- TensorFlow-单层感知器(1)
- TensorFlow中的单层感知器(1)
- TensorFlow中的隐藏层感知器
- TensorFlow中的多层感知器(1)
- TensorFlow中的多层感知器
- R 编程中的单层神经网络(1)
- R 编程中的单层神经网络
- Tensorflow 中的多层感知器学习(1)
- TensorFlow-多层感知器学习(1)
- TensorFlow-多层感知器学习
- Tensorflow 中的多层感知器学习
- PyTorch感知器(1)
- PyTorch感知器
- 非逻辑门感知器算法的实现(1)
- 非逻辑门感知器算法的实现
- TensorFlow 2.0
- TensorFlow 2.0(1)
- TensorFlow 2.0(1)
- TensorFlow 2.0
- 具有3位二进制输入的逻辑门的感知器算法(1)
- 具有3位二进制输入的逻辑门的感知器算法
- 2位二进制输入或逻辑门感知器算法的实现(1)
- 2位二进制输入与逻辑门感知器算法的实现(1)
- 2位二进制输入或逻辑门感知器算法的实现
- 2位二进制输入与逻辑门感知器算法的实现
- 带有 Keras 的多层感知器 带有 Keras 的多层感知器 (1)
- tensorflow - Python (1)
- 带有 Keras 的多层感知器 带有 Keras 的多层感知器 - 无论代码示例
- PyTorch感知器模型|模型设置(1)
📅 最后修改于: 2021-01-11 10:31:04 🧑 作者: Mango
TensorFlow中的单层感知器
感知器是任何神经网络的单个处理单元。 1958年首先提出的弗兰克·罗森布拉特(Frank Rosenblatt)是一种简单的神经元,用于将其输入分为一到两个类别。 Perceptron是线性分类器,用于监督学习中。它有助于组织给定的输入数据。
感知器是进行精确计算以检测输入数据中的特征的神经网络单元。 Perceptron主要用于将数据分为两部分。因此,它也被称为线性二进制分类器。
如果其输入0和-1的加权和,Perceptron使用返回+1的步进函数。
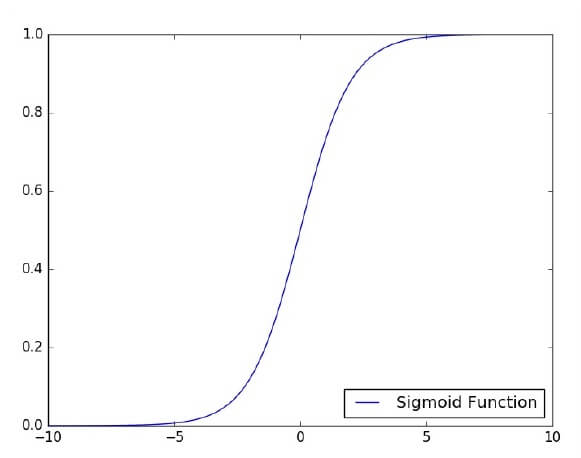
激活函数用于在所需值(如(0,1)或(-1,1))之间映射输入。
常规的神经网络如下所示:
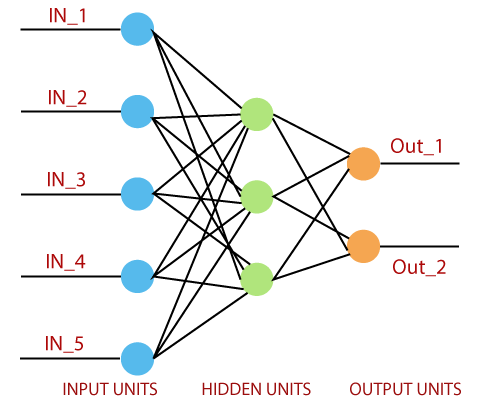
感知器包括4个部分。
- 输入值或一个输入层:感知器的输入层由人工输入神经元组成,并将初始数据带入系统中进行进一步处理。
- 权重和偏差:权重:它表示单元之间连接的尺寸或强度。如果从节点1到节点2的权重较大,则神经元1对神经元的影响更大。偏差:与线性方程式中添加的截距相同。这是一个附加参数,其任务是修改输出以及到另一个神经元的输入的加权和。
- 净额:计算总和。
- 激活功能:神经元是否可以激活,取决于激活函数。激活函数计算加权和,并进一步加上偏差以得出结果。
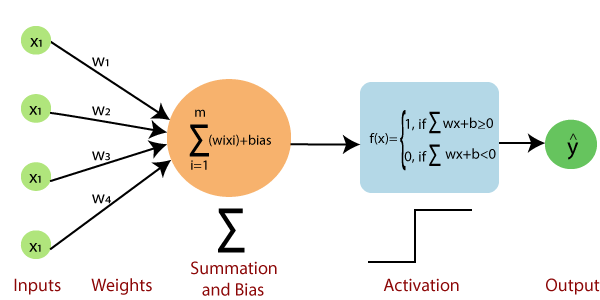
标准的神经网络如下图所示。
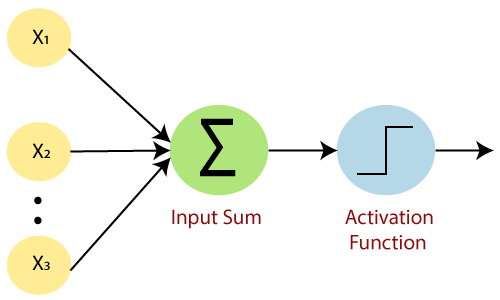
它是如何工作的?
感知器执行以下简单步骤:
一种。第一步,将所有输入x乘以它们的权重w 。
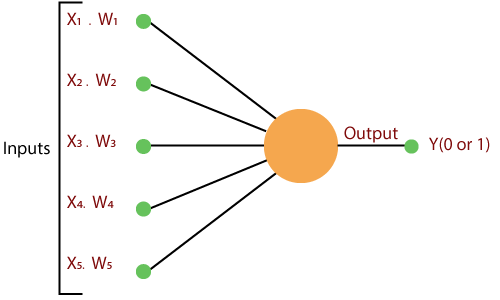
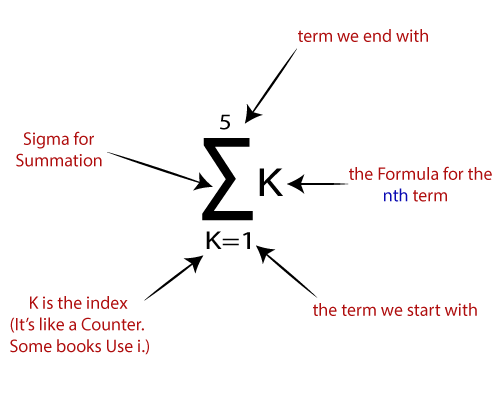
b。在此步骤中,将所有增加的值相加,并将它们称为“加权和” 。
C。在我们的最后一步中,将加权和应用于正确的激活函数。
例如:
单位步进激活功能
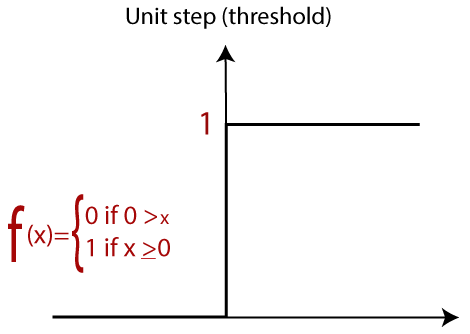
有两种类型的体系结构。这些类型集中在人工神经网络的功能上,如下所示:
- 单层感知器
- 多层感知器
单层感知器
单层感知器是第一个神经网络模型,由Frank Rosenbluth于1958年提出。它是最早的学习模型之一。我们的目标是找到由权重向量w和偏差参数b度量的线性决策函数。
要了解感知器层,必须理解人工神经网络(ANN)。
人工神经网络(ANN)是一种信息处理系统,其机制受生物神经电路的功能启发。人工神经网络由多个相互连接的处理单元组成。
这是建立神经模型时的第一个建议。神经元局部记忆的内容包含权重向量。
通过计算输入向量的总和乘以向量的相应元素,可以计算出单个向量感知器,并且每个向量的权重都按重量增加。输出中显示的值是激活函数的输入。
让我们专注于使用TensorFlow解决图像分类问题的单层感知器的实现。绘制单层感知器的最佳示例是通过“逻辑回归”的表示。
现在,我们必须执行以下必要的逻辑回归训练步骤-
- 在每次训练开始时,使用随机值初始化权重。
- 对于训练集的每个元素,将使用所需输出与实际输出之间的差来计算误差。计算出的误差用于调整重量。
- 重复该过程,直到整个训练集上的故障小于指定的限制,直到达到最大迭代次数为止。
单层感知器的完整代码
# Import the MINST dataset
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_ ("/tmp/data/", one_hot=True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [none, 784]) # MNIST data image of shape 28*28 = 784
y = tf.placeholder("float", [none, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Constructing the model
activation=tf.nn.softmaxx(tf.matmul (x, W)+b) # Softmax
of function
# Minimizing error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy, reduction_indice = 1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables where init = tf.initialize_all_variables()
# Launching the graph
with tf.Session() as sess:
sess.run(init)
# Training of the cycle in the dataset
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_example/batch_size)
# Creating loops at all the batches in the code
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fitting the training by the batch data sess.run(optimizr, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute all the average of loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys}) //total batch
# Display the logs at each epoch steps
if epoch % display_step==0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format (avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
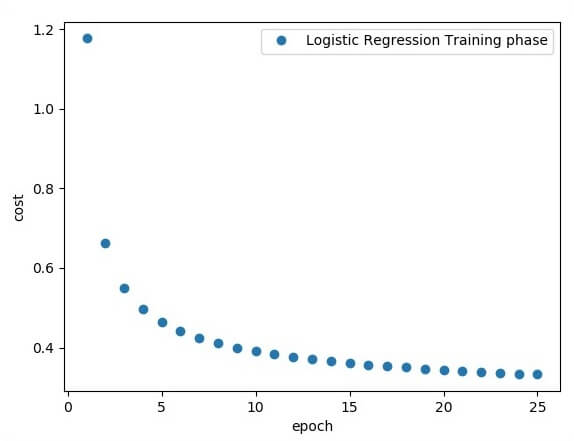
print ("Training phase finished")
plt.plot(epoch_set,avg_set, 'o', label = 'Logistics Regression Training')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test the model
correct_prediction = tf.equal (tf.argmax (activation, 1),tf.argmax(y,1))
# Calculating the accuracy of dataset
accuracy = tf.reduce_mean(tf.cast (correct_prediction, "float")) print
("Model accuracy:", accuracy.eval({x:mnist.test.images, y: mnist.test.labels}))
代码的输出:
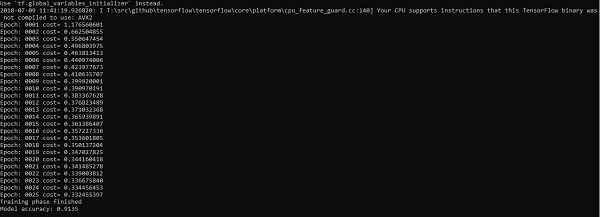
逻辑回归被视为预测分析。 Logistic回归主要用于描述数据并用于解释因变量和一个或多个名义或自变量之间的关系。
注意:权重显示特定节点的强度。