- Apache Kafka Producer
- Apache Kafka Producer(1)
- Confluent Kafka Python Producer 简介
- 创建Twitter Producer(1)
- 创建Twitter Producer
- 创建Kafka主题(1)
- kafka 创建主题 (1)
- 创建Kafka主题
- Kafka使用Java编程
- Kafka使用Java编程(1)
- kafka 创建主题 - 任何代码示例
- 你需要为 kafka 安装 java - Java (1)
- 用Java创建Kafka使用者(1)
- 用Java创建Kafka使用者
- 你需要为 kafka 安装 java - Java 代码示例
- Kafka流处理(1)
- Kafka流处理
- Kafka安全(1)
- Kafka安全
- 在Linux上安装Kafka(1)
- 在Linux上安装Kafka
- Kafka主题
- Kafka主题(1)
- kafka nodejs 示例 (1)
- 安装Apache Kafka
- 安装Apache Kafka(1)
- Kafka实时示例(1)
- Kafka实时示例
- kafka 删除主题 (1)
📅 最后修改于: 2021-01-05 02:52:44 🧑 作者: Mango
用Java创建Kafka Producer
在上一节中,我们学习了创建Kafka项目的基本步骤。现在,在用Java创建Kafka生产者之前,我们需要定义基本的Project依赖项。在我们的项目中,将需要两个依赖项:
- kafka 依赖
- 记录依赖项,即SLF4J Logger。
设置依赖关系需要执行以下步骤:
步骤1:构建工具Maven包含一个“ pom.xml ”文件。 “ pom.xml”是默认XML文件,其中包含有关GroupID,ArtifactID以及Version值的所有信息。用户需要在“ pom.xml”文件中定义所有必要的项目依赖项。转到“ pom.xml”文件。
步骤2:首先,我们需要定义Kafka依赖关系。创建一个'
步骤3:现在,打开网络浏览器并搜索“ Kafka Maven”,如下所示:
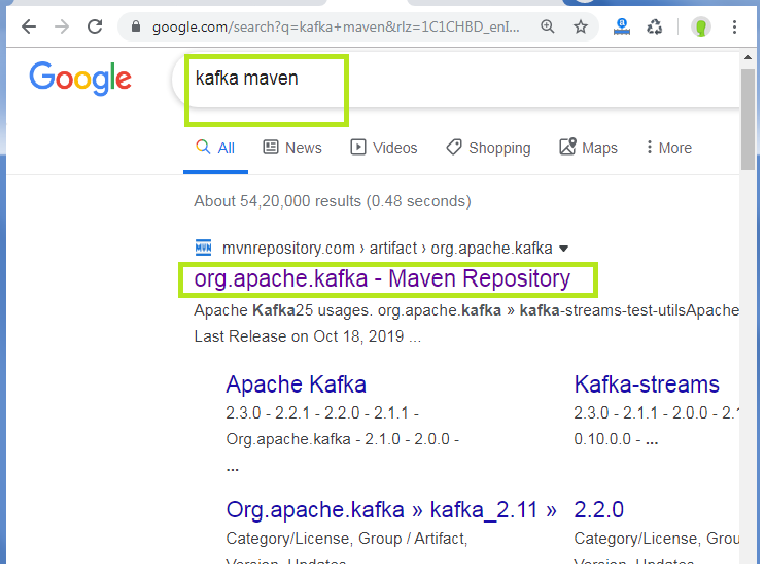
单击突出显示的链接,然后选择“ Apache Kafka,Kafka-Clients ”存储库。以下快照显示了一个示例:
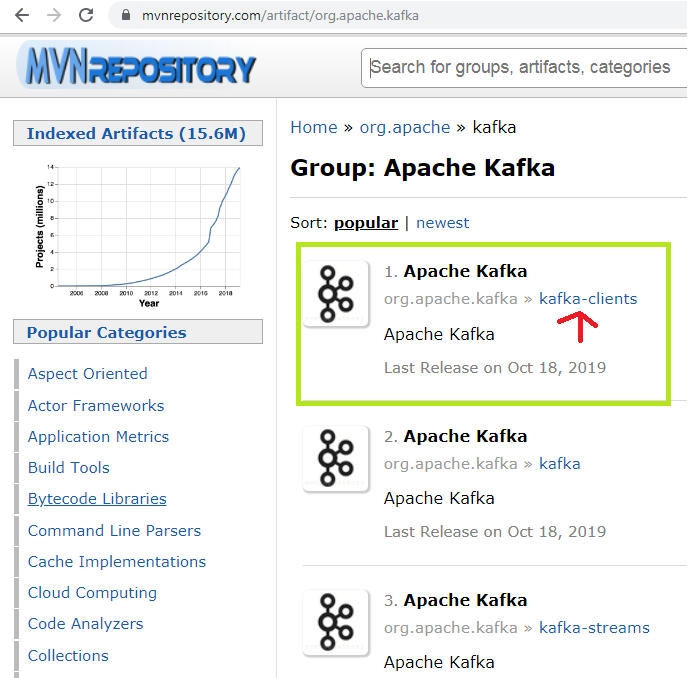
步骤4:根据系统上下载的Kafka版本选择存储库版本。例如,在本教程中,我们使用的是“ Apache Kafka 2.3.0”。因此,我们需要存储库版本2.3.0(突出显示的版本)。
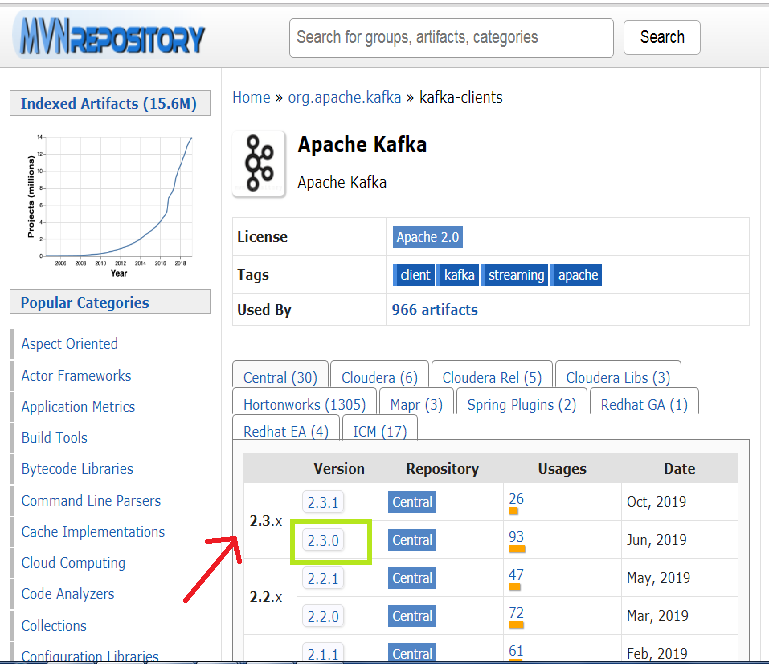
步骤5:点击存储库版本后,将打开一个新窗口。从那里复制依赖关系代码。
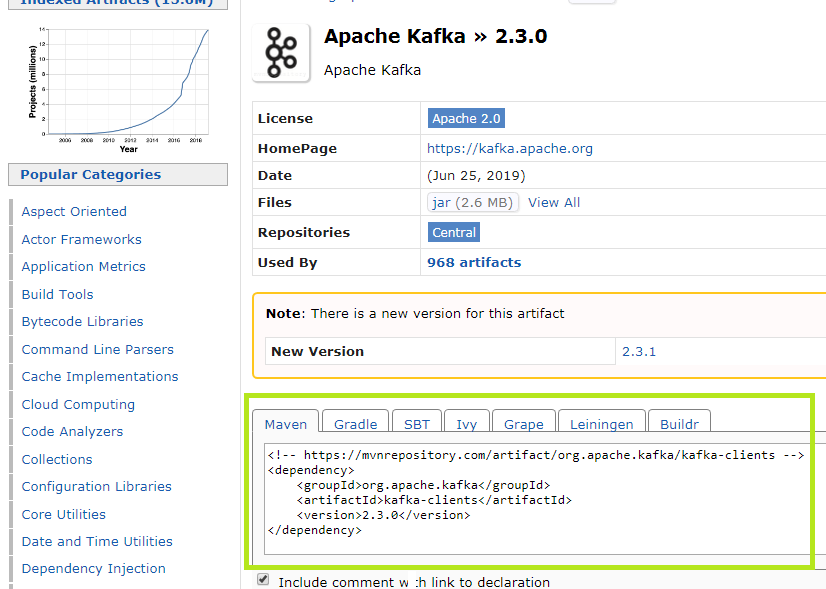
由于我们正在使用Maven,因此请复制Maven代码。如果用户使用Gradle,请复制Gradle编写的代码。
步骤6:将复制的代码粘贴到'
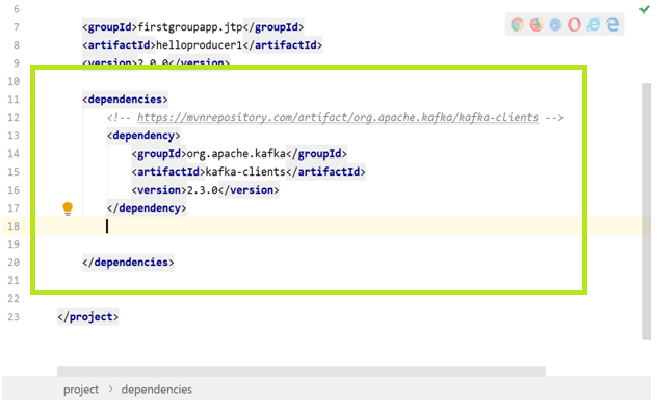
如果版本号显示为红色,则表示用户错过了启用“自动导入”选项的权限。如果是这样,请转到“视图”>“工具Windows”>“ Maven” 。 Maven项目窗口将出现在屏幕的右侧。单击出现在此处的“刷新”按钮。这将启用丢失的自动导入Maven项目。如果颜色变为黑色,则表示已下载缺少的依赖项。用户可以继续下一步。
步骤7:现在,打开Web浏览器并搜索“ SL4J Simple”,然后打开以下快照中所示的突出显示的链接:
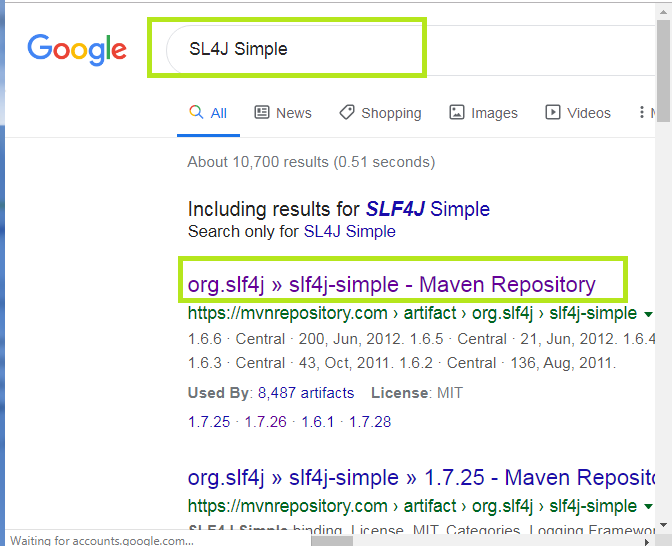
一堆存储库将出现。单击适当的存储库。

要了解适当的存储库,请查看Maven项目窗口,并在“依赖关系”下查看slf4j版本。
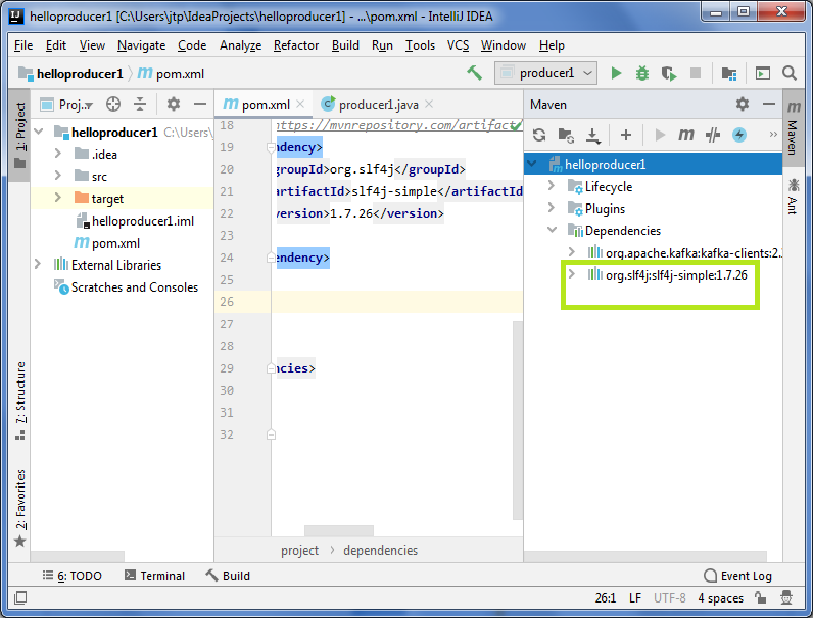
单击适当的版本并复制代码,然后将其粘贴在“ pom.xml”文件中的Kafka依赖项下方,如下所示:
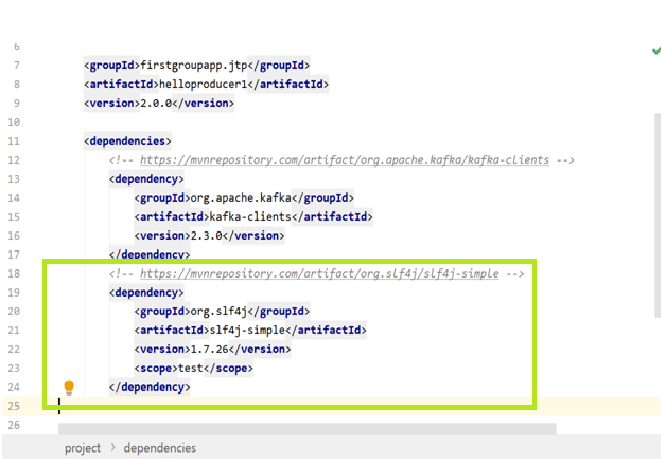
注意:您可以发表评论或删除
现在,我们已经设置了所有必需的依赖项。让我们尝试“简单的Hello World”示例。
首先,创建一个名为“ com.firstgroupapp.aktutorial”的Java包,并在其下方创建一个Java类。创建Java软件包时,请遵循软件包命名约定。最后,创建“ hello world”程序。
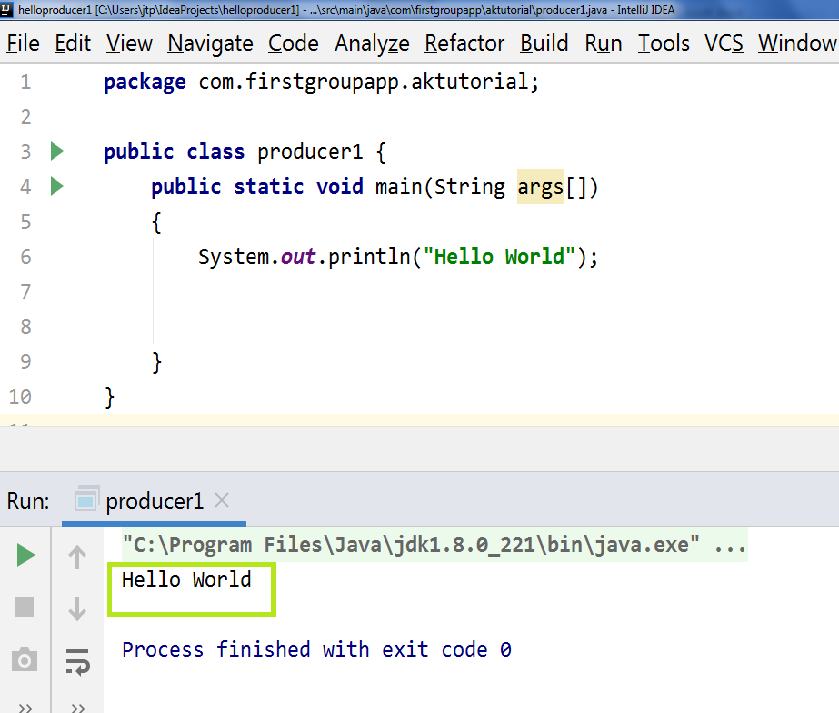
执行'producer1.java'文件后,输出成功显示为'Hello World'。这说明IntelliJ IDEA的成功工作。
创建Java生产者
基本上,创建Java生产者有四个步骤,如前所述:
- 创建生产者属性
- 创建生产者
- 创建生产者记录
- 发送数据。
创建生产者属性
Apache Kafka提供了用于创建生产者的各种Kafka属性。要了解每个属性,请访问Apache的官方网站,即“ https://kafka.apache.org ”。移至Kafka>文档>配置>生产者配置。
在那里,用户可以了解Apache Kafka提供的所有生产者属性。在这里,我们将讨论所需的属性,例如:
- bootstrap.servers:这是端口对的列表,用于建立与Kafka集群的初始连接。用户只能将引导服务器用于建立初始连接。该服务器以host:port,host:port等形式存在。
- key.serializer:它是密钥的一种Serializer类,用于实现“ org.apache.kafka.common.serialization.Serializer”接口。
- value.serializer:这是一种Serializer类,它实现“ org.apache.kafka.common.serialization.Serializer”接口。
现在,让我们看看IntelliJ IDEA中生产者属性的实现。
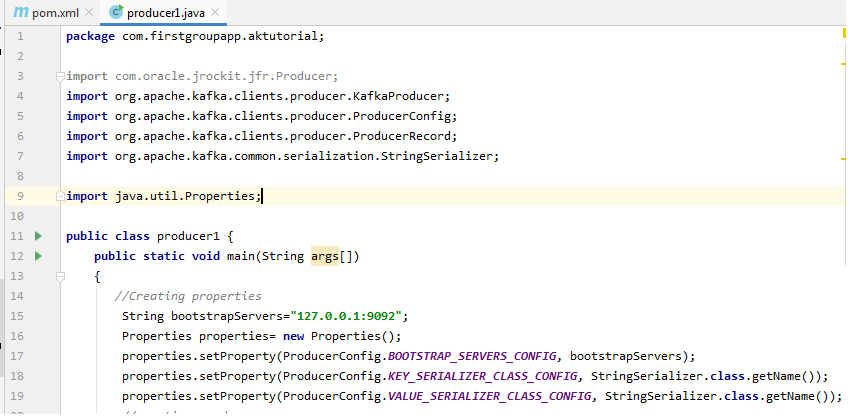
当我们创建属性时,它将“ java.util.Properties ”导入到代码中。
这样,创建生产者属性的第一步就完成了。
创建生产者
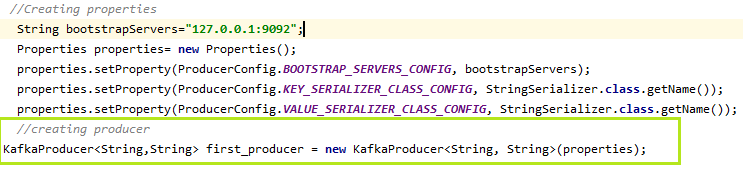
要创建一个Kafka生产者,我们只需要创建一个KafkaProducer对象。
KafkaProducer的对象可以创建为:
KafkaProducer first_producer = new KafkaProducer(properties);
在这里,“ first_producer ”是我们选择的生产者的名称。用户可以据此进行选择。
让我们在下面的快照中看到:
创建生产者记录
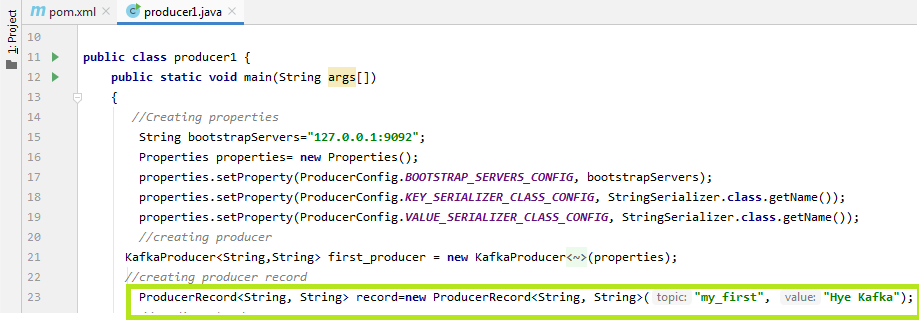
为了将数据发送到Kafka,用户需要创建一个ProducerRecord。这是因为所有生产者都位于生产者记录内。生产者在此处指定主题名称以及要传递给Kafka的消息。
可以通过以下方式创建ProducerRecord:
ProducerRecord record=new ProducerRecord("my_first", "Hye Kafka");
在这里,“记录”是用于创建生产者记录的名称,“ my_first”是主题名称,“ Hye Kafka”是消息。用户可以据此进行选择。
让我们在下面的快照中看到:
发送数据
现在,用户已准备好将数据发送到Kafka。生产者只需要按以下方式调用ProducerRecord的对象:
first_producer.send(record);
让我们在下面的快照中看到:

要了解上述代码的输出,请使用以下命令在CLI上打开“ kafka-console-consumer”:
' kafka-console-consumer -bootstrap-server 127.0.0.1:9092 -topic my_first -group first_app '
生产者产生的数据是异步的。因此,需要两个附加函数,即flush()和close() (如上图所示)。 flush()将强制生成所有数据,而close()将停止生产器。如果不执行这些功能,则数据将永远不会发送到Kafka,并且消费者将无法读取它。
下面将使用者控制台上的代码输出显示为:
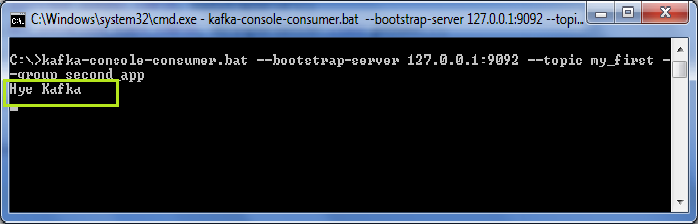
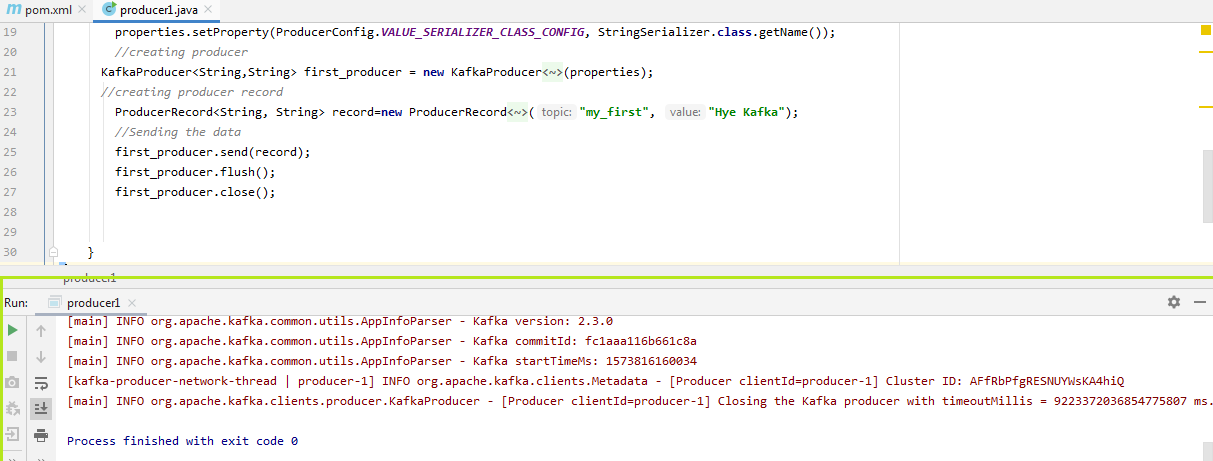
在终端上,用户可以看到各种日志文件。航站楼的最后一行说, kafka 生产商已经关闭。因此,该消息将异步显示在使用者控制台上。