在Python中使用链式实现散列
哈希是一种用于存储大量数据的数据结构,可以通过搜索、插入和删除等操作在O(1)时间内访问这些数据。散列的各种应用是:
- 数据库中的索引
- 密码学
- 编译器/解释器中的符号表
- 字典、缓存等
散列、散列表和散列函数的概念
散列是一种重要的数据结构,旨在使用称为散列函数的特殊函数,该函数用于将给定值与特定键映射以更快地访问元素。映射的效率取决于所使用的散列函数的效率。
例子:
h(large_value) = large_value % m这里, h()是所需的散列函数,'m' 是散列表的大小。对于较大的值,散列函数在给定范围内产生值。
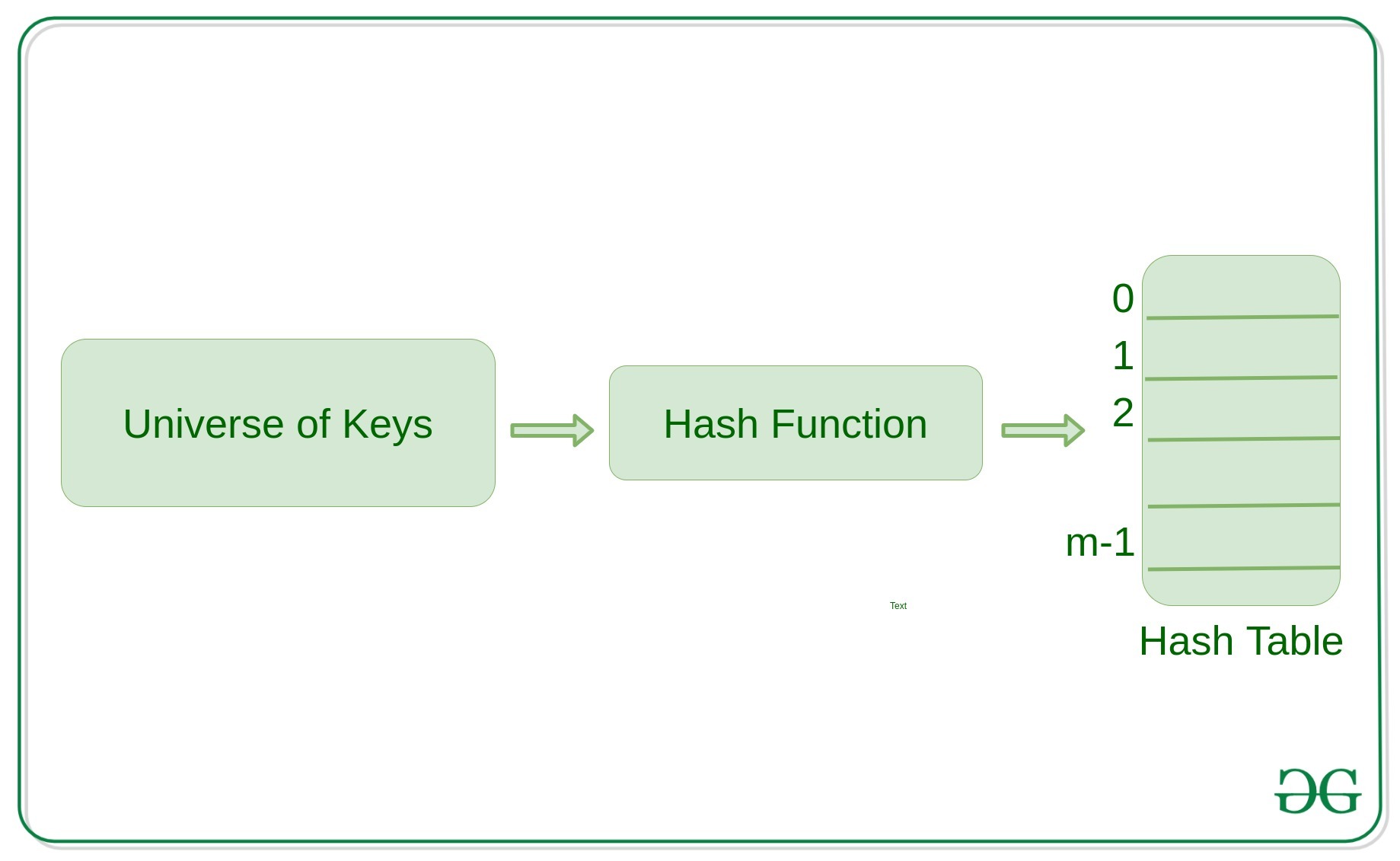
哈希函数是如何工作的?
- 它应该始终将大键映射到小键。
- 它应该始终生成 0 到 m-1 之间的值,其中 m 是哈希表的大小。
- 它应该将大键均匀地分配到哈希表槽中。
碰撞处理
如果我们事先知道密钥,那么我们就可以拥有完美的散列。在完美哈希中,我们没有任何冲突。但是,如果我们不知道密钥,那么我们可以使用以下方法来避免冲突:
- 链接
- 开放寻址(线性探测、二次探测、双散列)
链接
在散列时,散列函数可能会导致两个或多个键映射到相同值的冲突。链式哈希避免了冲突。这个想法是使哈希表的每个单元格都指向具有相同哈希函数值的记录的链接列表。
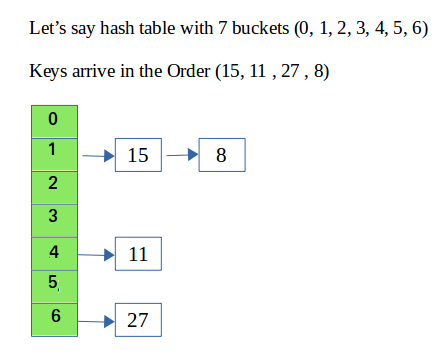
注意:在线性探测中,每当发生碰撞时,我们都会探测到下一个空槽。在二次探测中,每当发生碰撞时,我们都会在第 i 次迭代中探测第
i^2th个槽,并继续探测直到在哈希表中找到一个空槽。哈希的性能
散列的性能是基于每个键对于散列表的任何槽都同样可能被散列来评估的。
m = Length of Hash Table n = Total keys to be inserted in the hash table Load factor lf = n/m Expected time to search = O(1 +lf ) Expected time to insert/delete = O(1 + lf) The time complexity of search insert and delete is O(1) if lf is O(1)哈希的Python实现
# Function to display hashtable def display_hash(hashTable): for i in range(len(hashTable)): print(i, end = " ") for j in hashTable[i]: print("-->", end = " ") print(j, end = " ") print() # Creating Hashtable as # a nested list. HashTable = [[] for _ in range(10)] # Hashing Function to return # key for every value. def Hashing(keyvalue): return keyvalue % len(HashTable) # Insert Function to add # values to the hash table def insert(Hashtable, keyvalue, value): hash_key = Hashing(keyvalue) Hashtable[hash_key].append(value) # Driver Code insert(HashTable, 10, 'Allahabad') insert(HashTable, 25, 'Mumbai') insert(HashTable, 20, 'Mathura') insert(HashTable, 9, 'Delhi') insert(HashTable, 21, 'Punjab') insert(HashTable, 21, 'Noida') display_hash (HashTable)输出:
0 --> Allahabad --> Mathura 1 --> Punjab --> Noida 2 3 4 5 --> Mumbai 6 7 8 9 --> Delhi