插入m-Way搜索树:
m-Way搜索树中的插入与二叉树相似,但一个节点中的元素不得超过m-1个。如果该节点已满,则将创建一个子节点以插入其他元素。
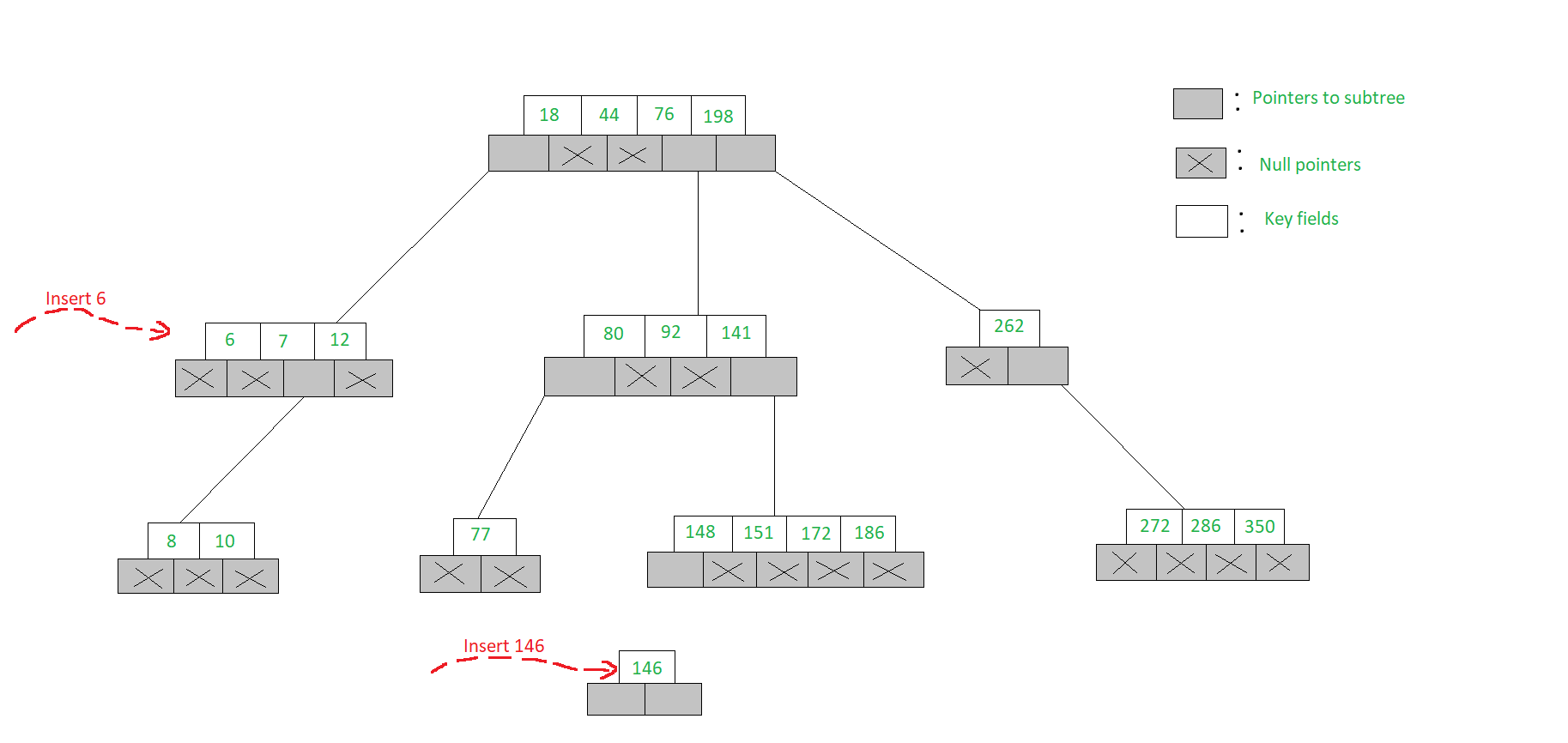
让我们看下面给出的在m-Way搜索树中插入元素的示例。
例子:
- 要将新元素插入m-Way搜索树,我们将以与搜索元素相同的方式进行操作
- 要将6插入到图中所示的5向搜索树中,我们继续搜索6并发现我们掉落在节点[7,12]的树上,第一个子节点显示了空指针
- 由于该节点只有两个关键字,并且一个5向搜索树最多可在一个节点中容纳4个关键字,因此像[6、7、12]一样将6插入到节点中
- 但是要插入146,节点[148、151、172、186]已满,因此我们打开一个新的子节点并将146插入其中。这两个插入都在下面进行了说明
// Inserts a value in the m-Way tree
struct node* insert(int val,
struct node* root)
{
int i;
struct node *c, *n;
int flag;
// Function setval() is called which
// returns a value 0 if the new value
// is inserted in the tree, otherwise
// it returns a value 1
flag = setval(val, root, &i, &c);
if (flag) {
n = (struct node*)malloc(sizeof(struct node));
n->count = 1;
n->value[1] = i;
n->child[0] = root;
n->child[1] = c;
return n;
}
return root;
}
插():
- 函数insert()接收两个参数-新节点的地址和插入的值
- 此函数调用函数setval() ,如果将新值插入树中,则该函数返回值0 ,否则返回值1
- 如果返回1,则为新节点分配内存,为变量count分配值1 ,并将新值插入节点
- 然后将子节点的地址存储在子指针中,最后返回该节点的地址
// Sets the value in the node
int setval(int val,
struct node* n,
int* p,
struct node** c)
{
int k;
// if node is null
if (n == NULL) {
*p = val;
*c = NULL;
return 1;
}
else {
// Checks whether the value to be
// inserted is present or not
if (searchnode(val, n, &k))
printf("Key value already exists\n");
// The if-else condition checks whether
// the number of nodes is greater or less
// than the maximum number. If it is less
// then it inserts the new value in the
// same level node, otherwise, it splits the
// node and then inserts the value
if (setval(val, n->child[k], p, c)) {
// if the count is less than the max
if (n->count < MAX) {
fillnode(*p, *c, n, k);
return 0;
}
else {
// Insert by splitting
split(*p, *c, n, k, p, c);
return 1;
}
}
return 0;
}
}
setval():
- 函数setval()接收四个参数
- 第一个参数是要插入的值
- 第二个参数是节点的地址
- 第三个参数是一个整数指针,它指向在函数insert()中定义的局部标志变量。
- 最后一个参数是指向指针,将在这个函数调用的函数设置的子节点
- 函数setval()返回一个标志值,该值指示是否插入了该值
- 如果节点为空,则此函数调用函数searchnode() ,该函数检查树中是否已存在该值
- 如果该值已经存在,则会显示一条适当的消息
- 然后,对该节点的子节点进行递归调用setval()函数
- 如果这次函数返回值1,则表示未插入该值
- 然后检查节点是否已满的条件
- 如果节点未满,则函数fillnode()来填充节点中的值,因此此时返回值0
- 如果节点已满,则调用一个函数split()来拆分现有节点。此时,将返回值1以将当前值添加到新节点
// Adjusts the value of the node
void fillnode(int val,
struct node* c,
struct node* n,
int k)
{
int i;
// Shifting the node by one position
for (i = n->count; i > k; i--) {
n->value[i + 1] = n->value[i];
n->child[i + 1] = n->child[i];
}
n->value[k + 1] = val;
n->child[k + 1] = c;
n->count++;
}
fillnode():
- 函数fillnode()接收四个参数
- 第一个是要插入的值
- 第二个是要插入的新值的子节点的地址
- 第三个是要在其中插入新值的节点的地址
- 最后一个参数是要插入新值的节点的位置
// Splits the node
void split(int val,
struct node* c,
struct node* n,
int k, int* y,
struct node** newnode)
{
int i, mid;
if (k <= MIN)
mid = MIN;
else
mid = MIN + 1;
// Allocating the memory for a new node
*newnode = (struct node*)
malloc(sizeof(struct node));
for (i = mid + 1; i <= MAX; i++) {
(*newnode)->value[i - mid] = n->value[i];
(*newnode)->child[i - mid] = n->child[i];
}
(*newnode)->count = MAX - mid;
n->count = mid;
// it checks whether the new value
// that is to be inserted is inserted
// at a position less than or equal
// to minimum values required in a node
if (k <= MIN)
fillnode(val, c, n, k);
else
fillnode(val, c, *newnode, k - mid);
*y = n->value[n->count];
(*newnode)->child[0] = n->child[n->count];
n->count--;
}
分裂():
- 函数split()接收六个参数
- 前四个参数与函数fillnode()完全相同
- 第五个参数是指向变量的指针,该变量保存从节点拆分处的值
- 最后一个参数是指向拆分时创建的新节点的指针
- 在此函数,首先检查要插入的新值是否插入到小于或等于节点中所需最小值的位置。
- 如果满足条件,则将节点拆分到位置MIN处
- 否则,节点将在大于MIN的一个位置被分割
- 然后动态地为新节点分配内存
- 接下来,执行一个for循环,该操作将节点拆分位置的值和出现在该值右侧的子代复制到新节点中
在m-Way搜索树中删除:
令K为要从m-Way搜索树中删除的关键字。要删除密钥,我们就像搜索密钥一样继续进行。让容纳密钥的节点如下所示。 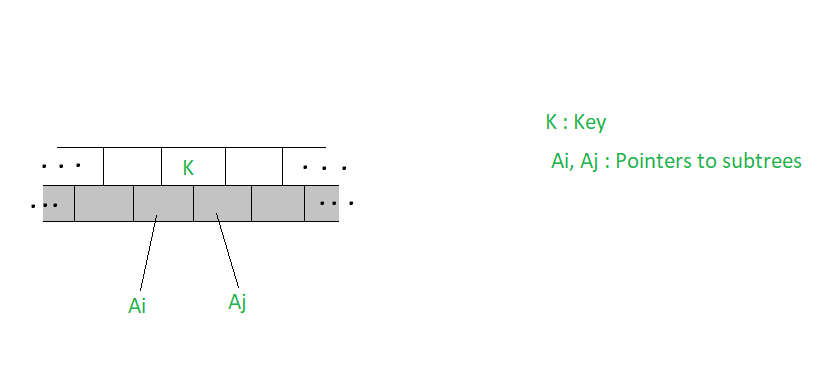
方法:
有几种情况需要删除
- 如果(A i = A j = NULL),则删除K
- 如果(A i != NULL,A j = NULL),则在A i指向的子节点中选择最大的关键元素K’ ,删除密钥K’并将K替换为K’
- 显然,删除K’可能需要进行后续替换,因此也需要以类似的方式进行删除,以使密钥K’可以在树上移动
- 如果(A i = NULL,A j != NULL) ,则从A j所指向的子树中选择最小的关键元素K” ,删除K”并将K替换为K”
- 同样,删除“ K”可能会触发后续的替换和删除操作,以使“ K”能够向上移动
- 如果(A i != NULL,A j != NULL) ,则从A i指向的子树中选择最大的关键元素K’ ,或从子树中选择最小的关键元素K” 。 A j指向替换K
- 如前所述,要将“ K”或“ K”移到树上,可能需要随后的替换和删除
例子:
- 要删除151,我们搜索151,然后观察到叶节点[148,151,172,186]所在的叶子节点的左子树指针和右子树指针都使得(A i = A j = NULL)
- 因此,我们仅删除151,该节点将变为[148,172,186]。删除92也遵循类似的过程
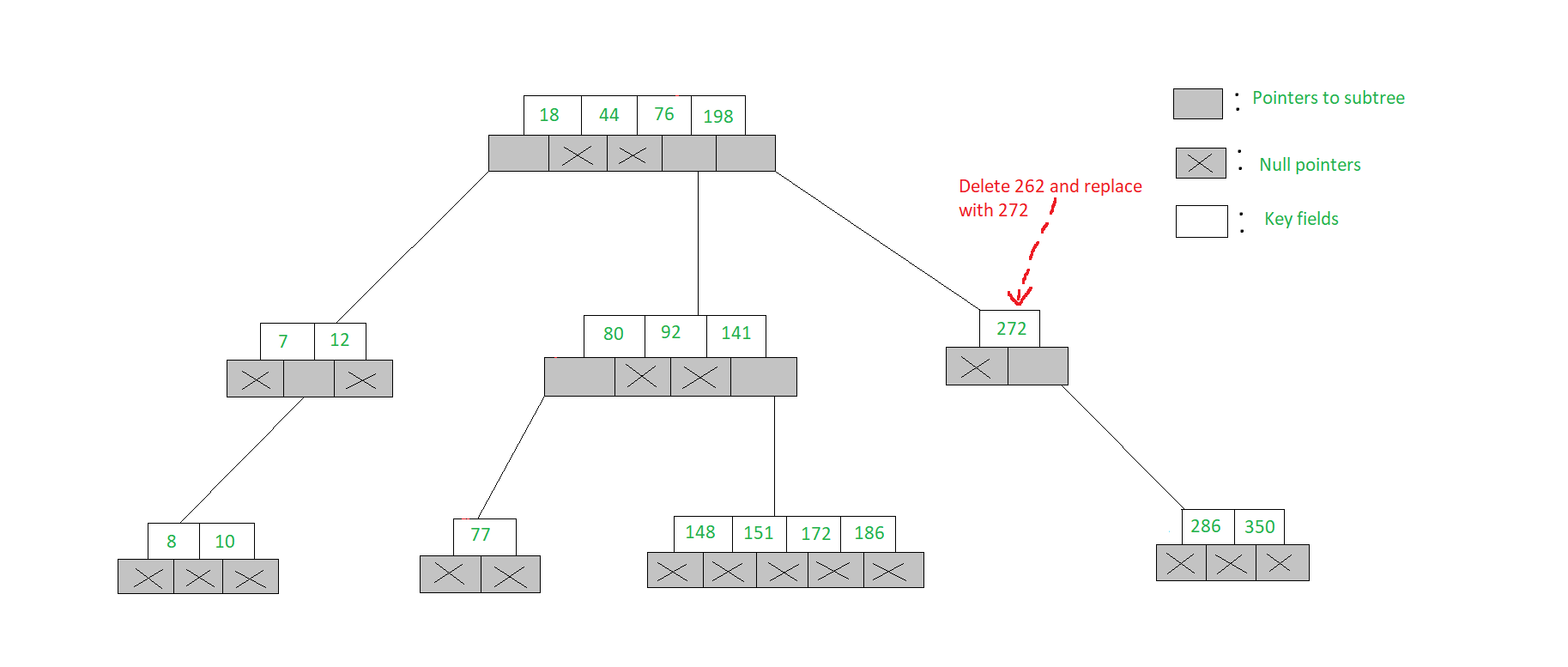
- 要删除262,我们发现其左和右子树指针A i j分别为(A i = A j = NULL)
- 因此,我们从子节点[272、286、350]中选择最小的元素272,删除272并用272替换262。请注意,要删除272,需要再次遵守删除过程
删除内容如下所示
- 要删除12,我们发现节点[7,12]容纳12,并且密钥满足(A i != NULL,A j = NULL)
- 因此,我们从Ai指向的节点中选择最大的键,即10,然后将12替换为10。删除操作如下所示
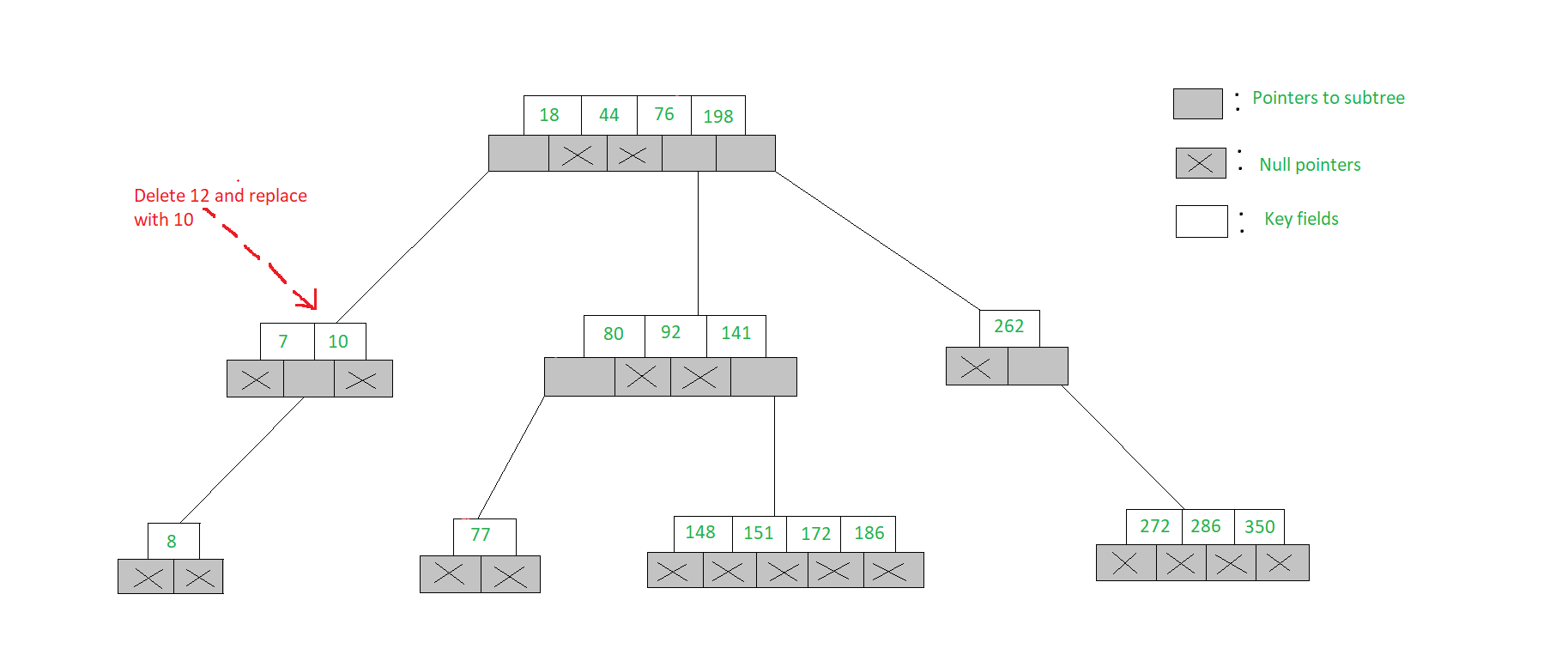
// Deletes value from the node
struct node* del(int val,
struct node* root)
{
struct node* temp;
if (!delhelp(val, root)) {
printf("\n");
printf("value %d not found.\n", val);
}
else {
if (root->count == 0) {
temp = root;
root = root->child[0];
free(temp);
}
}
return root;
}
del():
- 函数del()接收两个参数。首先是要删除的值,其次是根节点的地址
- 此函数调用另一个帮助器函数delhelp() ,如果删除该值失败,则返回值0,否则返回1。
- 否则,条件检查计数是否为0
- 如果是,则表明从中删除该值的节点是最后一个值
- 因此,该节点的第一个子节点本身就是该节点,并且原始节点被删除。最后,返回新的根节点的地址
// Helper function for del()
int delhelp(int val,
struct node* root)
{
int i;
int flag;
if (root == NULL)
return 0;
else {
// Again searches for the node
flag = searchnode(val,
root,
&i);
// if flag is true
if (flag) {
if (root->child[i - 1]) {
copysucc(root, i);
// delhelp() is called recursively
flag = delhelp(root->value[i],
root->child[i])
if (!flag)
{
printf("\n");
printf("value %d not found.\n", val);
}
}
else
clear(root, i);
}
else {
// Recursion
flag = delhelp(val, root->child[i]);
}
if (root->child[i] != NULL) {
if (root->child[i]->count < MIN)
restore(root, i);
}
return flag;
}
}
delhelp():
- 函数delhelp()接收两个参数。第一个是要删除的值,第二个是要从中删除它的节点的地址
- 最初检查节点是否为NULL
- 如果是,则返回值0
- 否则,将调用函数searchnode()
- 如果找到该值,则检查另一个条件以查看该值是否有任何子级要删除
- 如果是这样,则函数copysucc() ,该函数将复制要删除的值的后继对象,然后对要删除的值及其子项的函数delhelp()进行递归调用
- 如果子级为空,则调用函数clear()删除该值
- 如果searchnode()函数失败,则递归调用是通过将孩子的地址函数delhelp()制成
- 如果该节点的子节点不为空,则函数restore()来合并该子节点及其同级节点
- 最后,返回标志的值,该标志被设置为函数searchnode()的返回值。
// Removes the value from the
// node and adjusts the values
void clear(struct node* m, int k)
{
int i;
for (i = k + 1; i <= m->count; i++) {
m->value[i - 1] = m->value[i];
m->child[i - 1] = m->child[i];
}
m->count--;
}
清除():
- 函数clear()接收两个参数。第一个是要从中删除值的节点的地址,第二个是要删除的值的位置
- 此函数只是将值从要删除的值所在的位置向左移动一位。
// Copies the successor of the
// value that is to be deleted
void copysucc(struct node* m, int i)
{
struct node* temp;
temp = p->child[i];
while (temp->child[0])
temp = temp->child[0];
p->value[i] = temp->value[i];
}
copysucc()
- 函数copysucc()接收两个参数。首先是要复制后继者的节点的地址,其次是要用其后继者覆盖的值的位置
// Adjusts the node
void restore(struct node* m, int i)
{
if (i == 0) {
if (m->child[1]->count > MIN)
leftshift(m, 1);
else
merge(m, 1);
}
else {
if (i == m->count) {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else
merge(m, i);
}
else {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else {
if (m->child[i + 1]->count > MIN)
leftshift(m, i + 1);
else
merge(m, i);
}
}
}
}
恢复():
- 函数restore()接收两个参数。首先是要还原的节点,其次是还原值的位置
- 如果第二个参数为0,则检查另一个条件以找出第一个孩子处的值是否大于所需的最小值数
- 如果是这样,则通过传递节点的地址和值1来调用函数leftshift() ,该值表示该节点的值将从第一个值开始移位
- 如果不满足条件,则调用funcition merge()合并节点的两个孩子
// Adjusts the values and children
// while shifting the value from
// parent to right child
void rightshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k];
// Copying the nodes
for (i = temp->count; i > 0; i--) {
temp->value[i + 1] = temp->value[i];
temp->child[i + 1] = temp->child[i];
}
temp->child[1] = temp->child[0];
temp->count++;
temp->value[1] = m->value[k];
temp = m->child[k - 1];
m->value[k] = temp->value[temp->count];
m->child[k]->child[0]
= temp->child[temp->count];
temp->count--;
}
// Adjusts the values and children
// while shifting the value from
// parent to left child
void leftshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k - 1];
temp->count++;
temp->value[temp->count] = m->value[k];
temp->child[temp->count]
= m->child[k]->child[0];
temp = m->child[k];
m->value[k] = temp->value[1];
temp->child[0] = temp->child[1];
temp->count--;
for (i = 1; i <= temp->count; i++) {
temp->value[i] = temp->value[i + 1];
temp->child[i] = temp->child[i + 1];
}
}
rightshift()和leftshift()
- 函数rightshift()接收两个参数
- 首先是将值从其移至其子节点的节点的地址,其次是要移入的值的位置k
- 该函数leftshift()是作为函数rightshift的完全相同()
- 函数merge()接收两个参数。首先是将值复制到子节点的节点的地址,其次是该值的位置
// Merges two nodes
void merge(struct node* m, int k)
{
int i;
struct node *temp1, *temp2;
temp1 = m->child[k];
temp2 = m->child[k - 1];
temp2->count++;
temp2->value[temp2->count] = m->value[k];
temp2->child[temp2->count] = m->child[0];
for (i = 0; i <= temp1->count; i++) {
temp2->count++;
temp2->value[temp2->count] = temp1->value[i];
temp2->child[temp2->count] = temp1->child[i];
}
for (i = k; i < m->count; i++) {
m->value[i] = m->value[i + 1];
m->child[i] = m->child[i + 1];
}
m->count--;
free(temp1);
}
- 函数merge()接收两个参数
- 首先是要将值从其复制到子节点的节点的地址,其次是该值的位置
- 在此函数,定义了两个临时变量temp1和temp2来保存要复制的值的两个子代的地址。
- 最初,该节点的值被复制到其子节点。然后,将节点的第一个子节点作为复制值的节点的相应子节点
- 然后执行两个for循环,从该循环中首先将一个孩子的所有值和孩子复制到另一个孩子
- 第二个循环移位从中复制值的节点的值和子节点
- 然后,从中复制节点的节点的计数递减。最后,通过调用free()释放第二个节点所占用的内存