个场景。负责KDD风险投资的个人需要了解并描述最终用户的目标和所处环境的特征。知识发现过程将发生(涉及相关的先验知识)。
2.选择并创建将在其上执行发现的数据集
一旦定义了目标,就应该确定将用于知识发现过程的数据。这包括发现可访问的数据,获取重要数据,然后将所有用于知识发现的数据集成到一组中,这将涉及该过程要考虑的质量。由于数据挖掘从可访问的数据中学习和发现,因此此过程很重要。这是建立模型的证据基础。如果此时缺少一些重要的属性,则从这个方面来说,整个研究可能会失败,因此应考虑更多的属性。另一方面,组织,收集和操作高级数据存储库的成本很高,并且存在一种安排,可以最好地理解这种现象。这种安排是指KDD进行交互和迭代的方面。首先从最好的可用数据集开始,然后扩展并观察知识发现和建模方面的影响。
3.预处理和清洗
在此步骤中,提高了数据可靠性。它包含数据清除功能,例如,处理丢失的数量以及消除噪声或异常值。在这种情况下,它可能包括复杂的统计技术或使用数据挖掘算法。例如,当人们怀疑某个特定属性缺乏可靠性或数据丢失时,此时,该属性可能成为数据挖掘监督算法的目标。将创建这些属性的预测模型,然后,可以预测丢失的数据。人们关注这一水平的扩展取决于许多因素。无论如何,对方面的研究都是重要的,并定期向企业数据框架定期揭示。
4.数据转换
在此阶段,准备并开发了用于数据挖掘的适当数据的创建。这里的技术包括降维(例如,特征选择和提取以及记录采样),还包括属性变换(例如,数字属性的离散化和功能变换)。此步骤对于整个KDD项目的成功至关重要,并且通常是特定于项目的。例如,在医学评估中,属性的商通常可能是最重要的因素,而不是每个因素本身。在业务中,我们可能需要考虑超出我们控制范围的影响以及努力和暂时性问题。例如,研究广告积累的影响。但是,如果我们在一开始没有使用正确的转换,那么我们可能会获得惊人的效果,使我们了解到下一次迭代所需的转换。因此,KDD过程紧随其后,并促使人们了解所需的转换。
5.预测与描述
现在,我们准备决定要使用哪种数据挖掘,例如,分类,回归,聚类等。这主要取决于KDD目标以及先前的步骤。数据挖掘有两个重要的目标,第一个是预测,第二个是描述。预测通常称为有监督的数据挖掘,而描述性数据挖掘则结合了数据挖掘的无监督和可视化方面。大多数数据挖掘技术都依赖归纳学习,即通过从足够数量的准备模型中进行概括来显式或隐式地构建模型。归纳法的基本假设是,准备好的模型适用于将来的案例。该技术还考虑了特定的可访问数据集的元学习级别。
6.选择数据挖掘算法
有了技术,我们现在就决定策略。这个阶段包括选择一种特定的技术来搜索包括多个诱导子的模式。例如,考虑到精度与可理解性,前者在神经网络中更好,而后者在决策树中更好。对于每种元学习系统,都有几种成功的可能性。元学习的重点是弄清楚是什么导致数据挖掘算法在特定问题上取得成功或失败。因此,该方法论试图了解一种最适合使用数据挖掘算法的情况。每种算法都有倾斜的参数和策略,例如十倍交叉验证或用于训练和测试的另一部分。
7.利用数据挖掘算法
最后,实现了数据挖掘算法的实现。在此阶段,我们可能需要多次使用该算法,直到获得令人满意的结果。例如,通过旋转算法控制参数,例如决策树的单个叶子中的最小实例数。
8.评估
在此步骤中,我们评估并解释了第一步所描述的目标的挖掘模式,规则和可靠性。在这里,我们考虑预处理步骤对数据挖掘算法结果的影响。例如,在步骤4中包含功能,然后从那里重复。此步骤侧重于诱导模型的可理解性和实用性。在此步骤中,还将记录识别出的知识,以备将来使用。最后一步是使用数据挖掘,并获得总体反馈和发现结果。
9.使用发现的知识
现在,我们准备将知识包含到另一个系统中以进行进一步的活动。在我们可以对系统进行更改并衡量影响的意义上,知识变得有效。此步骤的完成决定了整个KDD流程的有效性。在这一步骤中存在许多挑战,例如失去了我们工作所依据的“实验室条件”。例如,知识是从某个静态描述中发现的,通常是一组数据,但是现在数据变为动态的。数据结构可能会更改某些数量而变得不可用,并且数据域可能会被修改,例如属性可能具有先前未预期的值。