线性回归是一种基于监督学习的机器学习算法。它执行回归任务。回归基于自变量对目标预测值建模。它主要用于找出变量与预测之间的关系。不同的回归模型基于–正在考虑的因变量和自变量之间的关系类型以及所使用的自变量数量而有所不同。 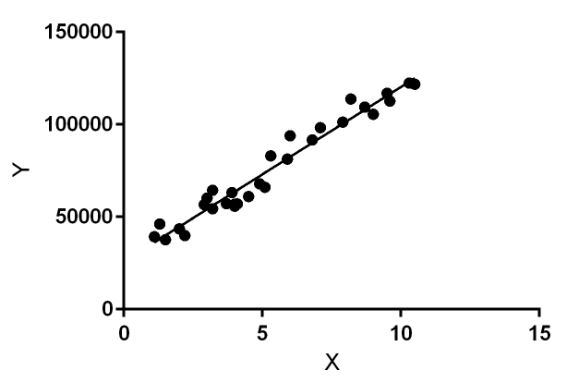
线性回归执行任务以基于给定的自变量(x)预测因变量值(y)。因此,这种回归技术找出了x(输入)和y(输出)之间的线性关系。因此,名称为线性回归。
在上图中,X(输入)是工作经验,Y(输出)是一个人的工资。回归线是我们模型的最佳拟合线。
线性回归的假设函数: 
在训练模型时,我们得到:
x:输入训练数据(单变量–一个输入变量(参数))
y:数据标签(监督学习)
训练模型时,对于给定的x值,它适合于预测y值的最佳线。该模型获得通过寻找最佳的θ1和θ2个值的最佳回归拟合线。
θ1:截距
θ2:x的系数
一旦我们找到最好的θ1和θ2倍的值,我们得到了最佳拟合线。因此,当我们最终将模型用于预测时,它将为x的输入值预测y的值。
如何更新θ1和θ2的值,以获得最佳拟合线?
成本函数(J):
通过获得最佳拟合回归线,该模型旨在预测y值,以使预测值和真实值之间的误差差异最小。所以,为了更新θ1和θ2点的值,以达到最小化预测的y值(预解码值)和真Y值(Y)之间的误差的最佳值是非常重要的。


线性回归的成本函数(J)是预测y值(pred)与真实y值(y)之间的均方根误差(RMSE )。
梯度下降:
到更新θ1和θ,以减少成本函数(最小化RMSE值)和实现模型使用梯度下降的最佳拟合线2倍的值。这样做是为了开始与随机θ1和θ2倍的值,然后迭代地更新所述值,达到最低的成本。