使用知识蒸馏和 GAN 生成文本
最常用的文本生成方法是循环神经网络。然而,基于 RNN 的文本生成器使用最大似然估计使用先前的观察来预测下一个单词/句子。然而,基于最大似然 (MLE) 的估计器过于简单并且存在暴露偏差。在题为“T extKD-GAN: Text Generation using Knowledge Distillation and Generative Adversarial Networks ”的论文中,华为诺亚方舟实验室的研究人员发表了论文。作者探索了 GAN 在这个 NLP 任务中的使用,并提出了一个做同样事情的 GAN 架构。
知识蒸馏:知识蒸馏是一种模型压缩方法,其中训练小模型以模仿预先训练的较大模型(或模型集合)。这个训练集有时被称为“师生”,其中大模型是老师,小模型是学生。学生模型的作用是模仿较大(教师)模型的特征,例如隐藏表示、输出概率或它们生成的句子(例如)。
建筑学:
在本文中,作者使用生成模型 (GAN) 作为学生,试图模仿 Autoencoder 的输出表示,而不是映射到文本的 one-hot 表示。
将介绍几种使用 GAN 生成文本的方法,其中之一是 W-GAN。 W-GAN 的问题在于鉴别器接收来自 softmax 和 one-hot 表示的输出,编码的差异有助于鉴别器轻松区分真实编码和生成编码之间的差异。本文通过提供单词的连续平滑表示而不是 one-hot 来解决这个问题,并训练鉴别器来区分连续表示。在本文中,作者使用传统的自动编码器将 one-hot 表示替换为 softmax 重构输出,这是一种平滑表示,可产生较小的梯度方差。
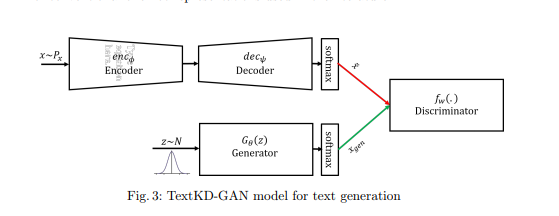
对于自动编码器架构,本文训练使用 512 个长短期记忆 (LSTM) 单元作为编码器和解码器部分。本文首先训练自动编码器部分,然后训练 GAN 架构(首先是鉴别器部分,然后是生成器部分)。
损失函数:
Autoencoder 和 GAN 架构的训练是同时进行的。为此,使用了 3 个损失函数,它们是:
- Autoencoder 的重建损失项。
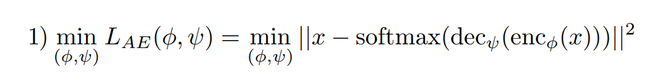
- 带有梯度惩罚的判别器损失函数。
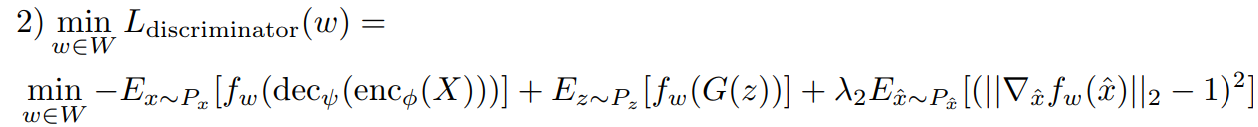
- 生成器的对抗性 GAN 损失。
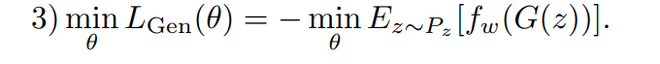
结果:
作者在两个不同的数据集上对该模型进行了实验:斯坦福自然语言语料库 (SNLI) 和谷歌 10 亿基准语言建模数据。作者使用 BLEU-N 分数来计算模型的结果并将其与之前最先进的架构进行比较。 BLEU 分数可以计算为:

其中 BP 是简洁惩罚,p n是字谜的概率,w n = 1/n。
- 不同模型在谷歌 10 亿基准数据集上的 BLEU 得分如下:

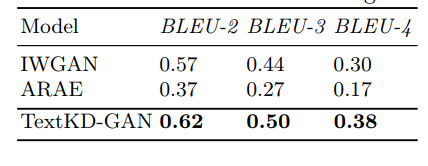
- 不同模型在斯坦福自然语言推理数据集上的BLEU-N得分如下
使用斯坦福自然语言推理 (SNLI) 数据集生成的文本示例如下:

这里是 IWGAN(改进的 Wasserstein GAN)和 ARAE(对抗性正则化自动编码器)。
参考:
- TextKD-GAN 论文