将大型 R 数据帧拆分为较小的数据帧列表
在本文中,我们将讨论如何将大型 R 数据帧拆分为较小的数据帧列表。在 R 编程语言中,我们有一个名为 split() 的函数,用于将数据帧拆分为多个部分。
为此,我们首先创建一个需要拆分的数据帧示例。
创建数据框:
R
# create the data frame
data <- data.frame(id = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
x1 = 11 : 20,
x2 = 110 : 110)
# print the dataframe
dataR
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the dataframe using the
# split function
split_data <- split(data, f = data)
# print the splitted data frame
split_dataR
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f = data$a1)
# print the split data
split_dataR
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = c(1, 1, 1, 2, 2, 2,
1, 2, 1, 2),
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f=list(data$a1, data$a2))
# print the split data
split_data输出:

要拆分上述数据帧,我们使用split()函数。 split()函数的语法是:
Syntax: split(x, f, drop = FALSE, …)
Parameters:
- x stands for DataFrame and vector
- f stands for grouping of vector or selecting the column according to which we split the Dataframe
- drop stands for delete or skip the specified row
示例 1:在此示例中,我们尝试在没有任何参数的情况下运行 split函数,除了上述 Dataframe。
当我们在没有任何参数的情况下运行 split函数,除了 dataframe 我们注意到 split函数返回第 1 列的每个元素与其他列的组合。在我们的例子中,第 1 列中有 3 个不同的元素,数据框中总共有 10 行。因此,在我们的输出中,作为输出的总行数为 3 * 10 = 30 行。
电阻
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the dataframe using the
# split function
split_data <- split(data, f = data)
# print the splitted data frame
split_data
输出:

注意:以上输出截图是实际输出的1/3,为简洁我们无法插入完整的输出截图。
示例 2:在本示例中,我们将借助 1 列进行分组来拆分 Dataframe。
为此,我们将使用 split函数的“f”参数,“$”用于选择我们将根据其拆分 Dataframe 的列。在我们的例子中,我们将根据 a1 列拆分 Dataframe。
电阻
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f = data$a1)
# print the split data
split_data
输出:

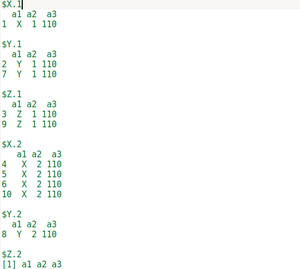
示例 3:在本示例中,我们将借助 2 列分组来拆分数据框。
为此,我们将使用 split函数的“f”参数,“$”用于选择列并列出我们将根据其拆分 Dataframe 的列。在我们的例子中,我们将根据 a1 和 a2 列拆分 Dataframe。因此,创建了 a1 和 a2 的列表,并将该列表作为“f”的参数给出。
电阻
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = c(1, 1, 1, 2, 2, 2,
1, 2, 1, 2),
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f=list(data$a1, data$a2))
# print the split data
split_data
输出: