深度学习模型大致分为监督模型和非监督模型。
监督的DL模型:
- 人工神经网络(ANN)
- 递归神经网络(RNN)
- 卷积神经网络(CNN)
无监督的DL模型:
- 自组织图(SOM)
- 玻尔兹曼机
- 自动编码器
让我们了解玻尔兹曼机器到底是什么,它们如何工作,并实现一个推荐系统,该系统根据之前观看的电影来推荐用户是否喜欢电影。
Boltzmann Machines是一种无监督的DL模型,其中每个节点都与其他每个节点相连。也就是说,与ANN,CNN,RNN和SOM不同,Boltzmann机器是无向的(或连接是双向的)。 Boltzmann机器不是确定性的DL模型,而是随机的或生成的DL模型。它只是某种系统的表示。 Boltzmann机器中有两种类型的节点-可见节点-我们可以并且可以测量的节点,以及隐藏节点-我们不能或不测量的节点。尽管节点类型不同,但Boltzmann机器认为它们是相同的,并且所有内容都可以作为一个系统工作。训练数据被输入到Boltzmann机器中,系统的权重也相应地进行了调整。玻尔兹曼机器通过了解系统在正常条件下的工作情况来帮助我们了解异常情况。
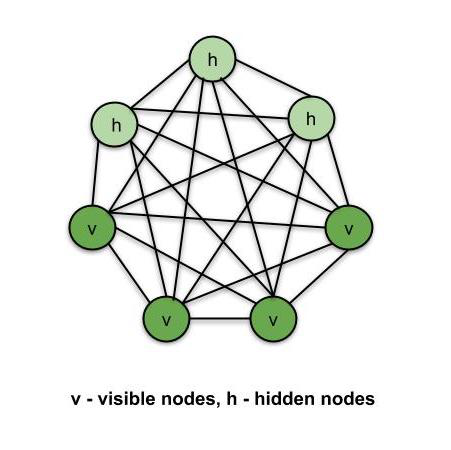
玻尔兹曼机
基于能量的模型:
Boltzmann分布用于Boltzmann机的采样分布。玻尔兹曼分布受以下方程式控制–
Pi = e(-∈i/kT)/ ∑e(-∈j/kT)
Pi - probability of system being in state i
∈i - Energy of system in state i
T - Temperature of the system
k - Boltzmann constant
∑e(-∈j/kT) - Sum of values for all possible states of the system
Boltzmann分布描述了系统的不同状态,因此Boltzmann机器使用此分布创建了不同的机器状态。根据上式,随着系统能量的增加,系统进入状态“ i”的概率降低。因此,系统在最低能量状态下最稳定(气体扩散时最稳定)。在此,在玻尔兹曼机器中,系统的能量是根据突触的权重来定义的。一旦对系统进行了训练并设置了权重,系统将始终尝试通过调整权重来为其自身找到最低的能量状态。
玻尔兹曼机器的类型:
- 受限玻尔兹曼机(RBM)
- 深度信仰网络(DBN)
- 深玻尔兹曼机(DBM)
受限玻尔兹曼机(RBM):
在完整的Boltzmann机器中,每个节点都与其他每个节点连接,因此连接呈指数增长。这就是我们使用RBM的原因。 RBM中的节点连接限制如下:
- 隐藏的节点无法相互连接。
- 可见的节点相互连接。
受限玻尔兹曼机的能量函数示例–
E(v, h) = -∑ aivi - ∑ bjhj - ∑∑ viwi,jhj
a, v - biases in the system - constants
vi, hj - visible node, hidden node
P(v, h) = Probability of being in a certain state
P(v, h) = e(-E(v, h))/Z
Z - sum if values for all possible states
假设我们正在使用RBM构建可在六(6)部电影上使用的推荐器系统。 RBM学习如何将隐藏节点分配给某些功能。通过对比分歧的过程,我们使成果管理制接近我们的电影或情节场景。 RBM在培训过程中确定哪些功能很重要。根据用户是喜欢该电影(1),不喜欢该电影(0)还是不观看该电影,训练数据是0或1或丢失数据(丢失数据)。 RBM自动识别重要功能。
对比发散:
RBM通过这种方法调整其权重。使用一些随机分配的初始权重,RBM计算隐藏节点,然后使用相同的权重来重构输入节点。每个隐藏节点都是从所有可见节点构建的,每个可见节点都是从所有隐藏节点重建的,因此,尽管权重相同,但输入与重建的输入是不同的。该过程继续进行,直到重构的输入与先前的输入匹配为止。据说该过程在此阶段已经收敛。这整个过程称为Gibbs采样。
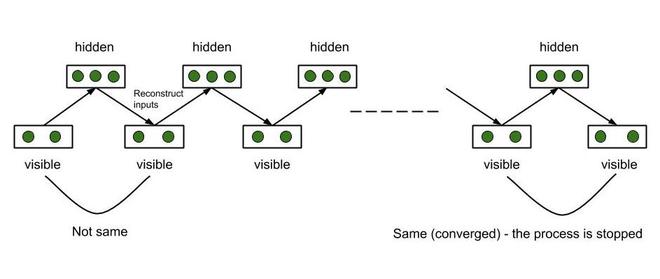
吉布的采样
梯度公式给出了系统某种状态的对数概率相对于系统权重的梯度。给出如下-
d/dwij(log(P(v0))) = -
v - visible state, h- hidden state
- initial state of the system
- final state of the system
P(v0) - probability that the system is in state v0
wij - weights of the system
上面的方程式告诉我们–系统权重的变化将如何将系统的对数概率变为特定状态。系统试图以尽可能低的能量状态(最稳定)结束。除了可以继续进行权重调整过程,直到当前输入与上一个输入匹配为止,我们还可以仅考虑前几个暂停。了解如何调整曲线以获取最低的能量状态就足够了。因此,我们调整权重,重新设计系统和能量曲线,以便获得当前位置的最低能量。这就是Hinton的快捷方式。
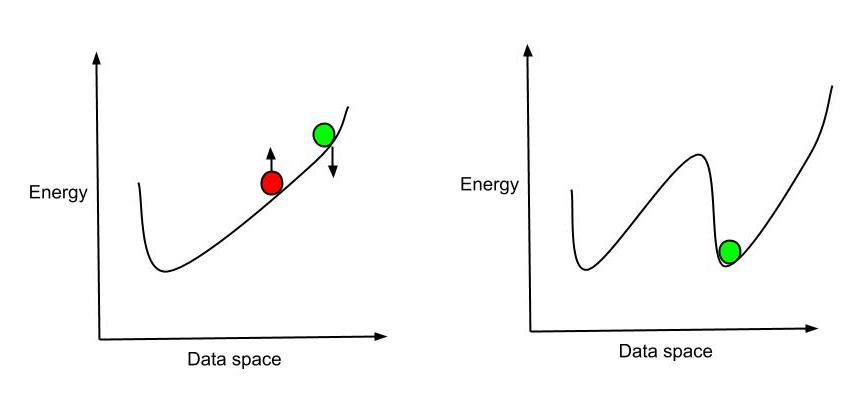
欣顿的捷径
注重成果的管理的工作–说明性例子–
考虑一下-玛丽观看了六部可用电影中的四部电影,并对其中四部进行了评分。说,她看了m 1 ,m 3 ,m 4和m 5 ,喜欢m 3 ,m 5 (等级1),不喜欢另外两个,即m 1 ,m 4 (等级0),而其他两部电影– m2 ,m6未分级。现在,使用我们的RBM,我们将推荐其中一部电影供她接下来观看。说 –
- m 3 ,m 5属于“戏剧”类型。
- m 1 ,m 4属于“动作”类型。
- “迪卡普里奥”在m 5中起了作用。
- m 3 ,m 5赢得了“奥斯卡”。
- “塔兰蒂诺”导演m 4 。
- m 2是“动作”类型。
- m 6是“动作”和“戏剧”两种类型,其中“迪卡普里奥”(Dicaprio)参与其中,并获得了“奥斯卡”奖。
我们有以下观察–
- 玛丽喜欢m 3 ,m 5 ,他们属于“戏剧”类型,她可能喜欢“戏剧”电影。
- 玛丽不喜欢m 1 ,m 4,而且它们属于动作类型,她可能不喜欢“动作”电影。
- 玛丽喜欢m 3 ,m 5并且他们赢得了“奥斯卡”,她可能喜欢“奥斯卡”电影。
- 由于“狄卡普里奥”在m 5演出,而玛丽喜欢它,她可能会喜欢“狄卡普里奥”在其中演出的电影。
- 玛丽不喜欢塔伦蒂诺执导的《 m 4》 ,她可能不喜欢《塔兰蒂诺》执导的电影。
因此,根据观察和m 2 ,m 6的细节;我们的RBM向玛丽推荐m6 (“戏剧”,“迪卡普里奥”和“奥斯卡”与玛丽的兴趣和m 6都匹配)。这就是RBM的工作方式,因此被用于推荐系统。
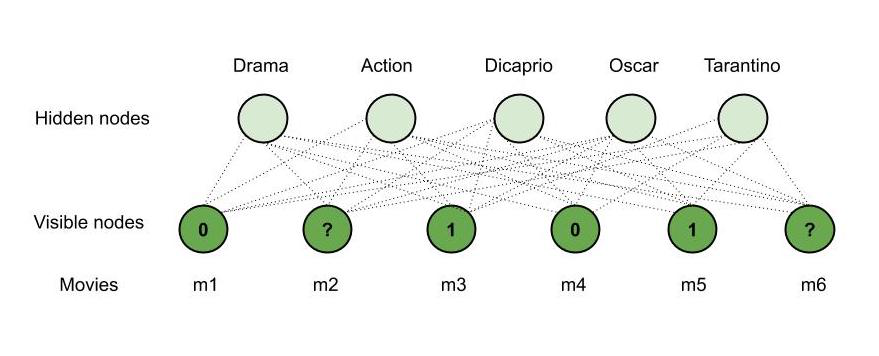
注重成果的管理的工作
因此,RBM用于构建推荐系统。
深度信仰网络(DBN):
假设我们将几个RBM堆叠在一起,以便第一个RBM输出是第二个RBM的输入,依此类推。这样的网络称为“深层信任网络”。每层内的连接都是无向的(因为每层都是RBM)。同时,两层之间的对象是有方向的(最顶层的两层除外-顶层之间的连接是无向的)。有两种训练DBN的方法-
- 贪婪的逐层训练算法– RBM是逐层训练的。训练完各个RBM之后(即,设置了参数-权重,偏差),便在DBN层之间建立了方向。
- 唤醒睡眠算法–一直对DBN进行全面培训(连接上升–唤醒),然后对网络进行培训(连接下降–睡眠)。
因此,我们堆叠RBM,对其进行训练,并且一旦我们对参数进行了训练,我们确保各层之间的连接仅向下工作(最顶层的两层除外)。
深玻尔兹曼机(DBM):
DBMS类似于动态贝叶斯网不同之处在于除了层内的连接,层与层之间的连接也被无向(不像DBN,其中层与层之间的连接所涉及的)。 DBM可以提取更复杂或更复杂的功能,因此可以用于更复杂的任务。