L1 正则化如何带来稀疏性
先决条件:机器学习中的正则化
我们知道我们在训练机器学习模型时使用正则化来避免欠拟合和过拟合。为此,我们主要使用两种方法,即:L1 正则化和 L2 正则化。
L1 正则化器:
||w||1=( |w1|+|w2|+ . . . + |wn|
L2 正则化器:
||w||2=( |w1|2+|w2|2+ . . . + |wn|2 )1/2
(其中w 1 ,w 2 … w n是 ' d ' 维权重向量)
现在,在基于梯度下降算法的概念进行优化时,可以看出如果我们使用 L1 正则化,它会通过将较小的权重设为零来为我们的权重向量带来稀疏性。让我们看看如何,但首先让我们了解一些基本概念
稀疏向量或矩阵:其元素的最大值为零的向量或矩阵称为稀疏向量或矩阵。
梯度下降算法:
Wt=W(t-1) – η* ( ∂L(w)/∂(w) )W(t-1)
(其中 η 是一个叫做学习率的小值)
根据梯度下降算法,当收敛发生时我们得到了答案。当 W t的值随着进一步迭代而变化不大时发生收敛,或者我们可以说当我们得到最小值时,即 (∂(Loss)/∂w) W(t-1)变得近似等于 0,因此, W t ~ W t-1 。
假设我们有一个线性回归优化问题(我们可以将其用于任何模型),其方程为:
argmin(W) [ loss + (regularizer) ]
i.e. Find that W which will minimize the loss function在这里,我们将忽略损失项,只关注正则化项,以便我们更轻松地分析我们的任务。
案例1(采用L1):
Optimisation equation= argmin(W) |W|
(∂|W|/∂w) = 1
thus, according to GD algorithm Wt = Wt-1 - η*1在这里,我们可以看到我们的损失导数变得恒定,因此收敛条件发生得更快,因为我们的减法项中只有 η 并且它没有乘以任何较小的 W 值。因此我们的 W t在只有几次迭代。但这将阻碍我们收敛的条件,我们将在下一个案例中看到。
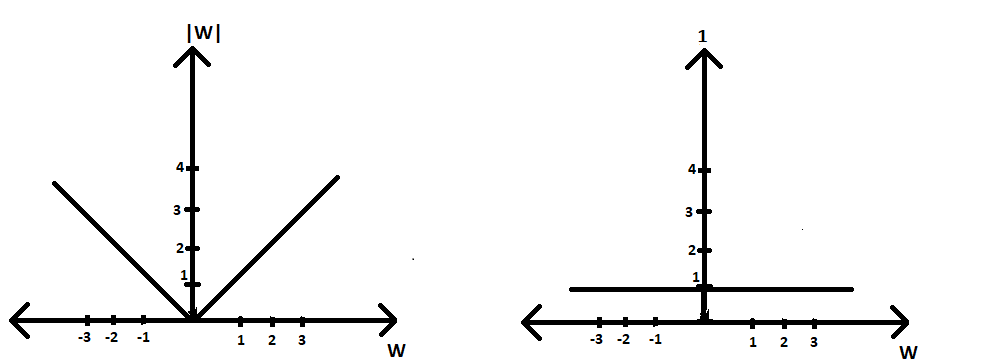
L1 正则化器与 w(∂|W|/∂w) 与 w 的关系图
案例2(采用L2):
Optimisation equation=argmin(W) |W|2
(∂|W|2/∂W) = 2|W|
thus, according to GD algorithm Wt = Wt-1 - 2*η*|W|因此,我们可以看到我们的损失导数项不是常数,因此对于较小的 W 值,我们的收敛条件不会发生得更快(或者可能根本不会发生),因为我们有较小的 W 值与 η 相乘,从而使整个项要减去更小。因此,经过几次迭代后,我们的 W t变成了一个非常小的常数值,但不是零。因此,不会导致权重向量的稀疏性。
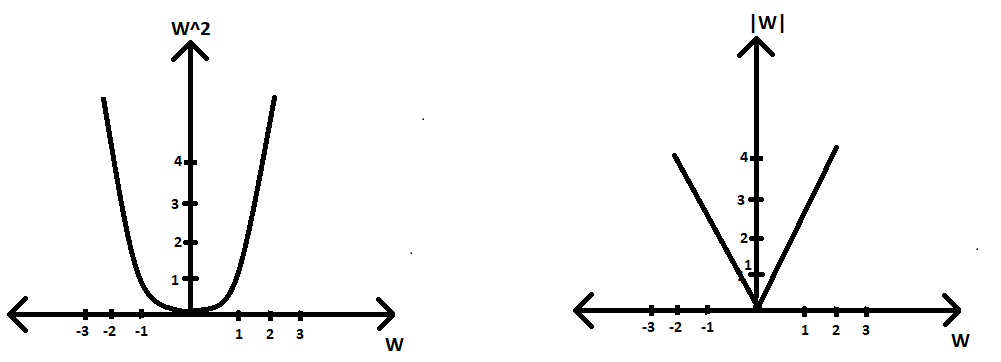
L2 正则化器与 w 的关系图;右侧:∂|W| 的图2 /∂W) vs w