📌 相关文章
- 使用散列的地址计算排序(1)
- 使用散列的地址计算排序
- python中的散列(1)
- 使用哈希的地址计算排序
- 使用哈希的地址计算排序(1)
- python代码示例中的散列
- 地址已在使用中 - Python (1)
- Java的散列(1)
- Java的散列
- 地址已在使用中 - Python 代码示例
- 地址已在使用中 (1)
- 使用中的地址 (1)
- 数组散列到一个散列 - Ruby 代码示例
- 使用多项式滚动散列函数字符串散列(1)
- 使用多项式滚动散列函数字符串散列
- 使用多项式滚动散列函数字符串散列(1)
- 使用多项式滚动散列函数字符串散列
- 图像散列 - Python 代码示例
- 在 python 代码示例中使用链接在 python 中进行散列
- 散列函数和散列函数的列表类型(1)
- 散列函数和散列函数的列表/类型
- 计算N维数组中元素的地址(1)
- 计算N维数组中元素的地址
- 计算N维数组中元素的地址
- 计算 N 维数组中元素的地址
- 计算 N 维数组中元素的地址(1)
- 散列的应用
- 散列的应用
- 散列的应用(1)
📜 Python使用散列的地址计算排序
📅 最后修改于: 2020-05-06 04:39:48 🧑 作者: Mango
在此排序算法中,哈希函数f与Order Preserving Function的属性一起使用,该属性声明如果 。
。
哈希函数:
f(x) = floor( (x/maximum) * SIZE )
where maximum => maximum value in the array,
SIZE => size of the address table (10 in our case),
floor => floor function该算法使用地址表存储值,该值只是一个链表的列表(或数组)。哈希函数应用于数组中的每个值,以在地址表中找到其对应的地址。然后,通过将这些值与该地址中已经存在的值进行比较,以有序的方式将其插入到其对应的地址中。
例子:
Input : arr = [29, 23, 14, 5, 15, 10, 3, 18, 1]
Output:
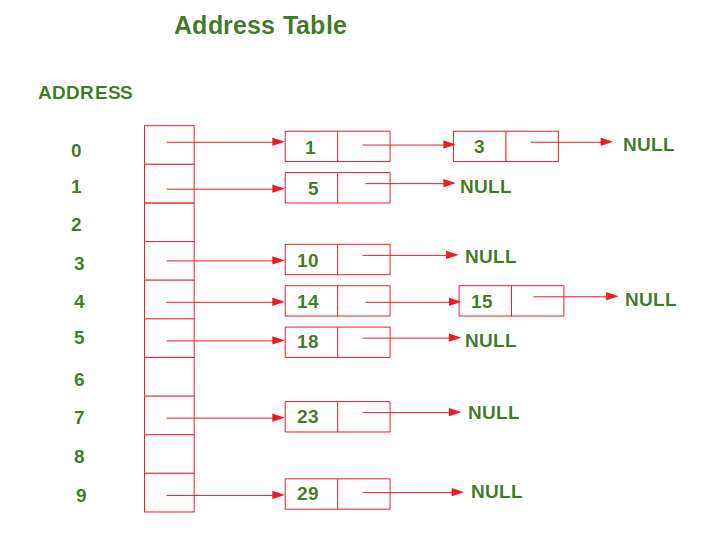
After inserting all the values in the address table, the address table looks like this:
ADDRESS 0: 1 --> 3
ADDRESS 1: 5
ADDRESS 2:
ADDRESS 3: 10
ADDRESS 4: 14 --> 15
ADDRESS 5: 18
ADDRESS 6:
ADDRESS 7: 23
ADDRESS 8:
ADDRESS 9: 29下图显示了上面讨论的示例的地址表的表示形式:

插入后,将对地址表中每个地址的值进行排序。因此,我们一个接一个地遍历每个地址,并将值插入该地址到输入数组中。
下面是上述方法的实现
# 使用哈希实现地址计算排序的Python3代码
# 地址表的大小(在这种情况下为0-9)
SIZE = 10
class Node(object):
def __init__(self, data = None):
self.data = data
self.nextNode = None
class LinkedList(object):
def __init__(self):
self.head = None
# 以使列表保持排序的方式插入值
def insert(self, data):
newNode = Node(data)
# 如果没有节点,或者新节点的值小于列表中的第一个值,则将新节点插入第一个位置
if self.head == None or data < self.head.data:
newNode.nextNode = self.head
self.head = newNode
else:
current = self.head
# 如果下一个节点为空或其值大于新节点的值,则在该位置插入新节点
while current.nextNode != None \
and \
current.nextNode.data < data:
current = current.nextNode
newNode.nextNode = current.nextNode
current.nextNode = newNode
# 此函数使用“地址计算"和“哈希"对给定列表进行排序
def addressCalculationSort(arr):
# 声明给定SIZE的链接列表的列表
listOfLinkedLists = []
for i in range(SIZE):
listOfLinkedLists.append(LinkedList())
# 计算数组中的最大值
maximum = max(arr)
# 在地址表中找到每个值的地址将其插入该列表
for val in arr:
address = hashFunction(val, maximum)
listOfLinkedLists[address].insert(val)
# 插入所有值后,打印地址表
for i in range(SIZE):
current = listOfLinkedLists[i].head
print("ADDRESS " + str(i), end = ": ")
while current != None:
print(current.data, end = " ")
current = current.nextNode
print()
# 将排序后的值分配给输入数组
index = 0
for i in range(SIZE):
current = listOfLinkedLists[i].head
while current != None:
arr[index] = current.data
index += 1
current = current.nextNode
# 该函数返回地址表中给定值的对应地址
def hashFunction(num, maximum):
# 缩放值,使地址在0到9之间
address = int((num * 1.0 / maximum) * (SIZE-1))
return address
# -------------------------------------------------------
# 测试代码
# 输入地址如下
arr = [29, 23, 14, 5, 15, 10, 3, 18, 1]
# 打印输入数组
print("\n输入数组: " + " ".join([str(x) for x in arr]))
# 执行地址计算排序
addressCalculationSort(arr)
# 打印结果排序数组
print("\n排序数组: " + " ".join([str(x) for x in arr]))输出:
输入数组: 29 23 14 5 15 10 3 18 1
ADDRESS 0: 1 3
ADDRESS 1: 5
ADDRESS 2:
ADDRESS 3: 10
ADDRESS 4: 14 15
ADDRESS 5: 18
ADDRESS 6:
ADDRESS 7: 23
ADDRESS 8:
ADDRESS 9: 29
排序数组: 1 3 5 10 14 15 18 23 29时间复杂度:
此算法的时间复杂度是O(n),是最佳情况。当数组中的值均匀分布在特定范围内时,会发生这种情况。
而最坏情况下的时间复杂度是![]() 。当大多数值占用1或2个地址时就会发生这种情况,因为需要大量工作才能将每个值插入其适当位置。
。当大多数值占用1或2个地址时就会发生这种情况,因为需要大量工作才能将每个值插入其适当位置。