PostgreSQL – 立方体
在 PostgreSQL 中,CUBE 用于一次生成多个分组集。它是 GROUP BY 子句的子类,在生成多个分组集时派上用场。分组集是要分组到的一组列。
句法:
SELECT
column1,
column2,
column3,
aggregate (column4)
FROM
table_name
GROUP BY
CUBE (column1, column2, column3);我们来分析一下上面的语法:
- 首先,在 SELECT 语句的 GROUP BY 子句中定义 CUBE 子句。
- 然后在选择列表中指明要分析的列并添加聚合函数表达式。
- 最后,在 GROUP BY 子句中,在 CUBE 子句的括号内设置维度列。
该查询基于 CUBE 中设置的维度列生成所有可行的分组集。 CUBE 子条款是定义多个分组集的一种简短方式。通常,如果 CUBE 中设置的列数为 n,则它会生成 2n 个组合。
为了更好地理解这个概念,让我们创建一个新表并继续示例。
要创建示例表,请使用以下命令:
CREATE TABLE geeksforgeeks_courses(
course_name VARCHAR NOT NULL,
segment VARCHAR NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (course_name, segment)
);现在使用以下命令向其中插入一些数据:
INSERT INTO geeksforgeeks_courses(course_name, segment, quantity)
VALUES
('Data Structure in Python', 'Premium', 100),
('Algorithm Design in Python', 'Basic', 200),
('Data Structure in Java', 'Premium', 100),
('Algorithm Design in Java', 'Basic', 300);现在我们的表格已经设置好,让我们看看例子。
示例 1:
以下查询使用 CUBE 子句生成多个分组集,如下所示:
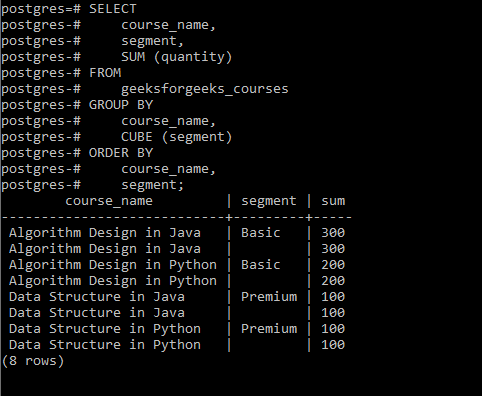
SELECT
course_name,
segment,
SUM (quantity)
FROM
geeksforgeeks_courses
GROUP BY
CUBE (course_name, segment)
ORDER BY
course_name,
segment;输出: 
示例 2:
以下查询按如下方式执行部分 CUBE:
SELECT
course_name,
segment,
SUM (quantity)
FROM
geeksforgeeks_courses
GROUP BY
course_name,
CUBE (segment)
ORDER BY
course_name,
segment;输出: