数据结构中的通用散列简介
散列是一个很好的实用工具,也有一个有趣而微妙的理论。除了用作字典数据结构外,散列还出现在许多不同的领域,包括密码学和复杂性理论。
本文讨论了一个重要的概念:通用哈希(也称为通用哈希函数族)。
通用哈希是指从具有一定数学性质的哈希函数族中随机选择一个哈希函数。这确保了最小数量的冲突。
A randomized algorithm H for constructing hash functions h : U → {1,… ,M} is universal if for all (x, y) in U such that x ≠ y, Pr h∈H [h(x) = h(y)] ≤ 1/M (i.e, The probability of x and y such that h(x) = h(y) is <= 1/M for all possible values of x and y).
如果过程“随机选择h ∈ H”是通用的,则一组H散列函数称为通用散列函数族。 (这里的关键是识别在集合上具有均匀分布的函数集。)
定理:如果H是一个通用哈希函数族的集合,那么对于任何大小为N的集合S ⊆ U ,使得x ∈ U和y ∈ S ,x 和 是的 最多为N/M 。
证明:根据“普遍”的定义,每个y ∈ S (y ≠ x)最多有1/M的机会与x发生碰撞。所以,
- 如果x和y碰撞,则令C xy = 1 ,否则为 0 。
- 让C x表示x的碰撞总数。所以, C x = ∑ y∈S,x≠y C xy 。
- 我们知道E[C xy ] = Pr[ x and y collide ] ≤ 1/M 。
- 因此,根据期望的线性, E[C x ] = ∑ y E[C xy ] < N/M 。
推论:如果H是一个通用哈希函数族的集合,那么对于任意序列的L个插入、查找或删除操作,其中系统中在任何时候最多有M个元素, L个操作的预期总成本对于随机h ∈ H仅O(L) (将计算h的时间视为常数)。
对于序列中的任何给定操作,根据上述定理,其预期成本是恒定的。因此, L次操作的预期总成本是O(L) ,由期望的线性度决定。
使用矩阵方法构造一个通用哈希族:
假设键是u 位长,表大小M是2的幂,所以索引是b 位长, M = 2 b 。
我们要做的是选择h作为随机b×u 二进制矩阵,并定义h(x) = hx ,其中 hx是通过将h的某些列相加(在 mod 2 上进行矢量加法)计算得出的,其中1位在 x指示要添加的列。 (例如,在下面的示例中添加了h的第 1列和第3列)。这些矩阵又短又胖。例如:
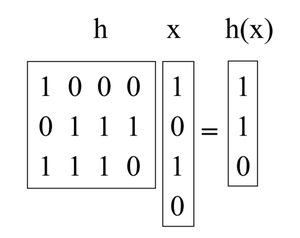
现在,取任意一对键( x, y) ,使得x ≠ y 。它们必须在某个地方有所不同,让我们假设它们在i th坐标上有所不同,具体来说x i = 0和y i = 1 。想象一下,我们首先选择所有h ,但 第i列。在第i列的剩余选择中, h(x) 是固定的。但是,第i列的2 b个不同设置中的每一个都给出了不同的h(y)值(特别是,每次我们翻转该列中的一个位时,我们都会翻转h(y)中的相应位)。所以h(x) = h(y)的概率是1/2 b 。