我们已经讨论了Boyer Moore算法的不良字符启发式变体。在本文中,我们将讨论模式搜索的良好后缀启发式方法。就像不良字符启发式一样,生成了用于后缀良好启发式的预处理表。
良好的后缀启发式
令t为与模式P的子字符串匹配的文本T的子字符串。现在我们将模式转移到:
1)P中t的另一次出现与T中的t匹配。
2)P的前缀,与t的后缀匹配
3)P越过t
情况1:P中t的另一次出现与T中的t匹配
模式P可能包含t的更多出现。在这种情况下,我们将尝试移动模式以使该出现与文本T中的t对齐。例如-
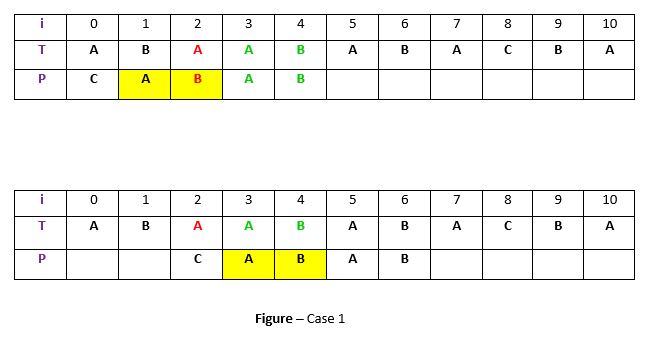
说明:在上面的示例中,我们获得了文本T的子字符串t,该字符串与模式P匹配(绿色),然后在索引2处不匹配。现在,我们将在P中搜索t的出现(“ AB”)。发生在位置1(在黄色背景中)开始,因此我们将模式右移2次以使t中的t与T中的t对齐。这是原始的Boyer Moore的弱规则,效果不大,我们将讨论Strong Good Suffix规则不久。
情况2:P的前缀,与T中的t的后缀匹配
并非总是可能在P中找到t的出现。有时根本没有出现,在这种情况下,有时我们可以搜索与P的某些前缀匹配的t的后缀,并尝试通过移动P来对齐它们。 例如 –

说明:在上面的示例中,在不匹配之前,我们在索引2-4处将t(“ BAB”)与P(绿色)匹配。但是,因为在P中不存在t,所以我们将搜索与t的后缀匹配的P前缀。我们发现前缀“ AB”(在黄色背景中)从索引0开始,它与整数t不匹配,但与后缀t从索引3开始的“ AB”匹配。因此,我们现在将模式转换3次以使前缀与后缀对齐。
情况3:P越过t
如果以上两种情况都不满足,我们将把模式移到t之后。例如 –
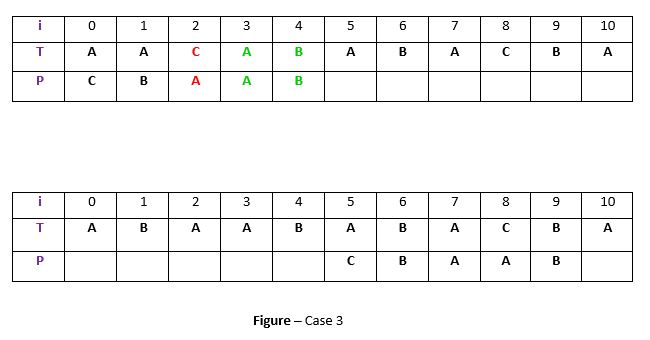
说明:如果在上面的示例中,则P中不存在t(“ AB”),并且P中也没有与t后缀相匹配的前缀。因此,在那种情况下,我们永远无法在索引4之前找到任何完美匹配,因此我们会将P移过t ie。索引5。
强后缀启发式
假设子串q = P [i至n]与T中的t匹配,而c = P [i-1]是不匹配字符。现在,与情况1不同,我们将在P中搜索t,该t后面不包含字符c 。然后,通过移动模式P将最接近的这种情况与T中的t对齐。例如–
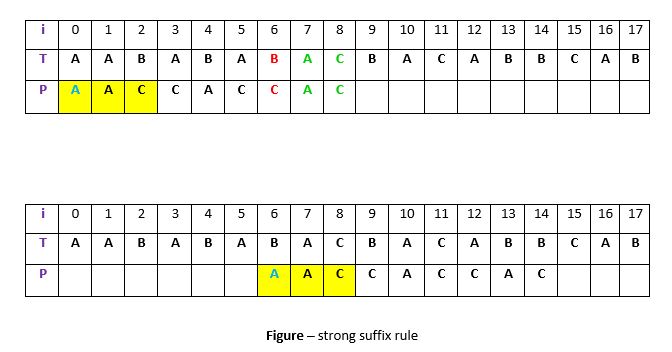
说明:在上面的示例中, q = P [7至8]在T中与t匹配。不匹配的字符c在位置P [6]处为“ C”。现在,如果我们开始在P中搜索t,我们将从位置4开始获得t的第一个匹配项。但是,该匹配项的前面是等于c的“ C”,因此我们将跳过它并继续搜索。在位置1,我们再次出现了t(在黄色背景中)。此事件之前是“ A”(蓝色),不等同于c。因此,我们将模式P移位6次,以使这种情况与T中的t对齐。我们这样做是因为我们已经知道字符c =“ C”会导致不匹配。因此,如果出现任何以c开头的t,当与t对齐时,都会再次导致不匹配,因此,最好跳过此步骤。
良好后缀启发式的预处理
作为预处理的一部分,将创建一个数组移位。如果在位置i-1发生不匹配,则每个包含shift [i]的条目都将偏移距离模式。即,从位置i开始的模式的后缀匹配,并且在位置i-1发生不匹配。对于强后缀和上面讨论的情况2,分别进行预处理。
1)预处理以获得良好的后缀
在讨论预处理之前,让我们首先讨论边界的概念。边框是一个既是后缀又是前缀的子字符串。例如,在字符串“ ccacc”中, “ c”是边界, “ cc”是边界,因为它出现在字符串的两端,但“ cca”不是边界。
作为预处理的一部分,将计算数组bpos (边界位置)。每个条目bpos [i]都包含给定模式P中从索引i开始的后缀的边界起始索引。
从位置m开始的后缀φ没有边界,因此bpos [m]设置为m + 1 ,其中m是模式的长度。
移位位置由无法向左扩展的边界获得。以下是预处理代码–
void preprocess_strong_suffix(int *shift, int *bpos,
char *pat, int m)
{
int i = m, j = m+1;
bpos[i] = j;
while(i > 0)
{
while(j <= m && pat[i-1] != pat[j-1])
{
if (shift[j] == 0)
shift[j] = j-i;
j = bpos[j];
}
i--; j--;
bpos[i] = j;
}
}
说明:考虑模式P =“ ABBABAB”,m = 7 。
- 从位置i = 5开始的后缀“ AB”的最宽边界是从位置7开始的φ(无),因此bpos [5] = 7。
- 在位置i = 2时,后缀为“ BABAB”。此后缀的最大边框是从位置4开始的“ BAB”,因此j = bpos [2] = 4。
我们可以使用以下示例了解bpos [i] = j –

如果字符#哪个位置i-1是等于字符?在位置j-1处,我们知道边界将是? +从位置j开始的位置i处的后缀边界,这等效于说在i-1处的后缀边界从j-1或bpos [i-1] = j-1或代码中开始–
i--; j--; bpos[ i ] = j但是,如果位置i-1处的字符#与字符不匹配?在位置j-1处,然后我们继续向右搜索。现在我们知道–
- 边框宽度将小于从位置j开始的边框。小于x…φ
- 边框必须以#开头并以φ结尾,或者可以为空(不存在边框)。
基于以上两个事实,我们将继续在子字符串x…φ中从位置j到m进行搜索。下一个边界应该在j = bpos [j]处。更新j之后,我们再次将位置j-1(?)的字符与#进行比较,如果它们相等,则得到边界,否则继续向右搜索直到j> m 。此过程由代码显示–
while(j <= m && pat[i-1] != pat[j-1]) { j = bpos[j]; } i--; j--; bpos[i]=j;在上面的代码中查看这些条件–
pat[i-1] != pat[j-1]这是我们在壳体2所讨论的。当T的图案P的发生之前的字符比P中不匹配的字符不同,我们停止跳过发生和转移模式的条件。所以这里P [i] == P [j]但P [i-1]!= p [j-1]因此我们将模式从i转移到j 。因此, shift [j] = ji是j的记录器。因此,无论何时在位置j发生任何不匹配,我们都将模式shift [j + 1]位置向右移动。
在上面的代码中,以下条件非常重要–if (shift[j] == 0 )该条件防止了具有相同边界的后缀对shift [j]值的修改。例如,考虑模式P =“ addbddcdd” ,在这种情况下,当我们为i = 4计算bpos [i-1]时,则j = 7。我们最终将设置shift [7] = 3的值。现在,如果我们为i = 1计算bpos [i-1],则j = 7,如果没有测试,我们将再次设置shift [7] = 6的值shift [j] ==0。这意味着如果我们在位置6不匹配,我们将模式P 3的位置移到右侧而不是6位置。
2)案例2的预处理
在情况2的预处理中,对于每个后缀,确定该后缀中包含的整个模式的最宽边界。
模式最宽边框的起始位置完全存储在bpos [0]中
在下面的预处理算法中,该值bpos [0]最初存储在数组移位的所有空闲条目中。但是,当模式的后缀比bpos [0]短时,算法将继续使用模式的下一个较宽边界,即bpos [j]。以下是搜索算法的实现–
C++
/* C program for Boyer Moore Algorithm with Good Suffix heuristic to find pattern in given text string */ #include#include // preprocessing for strong good suffix rule void preprocess_strong_suffix(int *shift, int *bpos, char *pat, int m) { // m is the length of pattern int i=m, j=m+1; bpos[i]=j; while(i>0) { /*if character at position i-1 is not equivalent to character at j-1, then continue searching to right of the pattern for border */ while(j<=m && pat[i-1] != pat[j-1]) { /* the character preceding the occurrence of t in pattern P is different than the mismatching character in P, we stop skipping the occurrences and shift the pattern from i to j */ if (shift[j]==0) shift[j] = j-i; //Update the position of next border j = bpos[j]; } /* p[i-1] matched with p[j-1], border is found. store the beginning position of border */ i--;j--; bpos[i] = j; } } //Preprocessing for case 2 void preprocess_case2(int *shift, int *bpos, char *pat, int m) { int i, j; j = bpos[0]; for(i=0; i<=m; i++) { /* set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 */ if(shift[i]==0) shift[i] = j; /* suffix becomes shorter than bpos[0], use the position of next widest border as value of j */ if (i==j) j = bpos[j]; } } /*Search for a pattern in given text using Boyer Moore algorithm with Good suffix rule */ void search(char *text, char *pat) { // s is shift of the pattern with respect to text int s=0, j; int m = strlen(pat); int n = strlen(text); int bpos[m+1], shift[m+1]; //initialize all occurrence of shift to 0 for(int i=0;i
Java
/* Java program for Boyer Moore Algorithm with Good Suffix heuristic to find pattern in given text string */ class GFG { // preprocessing for strong good suffix rule static void preprocess_strong_suffix(int []shift, int []bpos, char []pat, int m) { // m is the length of pattern int i = m, j = m + 1; bpos[i] = j; while(i > 0) { /*if character at position i-1 is not equivalent to character at j-1, then continue searching to right of the pattern for border */ while(j <= m && pat[i - 1] != pat[j - 1]) { /* the character preceding the occurrence of t in pattern P is different than the mismatching character in P, we stop skipping the occurrences and shift the pattern from i to j */ if (shift[j] == 0) shift[j] = j - i; //Update the position of next border j = bpos[j]; } /* p[i-1] matched with p[j-1], border is found. store the beginning position of border */ i--; j--; bpos[i] = j; } } //Preprocessing for case 2 static void preprocess_case2(int []shift, int []bpos, char []pat, int m) { int i, j; j = bpos[0]; for(i = 0; i <= m; i++) { /* set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 */ if(shift[i] == 0) shift[i] = j; /* suffix becomes shorter than bpos[0], use the position of next widest border as value of j */ if (i == j) j = bpos[j]; } } /*Search for a pattern in given text using Boyer Moore algorithm with Good suffix rule */ static void search(char []text, char []pat) { // s is shift of the pattern // with respect to text int s = 0, j; int m = pat.length; int n = text.length; int []bpos = new int[m + 1]; int []shift = new int[m + 1]; //initialize all occurrence of shift to 0 for(int i = 0; i < m + 1; i++) shift[i] = 0; //do preprocessing preprocess_strong_suffix(shift, bpos, pat, m); preprocess_case2(shift, bpos, pat, m); while(s <= n - m) { j = m - 1; /* Keep reducing index j of pattern while characters of pattern and text are matching at this shift s*/ while(j >= 0 && pat[j] == text[s+j]) j--; /* If the pattern is present at the current shift, then index j will become -1 after the above loop */ if (j < 0) { System.out.printf("pattern occurs at shift = %d\n", s); s += shift[0]; } else /*pat[i] != pat[s+j] so shift the pattern shift[j+1] times */ s += shift[j + 1]; } } // Driver Code public static void main(String[] args) { char []text = "ABAAAABAACD".toCharArray(); char []pat = "ABA".toCharArray(); search(text, pat); } } // This code is contributed by 29AjayKumar
Python3
# Python3 program for Boyer Moore Algorithm with # Good Suffix heuristic to find pattern in # given text string # preprocessing for strong good suffix rule def preprocess_strong_suffix(shift, bpos, pat, m): # m is the length of pattern i = m j = m + 1 bpos[i] = j while i > 0: '''if character at position i-1 is not equivalent to character at j-1, then continue searching to right of the pattern for border ''' while j <= m and pat[i - 1] != pat[j - 1]: ''' the character preceding the occurrence of t in pattern P is different than the mismatching character in P, we stop skipping the occurrences and shift the pattern from i to j ''' if shift[j] == 0: shift[j] = j - i # Update the position of next border j = bpos[j] ''' p[i-1] matched with p[j-1], border is found. store the beginning position of border ''' i -= 1 j -= 1 bpos[i] = j # Preprocessing for case 2 def preprocess_case2(shift, bpos, pat, m): j = bpos[0] for i in range(m + 1): ''' set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 ''' if shift[i] == 0: shift[i] = j ''' suffix becomes shorter than bpos[0], use the position of next widest border as value of j ''' if i == j: j = bpos[j] '''Search for a pattern in given text using Boyer Moore algorithm with Good suffix rule ''' def search(text, pat): # s is shift of the pattern with respect to text s = 0 m = len(pat) n = len(text) bpos = [0] * (m + 1) # initialize all occurrence of shift to 0 shift = [0] * (m + 1) # do preprocessing preprocess_strong_suffix(shift, bpos, pat, m) preprocess_case2(shift, bpos, pat, m) while s <= n - m: j = m - 1 ''' Keep reducing index j of pattern while characters of pattern and text are matching at this shift s''' while j >= 0 and pat[j] == text[s + j]: j -= 1 ''' If the pattern is present at the current shift, then index j will become -1 after the above loop ''' if j < 0: print("pattern occurs at shift = %d" % s) s += shift[0] else: '''pat[i] != pat[s+j] so shift the pattern shift[j+1] times ''' s += shift[j + 1] # Driver Code if __name__ == "__main__": text = "ABAAAABAACD" pat = "ABA" search(text, pat) # This code is contributed by # sanjeev2552
C#
/* C# program for Boyer Moore Algorithm with Good Suffix heuristic to find pattern in given text string */ using System; class GFG { // preprocessing for strong good suffix rule static void preprocess_strong_suffix(int []shift, int []bpos, char []pat, int m) { // m is the length of pattern int i = m, j = m + 1; bpos[i] = j; while(i > 0) { /*if character at position i-1 is not equivalent to character at j-1, then continue searching to right of the pattern for border */ while(j <= m && pat[i - 1] != pat[j - 1]) { /* the character preceding the occurrence of t in pattern P is different than the mismatching character in P, we stop skipping the occurrences and shift the pattern from i to j */ if (shift[j] == 0) shift[j] = j - i; //Update the position of next border j = bpos[j]; } /* p[i-1] matched with p[j-1], border is found. store the beginning position of border */ i--; j--; bpos[i] = j; } } //Preprocessing for case 2 static void preprocess_case2(int []shift, int []bpos, char []pat, int m) { int i, j; j = bpos[0]; for(i = 0; i <= m; i++) { /* set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 */ if(shift[i] == 0) shift[i] = j; /* suffix becomes shorter than bpos[0], use the position of next widest border as value of j */ if (i == j) j = bpos[j]; } } /*Search for a pattern in given text using Boyer Moore algorithm with Good suffix rule */ static void search(char []text, char []pat) { // s is shift of the pattern // with respect to text int s = 0, j; int m = pat.Length; int n = text.Length; int []bpos = new int[m + 1]; int []shift = new int[m + 1]; // initialize all occurrence of shift to 0 for(int i = 0; i < m + 1; i++) shift[i] = 0; // do preprocessing preprocess_strong_suffix(shift, bpos, pat, m); preprocess_case2(shift, bpos, pat, m); while(s <= n - m) { j = m - 1; /* Keep reducing index j of pattern while characters of pattern and text are matching at this shift s*/ while(j >= 0 && pat[j] == text[s + j]) j--; /* If the pattern is present at the current shift, then index j will become -1 after the above loop */ if (j < 0) { Console.Write("pattern occurs at shift = {0}\n", s); s += shift[0]; } else /*pat[i] != pat[s+j] so shift the pattern shift[j+1] times */ s += shift[j + 1]; } } // Driver Code public static void Main(String[] args) { char []text = "ABAAAABAACD".ToCharArray(); char []pat = "ABA".ToCharArray(); search(text, pat); } } // This code is contributed by PrinciRaj1992
输出:pattern occurs at shift = 0 pattern occurs at shift = 5参考
- http://www.iti.fh-flensburg.de/lang/algorithmen/pattern/bmen.htm