数据结构是在计算机中组织数据以便有效使用数据的一种特殊方式。这个想法是为了减少不同任务的空间和时间复杂性。
以下是一些流行数据结构的概述:
- 数组:数组是存储在连续内存位置的项目的集合。这个想法是将多个相同类型的项目存储在一起。这使得通过简单地将偏移量添加到基值,即数组的第一个元素的内存位置(通常由数组的名称表示)来更容易地计算每个元素的位置。
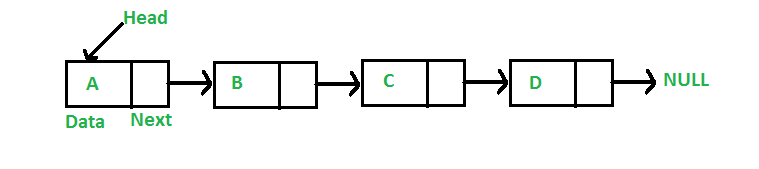
- 链表:与数组一样,链表是一种线性数据结构。与数组不同,链表元素不存储在连续的位置;元素使用指针链接。
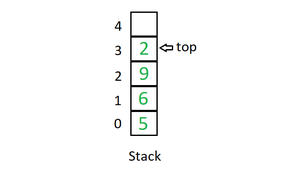
- 堆栈:堆栈是一种线性数据结构,它遵循执行操作的特定顺序。顺序可能是 LIFO(后进先出)或 FILO(先进后出)。

在栈中主要进行以下三个基本操作:
- 推送:在堆栈中添加一个项目。如果堆栈已满,则称其为溢出条件。
- Pop:从堆栈中移除一个项目。这些项目以它们被推送的相反顺序弹出。如果堆栈为空,则称其为下溢条件。
- Peek 或 Top:返回堆栈的顶部元素。
- isEmpty:如果堆栈为空则返回true,否则返回false。
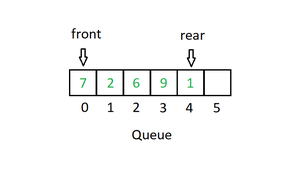
- 队列:与堆栈一样,队列是一个线性结构,它遵循特定的操作顺序。顺序是先进先出 (FIFO)。队列的一个很好的例子是资源的任何消费者队列,其中先来的消费者首先得到服务。堆栈和队列之间的区别在于删除。在堆栈中,我们删除最近添加的项目;在队列中,我们删除最近最少添加的项目。
主要对队列进行以下四个基本操作:
- 入队:将项目添加到队列中。如果队列已满,则称其为溢出条件。
- Dequeue:从队列中移除一个项目。项目以与推送相同的顺序弹出。如果队列为空,则称其为下溢条件。
- Front:从队列中获取最前面的项目。
- 后:从队列中获取最后一项。
- 二叉树:与数组、链表、堆栈和队列这些线性数据结构不同,树是分层数据结构。二叉树是一种树数据结构,其中每个节点最多有两个孩子,分别称为左孩子和右孩子。它主要使用链接来实现。
二叉树由指向树中最顶层节点的指针表示。如果树为空,则 root 的值为 NULL。二叉树节点包含以下部分。
1. Data 2. Pointer to left child 3. Pointer to the right child - 二叉搜索树:在二叉搜索树中是一棵具有以下附加属性的二叉树:
- 节点的左子树只包含键小于节点键的节点。
- 节点的右子树仅包含键大于节点键的节点。
- 左右子树也必须是二叉搜索树。
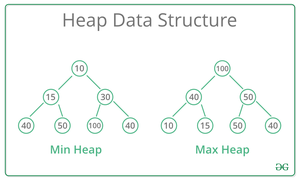
- 堆:堆是一种特殊的基于树的数据结构,其中树是一棵完整的二叉树。通常,堆可以有两种类型:
- Max-Heap:在 Max-Heap 中,存在于根节点的键必须是其所有子节点存在的键中最大的。对于该二叉树中的所有子树,相同的属性必须递归为真。
- 最小堆:在最小堆中,存在于根节点的键必须是其所有子节点存在的键中的最小值。对于该二叉树中的所有子树,相同的属性必须递归为真。

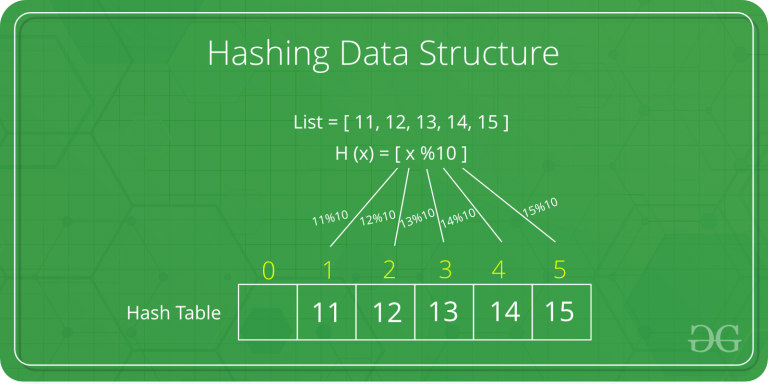
- 散列数据结构:散列是一种重要的数据结构,它旨在使用称为散列函数的特殊函数,该函数用于将给定值与特定键映射,以便更快地访问元素。映射的效率取决于所使用的哈希函数的效率。
让散列函数H(x) 映射数组中索引 x%10 处的值 x。例如,如果值列表是 [11, 12, 13, 14, 15] 它将分别存储在数组或哈希表中的位置 {1, 2, 3, 4, 5} 。
- 矩阵:矩阵表示按行和列的顺序排列的数字集合。有必要用圆括号或方括号将矩阵的元素括起来。
下面显示了一个包含 9 个元素的矩阵。
- Trie: Trie 是一种高效的信息重新Trie val 数据结构。使用 Trie,搜索复杂度可以达到最佳限制(密钥长度)。如果我们将键存储在二叉搜索树中,一个平衡良好的 BST 将需要与 M * log N 成正比的时间,其中 M 是最大字符串长度,N 是树中键的数量。使用 Trie,我们可以在 O(M) 时间内搜索密钥。但是,惩罚是针对 Trie 存储要求的。
如果您希望与专家一起参加现场课程,请参阅DSA 现场工作专业课程和学生竞争性编程现场课程。