本文将帮助您简要介绍Raft的历史,什么是共识,什么是RAFT协议,有哪些优点,它比其他替代品更好,什么是RAFT协议的局限性。
介绍
Raft协议是由Diego Ongaro和John Ousterhout(斯坦福大学)开发的,后者于2014年获得了Diego的博士学位(本文的链接位于文章结尾的“参考”部分)。考虑到Lesley Lamport的前身Paxos算法非常难以理解和实现,因此设计Raft的目的是为了更好地理解共识的方式(稍后将解释共识)。因此,迭戈的论文标题是“寻找可理解的共识算法”。在筏之前,Paxos被认为是达成共识的圣杯。
开始吧。
共识
因此,要了解Raft,我们首先来看看Raft协议试图解决的问题,并且该问题正在达成共识。共识是指多个服务器就相同的信息达成共识,这对于设计容错分布式系统是必不可少的。让我们在视觉效果的帮助下对其进行描述。
因此,让我们首先定义客户端与服务器交互以阐明流程时使用的流程。
处理:客户端向服务器发送消息,服务器回复并回复。
容忍失败的共识协议必须具有以下功能:
- 有效性:如果一个过程决定(读/写)一个值,那么它一定是由其他一些正确的过程提出的
- 协议:每个正确的过程都必须就相同的价值达成协议
- 终止:每个正确的过程都必须在有限数量的步骤后终止。
- 完整性:如果所有正确的过程都决定相同的值,那么任何过程都具有所述值。
现在,可以有两种类型的系统仅假设一个客户端(为了易于理解):
- 单服务器系统:客户端与只有一台服务器且没有备份的系统进行交互。在这样的系统中达成共识是没有问题的。
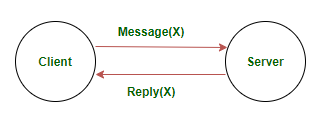
单服务器筏可视
- 多服务器系统:客户端与具有多个服务器的系统进行交互。这样的系统可以有两种类型:
- 对称的:-多个服务器中的任何一个都可以响应客户端,而所有其他服务器都应该与响应客户端请求的服务器同步,并且
- 不对称: – 仅当选领导人服务器可以响应客户端。然后,所有其他服务器与领导服务器同步。
下面给出的是一个非对称多服务器系统的示例,我们将在本文中使用它。
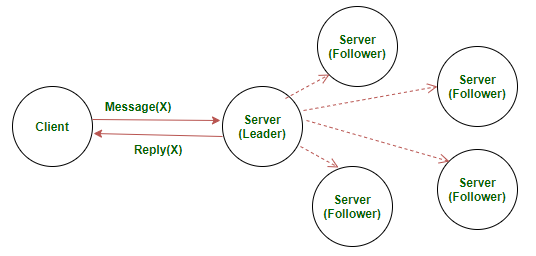
多服务器筏可视
所有服务器跨时间复制(或维护)相似数据(共享状态)的系统现在可以称为复制状态机。
现在,我们将定义一些术语,这些术语用于引用分布式系统中的各个服务器。
- 领导者-只有当选领导可以与客户端交互的服务器。所有其他服务器将自己与领导者同步。在任何时候,最多只能有一位领导者(可能是0位,我们将在后面解释)
- 追随者–追随者服务器在每个常规时间间隔后将其数据副本与领导者的数据副本同步。当领导者服务器出现故障(由于任何原因)时,一名跟随者可以参加选举并成为领导者。
- 候选人–在竞选选举领袖服务器时,这些服务器可以要求其他服务器投票。因此,当他们要求投票时,他们被称为候选人。最初,所有服务器都处于候选状态。
因此,上面的系统现在可以标记为以下快照。
多个服务器标记为筏视觉
CAP定理CAP定理是一个概念,即分布式数据库系统只能具有3个中的2个:
- 一致性–所有服务器节点(领导者或跟随者)中的数据都相同,这意味着系统几乎具有瞬时同步功能
- 可用性–每个请求都会得到响应(成功/失败)。它要求系统在100%的时间里可运行以处理请求,并且
- 分区容限–即使某些服务器节点出现故障,系统仍会继续响应。这意味着系统以某种方式维护所有请求/响应函数。
什么是Raft协议
Raft是一种共识算法,旨在使其易于理解。它在容错和性能方面与Paxos等效。不同之处在于它被分解为相对独立的子问题,并且干净地解决了实际系统所需的所有主要部分。我们希望Raft将使共识能够为更广泛的受众所接受,并且希望这个更广泛的受众能够开发出比当今更高质量的基于共识的系统。
筏共识算法解释
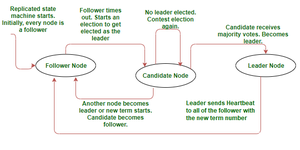
首先,Raft指出,复制的状态机(服务器群集)中的每个节点都可以停留在三种状态中的任何一种,即领导者,候选者和关注者。下图将提供必要的视觉帮助。
服务器节点状态转换
在正常情况下,节点可以处于以上三种状态中的任何一种状态。只有领导者才能与客户互动;对跟随者节点的任何请求都将重定向到领导者节点。候选人可以要求投票以成为领导者。追随者仅响应候选人或领导者。
为了维持这些服务器状态,Raft算法将时间分为任意长度的小部分。每个术语由单调递增的数字(称为术语编号)标识。
学期编号
该术语编号由每个节点维护,并在节点之间进行通信时传递。每个学期都以选举来确定新的领导者。候选人要求其他服务器节点(追随者)投票以收集多数票。如果大多数人聚集在一起,则候选人将成为当前任期的领导者。如果没有建立多数席位,这种情况称为分裂投票,任期以无领导者结束。因此,项最多只能有一个领导者。
维护学期号的目的
通过观察每个节点的术语号来执行以下任务:
- 如果服务器的期限号小于群集中其他服务器的期限号,则服务器会更新其期限号。这意味着,当新任期开始时,将与领导者或候选人相匹配的任期号,并更新为与最新任期(领导者)相匹配
- 如果候选人或领导者的任期编号已过期(比其他人少),则降级为“关注者”状态。如果在任何时间任何其他服务器具有更高的任期编号,则它可以立即成为领导者。
- 正如我们之前所说的,服务器的期限号也可以进行通信,如果以陈旧的期限号实现请求,则该请求将被拒绝。这基本上意味着服务器节点将不接受来自具有较低期限编号的服务器的请求
Raft算法使用两种类型的远程过程调用(RPC)来执行功能:
- RequestVotes RPC由候选节点发送,以在选举期间收集选票
- Leader节点将AppendEntries用于复制日志条目,并用作检测服务器是否仍在运行的心跳机制。如果心跳得到响应,则服务器已启动,否则服务器已关闭。请注意,心跳不包含任何日志条目。
现在,让我们来看看领导人选举的过程。
领导人选举
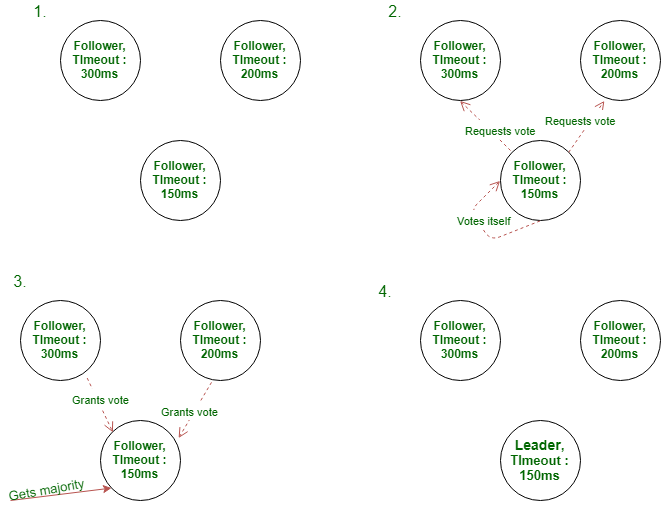
为了维持作为群集领导者的权限,“领导者”节点发送心跳以表示对其他“跟随者”节点的控制权。当“跟随者”节点在等待来自“领导者”节点的心跳时超时时,将进行领导者选举。此时,超时的节点将其状态更改为候选状态,为其本身投票,并发出RequestVotes RPC来建立多数并尝试成为Leader。选举可以通过以下三种方式进行:
- 候选节点通过从群集节点中获得大多数投票而成为领导者。此时,它将状态更新为Leader,并开始发送心跳以将新Leader通知其他服务器。
- 候选人节点未能在选举中获得多数选票,因此该任期以无领导人结束。候选节点返回到关注者状态。
- 如果请求投票的候选节点的期限数少于群集中的其他候选节点,则AppendEntries RPC被拒绝,其他节点保持其候选状态。如果术语数更大,则“候选”节点将被选为新的“领导者”。
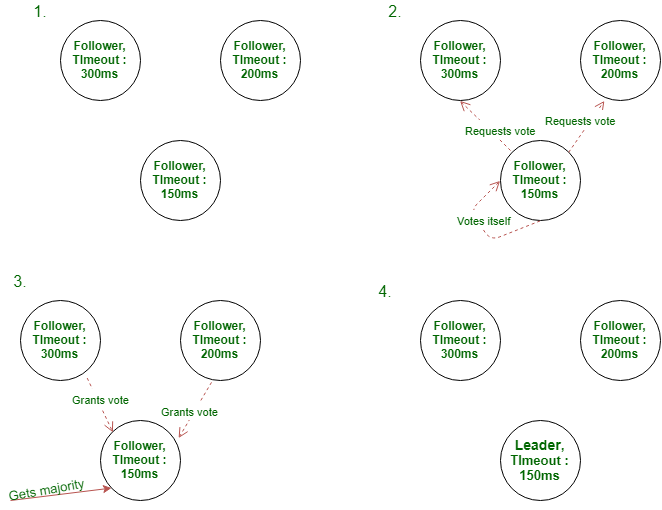
筏长选举
以下Raft论文摘录(在下面的参考文献中链接)说明了服务器超时的重要方面。
Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly. To prevent split votes in the first place, election timeouts are chosen randomly from a fixed interval (e.g., 150–300ms). This spreads out the servers so that in most cases only a single server will time out; it wins the election and sends heartbeats before any other servers time out. The same mechanism is used to handle split votes. Each candidate restarts its randomized election timeout at the start of an election, and it waits for that timeout to elapse before starting the next election; this reduces the likelihood of another split vote in the new election.
日志复制
为了简化起见,同时向初学者讲解,我们将范围限制为仅发出写入请求的客户端。客户提出的每个请求都存储在领导者的日志中。然后将此日志复制到其他节点(跟随者)。通常,日志条目包含以下三个信息:
- 客户端指定执行的命令
- 用于标识条目在节点日志中的位置的索引。索引从1开始(从1开始)。
- 确定命令输入时间的术语号。
Leader节点将AppendEntries RPC激发到所有其他服务器(跟随者)以与当前Leader同步/匹配其日志。Leader继续发送RPC,直到所有关注者安全地在其日志中复制新条目。
该算法中有一个条目提交的概念。当群集中的大多数服务器成功将新条目复制到其日志中时,将被视为已提交。此时,Leader还将在其日志中提交该条目,以显示该条目已被成功复制。由于显而易见的原因,日志中的所有先前条目也被视为已提交。提交条目后,领导者执行该条目,并将结果返回给客户端。
应该注意的是,这些条目是按照它们接收的顺序执行的。
如果不同日志中的两个条目(“领导者”和“追随者”)具有相同的索引和术语,则可以保证它们存储相同的命令,并且直到该点(索引),日志都是相同的。
但是,万一Leader崩溃了,日志可能会变得不一致。报价木筏纸:
In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own. This means that conflicting entries in follower logs will be overwritten with entries from the leader’s log.
Leader节点将在Leader和Follower中查找最后匹配的索引号,然后它将使用Leader提供的新条目覆盖该点(索引号)之后的所有其他条目。这有助于将追随者与领导者进行日志匹配。 AppendEntries RPC将迭代发送索引号减少的RPC,以便找到匹配项。找到匹配项后,RPC成功。
安全
为了维持一致性和相同的服务器节点集,通过Raft共识算法确保领导者将在其日志中提交来自先前项的所有条目。
在领导人选举期间,RequestVote RPC还包含有关候选人日志的信息(例如学期编号),以找出哪一个是最新的。如果请求投票的候选人的更新数据少于其请求投票的跟随者的更新数据,则跟随者根本不会为该候选人投票。以下来自原始Raft论文的摘录以类似且深刻的方式将其清除。
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
筏协议中的安全规则
Raft协议通过其设计保证了以下针对共识故障的安全性:
- 领导人选举安全-每学期最多一名领导人)
- 日志匹配的安全性(如果多个日志的条目具有相同的索引和术语,那么在直到给定索引的所有条目中,这些日志都被保证是相同的。
- 领导者完整性–在给定期限内提交的日志条目将始终出现在该术语之后的领导者的日志中)
- 状态机安全性–如果服务器已将特定的日志条目应用于其状态机,则该服务器群集中的其他服务器都无法对同一日志应用不同的命令。
- 领导者仅可追加–领导者节点(服务器)只能在其日志中添加(不允许其他操作(如覆盖,删除,更新)其他命令)
- 跟随者节点崩溃–跟随者节点崩溃时,发送到崩溃节点的所有请求都将被忽略。此外,由于明显的原因,崩溃的节点无法参加领导者选举。节点重新启动时,它将与引导节点同步其日志
集群成员和联合共识
当集群中节点的状态发生变化(集群配置发生变化)时,系统容易受到可能导致系统故障的故障的影响。因此,为防止这种情况,Raft使用了一种称为两阶段的方法来更改群集成员身份。因此,在这种方法中,群集在实现新的群集成员身份配置之前首先更改为中间状态(称为“联合共识” )。联合共识使系统即使在配置之间进行转换时也可用于响应客户端请求。因此,增加分布式系统的可用性是主要目的。
它的优点/特点是什么
- 考虑到在分布式系统上达成共识的最流行方法是Paxos算法,因此Raft协议的设计易于理解。具有基础知识和常识的任何人都可以理解该协议的主要内容以及Diego Ongaro和John Ousterhout发表的研究论文
- 与其他替代方案(主要是Paxos)相比,它相对容易实现,因为针对性更强的用例部分是关于分布式系统的假设。 Raft的许多开源实现都可以从Internet上获得。有些在Go,C++, Java
- Raft协议已分解为较小的子问题,可以相对独立地解决这些子问题,以更好地理解,实施,调试和优化性能,以适应更特定的用例
- 即使少数服务器出现故障,遵循Raft共识协议的分布式系统也将保持运行状态。例如,如果我们有一个5个服务器节点群集,如果2个节点发生故障,则系统仍然可以运行。
- 筏中采用的领导者选举机制经过精心设计,一个节点将始终在最多2个任期内获得多数选票。
- 筏使用RPC(远程过程调用)来请求投票并同步集群(使用AppendEntries)。因此,呼叫的负载不会落在集群中的领导者节点上。
- 木筏是最近才设计的,因此采用了Paxos和类似规程制定时尚未理解的现代概念。
- 集群中的任何节点都可以成为领导者。因此,它具有一定程度的公平性。
- GitHub和相关位置已经有许多针对不同用例的不同开源实现
- 像MongoDB,HashiCorp等公司正在使用它!
木筏替代品
- Paxos –变体:-多Paxos,廉价Paxos,快速Paxos,广义Paxos
- 实用的拜占庭容错算法(PBFT)
- 股权证明算法(PoS)
- 委托权益证明算法(DPoS)
局限性
- 筏严格是单个Leader协议。太多的流量会阻塞系统。存在解决此瓶颈的Paxos算法的某些变体。
- 有许多假设在起作用,例如未发生拜占庭式故障,这降低了现实生活中的适用性。
- 漂流是解决达成共识时出现的问题子集的一种更专业的方法。
- Cheap-paxos(Paxos的一种变体)即使在服务器群集中只有一个节点在运行的情况下也可以工作。概括地说,K + 1个复制服务器可以容忍K个服务器的关闭/故障。
进一步探索筏
请遵循以下建议的路径,以了解有关Raft的更多信息:
- 与Raft达成分布式共识– CodeConf 2016 – GitHub – YouTube
- 筏导向可视化
- 寻找一种可以理解的共识算法– Raft – Medium
- 寻找一种易于理解的共识算法-木筏-扩展版本
参考
- 筏导向可视化
- Raft GitHub
- PyGotham 2017 YouTube
- 可理解性设计:筏共识算法– Diego Ongaro – YouTube
- 与Raft达成分布式共识– CodeConf 2016 – GitHub – YouTube
- 木筏介绍(CoreOS Fest 2015)– CoreOS – YouTube
- 寻找一种易于理解的共识算法-木筏-扩展版本
- 中篇文章–了解木筏
- WikiPedia –木筏
- 共识–维基百科
- 木筏互动可视化
- 罗格斯–共识
- 杜克大学–共识
- CAP定理–中
- 集装箱解决方案–筏解说1/3
- 集装箱解决方案–木筏说明2/3
- 集装箱解决方案–木筏解释– 1/3
- 领事共识协议
- 剑桥大学–海蒂·霍华德(Heidi Howard)对木筏的分析
- 木筏和Zab一样好吗
- 海蒂·霍华德·筏(Heidi Howard Raft)GitHub