共识聚类
聚类:
在学习Consensus Clustering 之前,我们必须知道什么是Clustering 。在机器学习中,聚类是一种用于根据其相似性将不同对象分组在分离的簇中的技术,即相似的对象将位于相同的簇中,与其他相似对象的簇分开。它是一种无监督学习方法。很少使用的聚类算法有 K-means、K-prototype、DBSCAN 等。
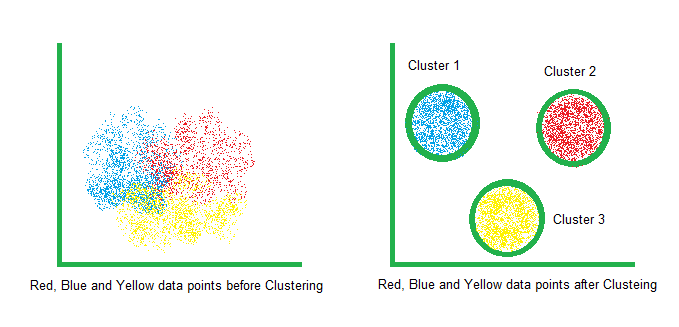
聚类
共识聚类:
正常的聚类过程几乎没有缺点。 K-means 或 K-prototype 等算法使用随机初始化过程,这会在算法的每次迭代中产生不同的集群结果或集群初始化。还需要对K的值进行初始化,一般采用Elbow法选择。因此,聚类过程非常依赖于这些指标,因此,它会产生偏差聚类,这些聚类也非常不稳定。为了消除这些缺点,我们采用了一种不同的聚类方法,即共识聚类。
“共识”一词来自一个拉丁词,意思是“普遍同意”。共识聚类是一种将多个聚类组合成一个比输入聚类更稳定的单一聚类的技术。这样,所有的集群都合并成一个稳定的单一集群,这个过程是通过在每个级别生成一个共识矩阵来迭代完成的。
共识聚类的优点:
- 集群的质量和鲁棒性更好。
- 生成正确数量的集群。
- 更好地处理丢失的数据。
- 可以独立获得各个分区。
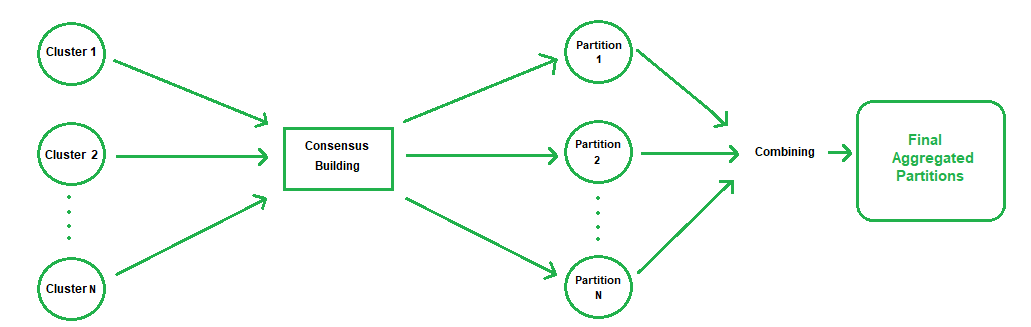
共识聚类过程
共识聚类的过程:
共识聚类基于两个阶段-
- 分区生成:在这个阶段,使用不同的数据属性子集创建不同的数据对象分区,应用具有不同偏差的不同聚类算法,采用不同的参数进行聚类,并使用整个数据集的不同随机子样本。一旦我们生成了初始分区,我们就会在分区之间产生共识,并根据之前的共识进一步生成新的分区。
- 共识生成:数据分区之间的共识是使用共识函数生成的,通常在这些方法中获得——
- 基于中值分区的方法:这里不同分区的数据点通过它们的相似性指数分组在一起。我们根据先前分区的数据点的中位数形成新的分区。相似度指数取决于数据点的一致性和不一致性,通过F-measures、Rand 指数等来衡量。
- 基于共现的方法:在这种方法中,我们可以使用 3 种方法: 1.基于重新标记/投票的方法,2.基于联合关联矩阵的方法,3 .基于图形的方法。重新标记/投票 基于方法通过确定与当前共识的对应关系来生成新的集群。每个实例从他们的集群分配中获得一定的投票,并相应地更新共识和集群分配。基于联合关联矩阵的方法 通过数据点的相似性,基于协关联矩阵生成新的集群,基于图的方法生成一个加权图来表示多个集群,并通过最小化图割来找到最佳分区。

共识聚类的工作流程
有许多不同的共识聚类算法基于生成共识函数的不同方法,并且还有许多研究工作仍在改进现有模型。