- Teradata-加入策略
- Teradata-加入策略(1)
- SQL |联接(内联接、左联接、右联接和完全联接)
- SQL |联接(内联接、左联接、右联接和完全联接)(1)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)(1)
- 左联接和右联接之间的区别
- SQL |联接(笛卡尔联接和自联接)(1)
- SQL |联接(笛卡尔联接和自联接)(1)
- SQL |联接(笛卡尔联接和自联接)
- SQL |联接(笛卡尔联接和自联接)
- Teradata(1)
- Teradata宏(1)
- Teradata-表
- Teradata-宏
- Teradata-宏(1)
- Teradata表(1)
- Teradata-表(1)
- Teradata(1)
- Teradata表
- Teradata
- Teradata
- Teradata
- Teradata宏
- SQL左联接(1)
- SQL左联接
- T-SQL-联接表
- T-SQL-联接表(1)
- MS SQL Server中的左联接和右联接(1)
📅 最后修改于: 2021-01-11 11:38:23 🧑 作者: Mango
Teradata加盟策略
优化器使用Teradata联接策略来选择最低成本计划和更好的性能。
将根据优化器可用的信息(例如表大小,PI信息和统计信息)来选择策略。
Teradata联接策略为以下类型:
- 合并(排除)
- 巢状
- 行哈希
产品
合并加入策略
当联接基于相等条件时,将发生合并联接方法。
合并联接要求联接行位于同一AMP上。根据行的哈希将行合并。
合并联接基于重新分配使用四种不同的合并联接策略,以将行带到同一AMP。
策略1
第一个合并联接将在联接条件下利用两个表上的主索引。
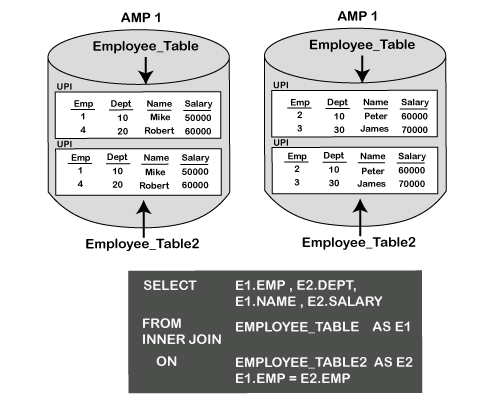
上面的内部联接着重于两个表之间匹配时返回所有行。
ON子句很重要,因为此联接建立了联接(相等)条件。
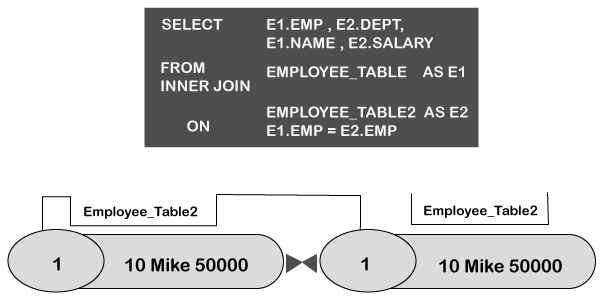
从JOIN中的ON子句声明Emp = Emp的地方,将连接每个匹配的行。
EMP是两个表的主索引。第一种合并联接类型非常有效,因为ON子句中的两个列都是其各自表的主索引。发生这种情况时,无需将任何数据移入线轴,并且可以在所谓的AMP LOCAL中执行联接。
Teradata可以快速执行此连接,并且完成移动所需的数据更少。
策略2
当对一个表的主索引列执行到另一表的非主索引列的联接时,将使用此策略。
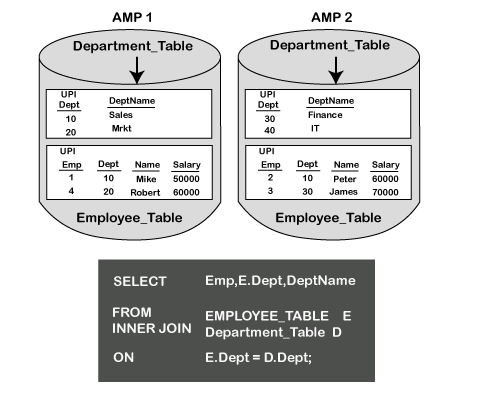
根据DEPT列将两个表联接在一起。在部门表中,“主要索引”列为DEPT。
员工表具有EMP作为主要索引列。主要目的是将来自每个表的行放在同一AMP上。
Teradata Optimizer可以选择几个选项来完成此任务,例如:
- 第一种选择是在所有AMP上复制较小的表。
- 第二种选择是使部门表的相等条件匹配在AMP的主索引列上保持不变。
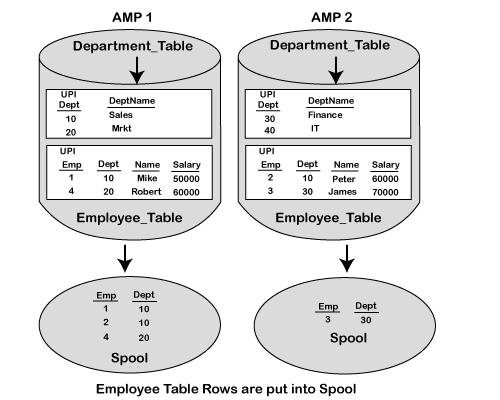
- 下一步将是将行从Employee表移到假脱机中。这可以通过散列(定位)employee表中的列,然后将这些行转移到假脱机到部门表行所在的适当AMP来完成。
策略3
在两个表都未连接到两个表的主索引上的情况下使用。在这种情况下,Teradata将把这两个表重新分配到假脱机中,并按哈希码对它们进行排序。
当我们想通过哈希码重新分配和排序时,我们只对非主索引列进行哈希处理,然后将它们移到AMP后台处理程序中,并按哈希对它们进行排序。
完成此操作后,所有AMP上的适当行将一起放到后台处理中。
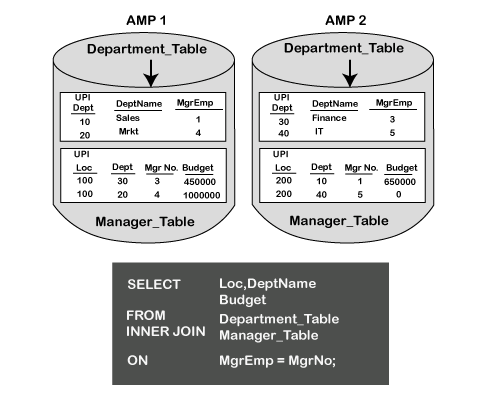
部门表的主索引是DEPT,管理器表的主索引是LOC。在这种情况下,在此联接相等中使用的两个列都不是主索引列的一部分。
由于在ON子句中选择的列都不是各个表的主索引,因此需要重新整理两个表中的行并将其重新分配到SPOOL中。因此,将根据ON子句列重新分配两个表。

此过程的下一步是重新分配行,并将其定位到匹配的AMP。
完成此操作后,两个表中的行将位于两个不同的线轴中。每个线轴中的行将连接在一起以带回匹配的行。
合并加入策略4
第四种合并联接策略称为大表-小表联接。如果要连接的表中的一个较小,则Teradata可以选择一个计划,该计划将在所有AMP中复制较小的表。
该策略的关键在于,无论表是否是“主索引列”的一部分,Teradata仍可以选择在所有AMP中复制该表。
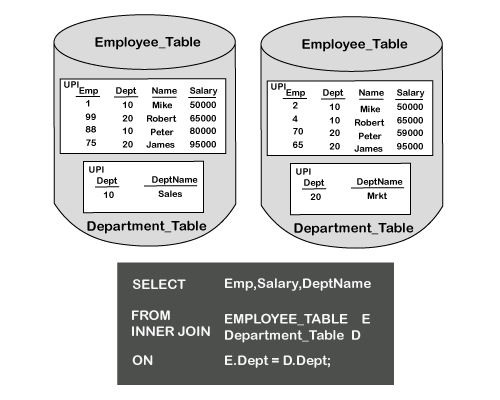
联接中涉及的两个表是Employee表和Department表。
Dept列是在两个表之间进行匹配的联接相等性。
DEPT列是“部门”表中的“主索引”列。
Employee表具有Emp列作为主索引。部门表很小。
要将这两个表连接在一起:
- 第一步是在同一AMP上将行放在一起。在这种情况下,由于Department表很小,因此Teradata将选择将每个AMP上的整个Department表复制到一个线轴中。
- 然后,AMP将基本Employee行与Department行联接在一起。

嵌套连接
嵌套连接旨在利用来自joint语句中的表之一的唯一索引类型(唯一主索引或唯一二级索引)来检索单个行。
然后,将该行与联接中使用的另一张表上的一个或多个行进行匹配。
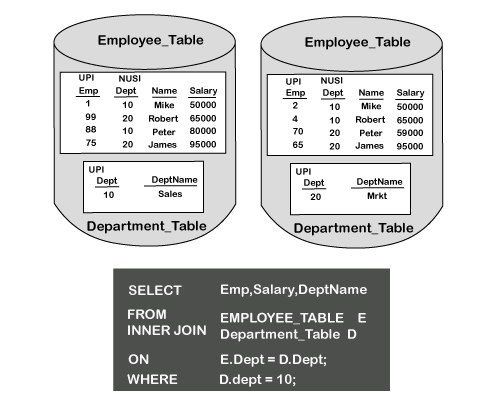
嵌套联接具有基于Dept列的联接相等(ON)条件。 “部门”列是部门表上的“主索引”列。
“部门”列是“员工”表中的“二级索引”列。嵌套联接可以将单行移到假脱机中,然后将该行与包含多个匹配项的另一个表进行匹配。
对此join语句的分析表明新语句已添加到该语句中。这称为WHERE选项。
使用WHERE选项时,可以从表中检索单个行。嵌套联接将始终使用唯一索引来隔离该单个记录,然后将该记录联接到另一个表。
另一个表可以使用索引,也可以不使用索引。如下图所示,在join语句中使用索引将提高性能并减少资源使用。
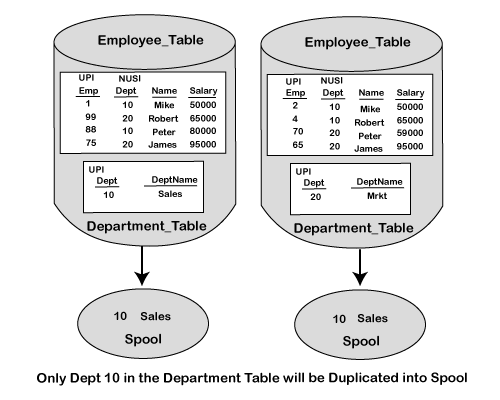
由于部门表中只有一行与部门= 10匹配,这是基于join语句中的AND选项的,因此Teradata Optimizer将选择一条路径来将部门表的列移到假脱机中,并在它们之间进行复制所有的AMP。
完成后,比赛将从该单个记录(10和SALES)继续到第二个表,该表未从基本AMP移出。
嵌套联接在OLTP环境中非常有用,因为同时使用了唯一索引和非唯一索引。
行哈希联接
哈希联接是合并联接的一部分。合并联接的键基于相等条件,例如join语句的ON子句中的E.Dept = D.Dept。
仅当每个AMP上的一个或两个表完全适合AMP的内存时,才可以进行哈希联接。
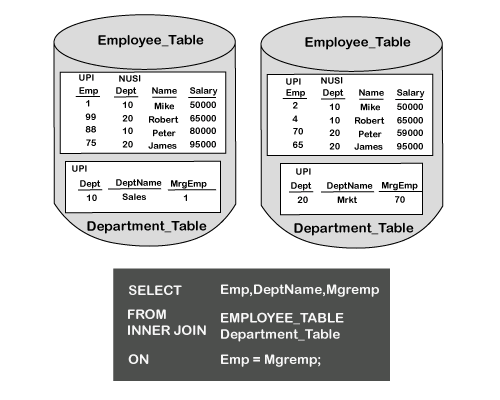
- 列的名称可以不同,但是行信息必须相似才能使匹配生效。
- EMP和MGREMP列都具有相同的信息类型,因此基于这些列名的连接将成功。
- EMP列是employee表上的Primary Index列。但是,MGREMP列不是部门表中的索引列。
- 确定哈希联接的关键在于,是否可以将SMALLER TABLE完全保留在每个AMP的MEMORY中。
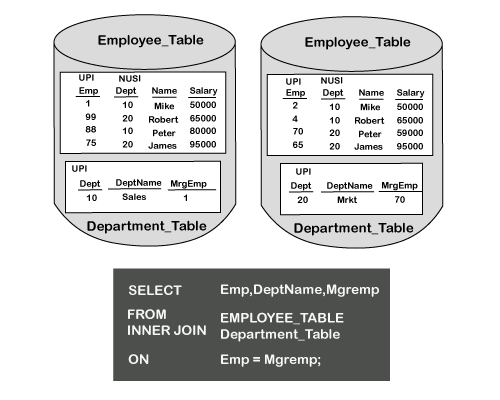
在哈希联接过程中,较小的表按行哈希排序,并在每个AMP上重复。
这里的键是一个较小的表,需要将其完全保存在每个AMP的内存中。
Teradata将使用较大表的联接列来搜索匹配项。行哈希联接非常高效,因为它消除了将较大的表进行排序,重新分配以及将其复制到假脱机中的过程。
复制到AMP内存中的行可提高性能,因为这些行永远不会进入后台处理程序。进入假脱机的行始终必须涉及磁盘活动。
产品加盟
产品联接将一个表的每一行与另一表的每一行进行比较。之所以称为产品联接,是因为它们是表一中的行数乘以表二中的行数的乘积。
例如,如果一张表有六行,而另一张表有六行,那么乘积联接将比较6 x 6行,潜在值为36行。
SELECT E.EMP,D.DEPT
FROM EMPLOYEETABLE E,DEPTTABLE D
WHERE
EMP LIKE '_b%'
很多时候,产品联接是主要错误,因为将比较两个表中的所有行。
Teradata表可能包含数百万行。如果用户不小心编写了产品,请结合两个分别具有100万行的表。
结果集将返回一万亿行。为避免产品联接,请检查语法以确保联接基于EQUALITY条件。
在上面的示例中,相等性语句读取“ WHERE EMP Like'_b%',因为此子句不是基于两个表e.dept = d.dept之间的公共域条件,因此结果是产品联接。
产品联接的另一个原因是建立别名后不使用别名。因此,首先,请确保联接语法中没有WHERE子句。
笛卡尔积加入
笛卡尔积连接将一个表中的每一行连接到另一表中的每一行。决定行数的唯一事情是两个表中的总行数。
如果一张表有5行,而另一张表有10行,那么我们将总是返回50行。
SELECT E.EMP,D.DEPT
FROM EMPLOYEETABLE E,DEPTTABLE D;
在大多数情况下,笛卡尔积连接是一个主要问题,因为两个表中的所有行都将被连接。
为了避免笛卡尔积连接,请检查语法以确保连接基于“相等”条件。
在上面的示例中,缺少WHERE子句,因为缺少此子句,这是两个表之间的公共域条件(e.dept = d.dept)。
产品联接的另一个原因是建立别名后不使用别名。
排除联接
排除联接具有一项主要函数。它们在联接期间排除行。
SELECT EMP, DEPT, NAME
FROM
EMPLOYEETABLE
WHERE DEPT=10 and
EMP NOT IN (SELECT MGREMP from DEPTTABLE WHERE MGREMP IS NOT NULL)
在上面的示例中,联接使用了NOT IN语句。排除联接用于查找其他表中没有匹配行的行。
使用NOT IN运算符的查询是始终提供排除联接结果的查询类型。在这种情况下,此查询将查找属于部门10的不是经理的所有雇员。
这些连接将始终涉及全表扫描,因为Teradata将需要比较每条记录以消除需要排除的行。
如果此比较中的两个表很大,则这种连接类型可能会占用大量资源。
排除联接的最大问题是,当使用NOT IN语句时,因为NULL被视为未知数,因此答案中返回的数据将为NULL。有两种方法可以避免此问题:
- 在CREATE TABLE上将NOT IN列定义为NOT NULL。
- 在联接的末尾添加“ AND WHERE Column IS NOT NULL”。