- 数据结构 |哈希|问题 5(1)
- 数据结构 |哈希|问题2(1)
- 数据结构 |哈希|问题 3
- 数据结构 |哈希|问题2
- 数据结构 |哈希|问题 5
- 数据结构 |哈希|问题 4
- 数据结构 |哈希|问题 1
- 数据结构 |哈希|问题 1(1)
- 数据结构 |哈希|问题 4(1)
- 数据结构和算法 | 8套(1)
- 数据结构和算法 |组5(1)
- 数据结构和算法-树(1)
- 数据结构和算法 | 6套(1)
- 数据结构和算法 | 2套(1)
- 数据结构和算法 |组5
- 数据结构和算法 | 7套
- 数据结构和算法 | 6套
- 数据结构与算法
- 数据结构与算法(1)
- 数据结构和算法 | 8套
- 数据结构和算法 | 2套
- 数据结构和算法-树
- python中的数据结构和算法(1)
- 数据结构和算法-数组(1)
- 数据结构和算法-数组
- python代码示例中的数据结构和算法
- 数据结构和算法 |设置 9
- 数据结构和算法 |设置 3(1)
- 数据结构和算法 |设置 1(1)
📅 最后修改于: 2021-01-11 10:19:58 🧑 作者: Mango
哈希表是一种以关联方式存储数据的数据结构。在哈希表中,数据以数组格式存储,其中每个数据值都有其自己的唯一索引值。如果我们知道所需数据的索引,则数据访问将变得非常快。
因此,它成为一种数据结构,其中插入和搜索操作非常快,而与数据的大小无关。哈希表使用数组作为存储介质,并使用哈希技术生成要在其中插入元素或从中定位元素的索引。
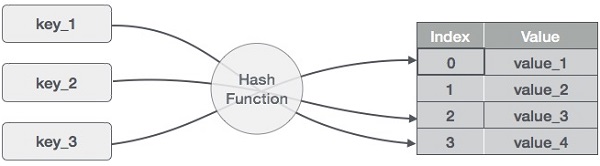
散列
散列是一种将键值范围转换为数组索引范围的技术。我们将使用模运算符来获取一系列键值。考虑一个大小为20的哈希表的示例,以下各项将被存储。项目采用(键,值)格式。
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
线性探测
如我们所见,可能会发生这种情况,即使用哈希技术来创建数组的已使用索引。在这种情况下,我们可以通过查看下一个单元格直到找到一个空单元格来搜索数组中的下一个空单元。这种技术称为线性探测。
| Sr.No. | Key | Hash | Array Index | After Linear Probing, Array Index |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
基本操作
以下是哈希表的基本基本操作。
-
搜索-搜索哈希表中的元素。
-
插入-在哈希表中插入一个元素。
-
删除-删除一个哈希表的元素。
数据项
定义具有一些数据和关键字的数据项,基于该数据项和关键字将在哈希表中进行搜索。
struct DataItem {
int data;
int key;
};
哈希方法
定义一种哈希方法来计算数据项键的哈希码。
int hashCode(int key){
return key % SIZE;
}
搜索操作
每当要搜索元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位元素。如果在计算的哈希码中找不到元素,请使用线性探测使该元素领先。
例
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
插入操作
每当要插入元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位索引。如果在计算的哈希码中找到了元素,则对空位置使用线性探测。
例
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
删除操作
每当要删除元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来找到索引。如果在计算的哈希码中找不到元素,请使用线性探测使该元素领先。找到后,在其中存储一个虚拟项目以保持哈希表的性能不变。
例
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
要了解使用C编程语言实现的哈希实现,请单击此处。