PostgreSQL – SELECT DISTINCT 子句
本文将重点介绍如何使用带有 DISTINCT 子句的 SELECT 语句从查询数据的结果集中删除重复行。
可以使用带有 DISTINCT 子句的 SELECT 语句从 PostgreSQL 中的查询结果集中删除重复行。它为每组重复项保留一行。 DISTINCT 子句可用于单个列或列列表。
Syntax:SELECT DISTINCT column_1 FROM table_name;
如果您希望对列列表进行操作,则语法将类似于以下内容:
Syntax:SELECT DISTINCT column_1, column_2, column_3 FROM table_name;
现在,让我们看几个例子以便更好地理解。为了举例,我们将创建一个示例数据库,如下所述:
使用如下所示的命令创建一个数据库(例如,Favourite_colours):
CREATE DATABASE Favourite_colours;现在使用以下命令向数据库添加一个包含列(例如 id、colour_1 和 colour_2)的表(例如 my_table):
CREATE TABLE my_table(
id serial NOT NULL PRIMARY KEY,
colour_1 VARCHAR,
colour_2 VARCHAR
);现在使用以下命令在我们刚刚添加到数据库中的表中插入一些数据:
INSERT INTO my_table(colour_1, colour_2)
VALUES
('red', 'red'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue'),
('green', 'red'),
('green', 'blue'),
('green', 'green'),
('blue', 'red'),
('blue', 'green'),
('blue', 'blue');现在通过如下查询来检查一切是否符合预期:
SELECT
id,
colour_1,
colour_2
FROM
my_table;如果一切都按预期进行,输出将如下所示: 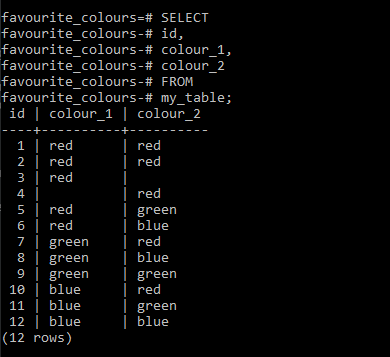
由于我们的数据库很好,我们继续执行 SELECT DISTINCT 子句。
示例 1:
一列上的 PostgreSQL DISTINCT
SELECT
DISTINCT colour_1
FROM
my_table
ORDER BY
colour_1;输出:

示例 2:
多列上的 PostgreSQL DISTINCT
SELECT
DISTINCT colour_1,
colour_2
FROM
my_table
ORDER BY
colour_1,
colour_2;输出: 