- 机器学习中的回归分析(1)
- 机器学习中的回归分析
- 机器学习中的线性回归(1)
- 机器学习中的线性回归
- 机器学习中的回归与分类
- 机器学习-多项式回归
- 机器学习-多项式回归(1)
- 机器学习中的 P 值(1)
- C++中的机器学习
- 机器学习中的 P 值
- C++中的机器学习(1)
- 机器学习 (1)
- 机器学习中的简单线性回归(1)
- 机器学习中的简单线性回归
- 逻辑回归 - R 编程语言(1)
- 机器学习 python (1)
- R 编程中的逻辑回归
- R 编程中的逻辑回归(1)
- 逻辑回归 - R 编程语言代码示例
- Python的逻辑回归-测试(1)
- Python的逻辑回归-测试
- python中的逻辑回归算法(1)
- 机器学习 python 代码示例
- Python教程中的逻辑回归
- Python教程中的逻辑回归(1)
- Python的逻辑回归-简介
- Python的逻辑回归-简介(1)
- 机器学习-多元线性回归(1)
- 机器学习-多元线性回归
📅 最后修改于: 2020-09-27 03:21:34 🧑 作者: Mango
机器学习中的逻辑回归
- 逻辑回归是最流行的机器学习算法之一,属于监督学习技术。它用于使用给定的一组独立变量来预测分类因变量。
- Logistic回归预测分类因变量的输出。因此,结果必须是分类或离散值。它可以是Yes或No,0或1,true或False等,但是不是给出确切的值0和1, 而是给出了介于0和1之间的概率值 。
- Logistic回归与线性回归非常相似,不同之处在于如何使用它们。线性回归用于解决回归问题,而逻辑回归用于解决分类问题 。
- 在逻辑回归中,我们拟合了“ S”形逻辑函数 ,而不是拟合回归线,该函数预测两个最大值(0或1)。
- 逻辑函数的曲线表示某些可能性,例如细胞的重量,例如细胞是否癌变,小鼠是否肥胖等。
- Logistic回归是一种重要的机器学习算法,因为它具有使用连续和离散数据集提供概率和对新数据进行分类的能力。
- Logistic回归可用于使用不同类型的数据对观察结果进行分类,并可轻松确定用于分类的最有效变量。下图显示了逻辑函数:
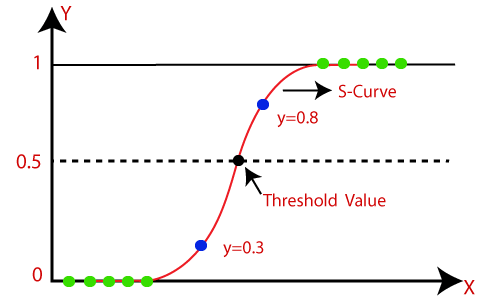
注意:Logistic回归使用预测建模的概念作为回归;因此,它称为逻辑回归,但用于对样本进行分类。因此,它属于分类算法。
逻辑函数(S型函数):
- S形函数是用于将预测值映射到概率的数学函数 。
- 它将任何实际值映射到0到1范围内的另一个值。
- 逻辑回归的值必须在0到1之间,并且不能超出此限制,因此它会形成类似于“ S”形式的曲线。 S型曲线称为Sigmoid 函数或logistic 函数。
- 在逻辑回归中,我们使用阈值的概念,该概念定义了0或1的概率。例如,高于阈值的值趋于1,而低于阈值的值趋于0。
Logistic回归的假设:
- 因变量本质上必须是分类的。
- 自变量不应具有多重共线性。
Logistic回归方程:
逻辑回归方程可从线性回归方程获得。获得Logistic回归方程的数学步骤如下:
- 我们知道直线方程可以写成:
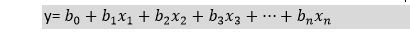
- 在Logistic回归中y只能在0到1之间,因此,让我们将上面的方程除以(1-y):
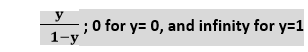
- 但是我们需要在-[infinity]到+ [infinity]之间,然后取等式的对数,它将变成:
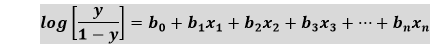
上面的方程式是Logistic回归的最终方程式。
Logistic回归类型:
根据类别,逻辑回归可以分为三种类型:
- 二项式:在二项Logistic回归中,只能有两种可能的因变量类型,例如0或1,Pass或Fail等。
- 多项式:在多项Logistic回归中,可以有3种或更多可能的因变量无序类型,例如“ cat”,“ dogs”或“ sheep”
- 序数:在序数Logistic回归中,可以有3种或更多种因变量的有序类型,例如“低”,“中”或“高”。
Logistic回归的Python实现(二项式)
要了解Python中Logistic回归的实现,我们将使用以下示例:
示例:提供了一个数据集,其中包含从社交网站获得的各种用户的信息。有一家汽车制造公司最近推出了新的SUV汽车。因此,该公司希望从数据集中检查有多少用户想要购买汽车。
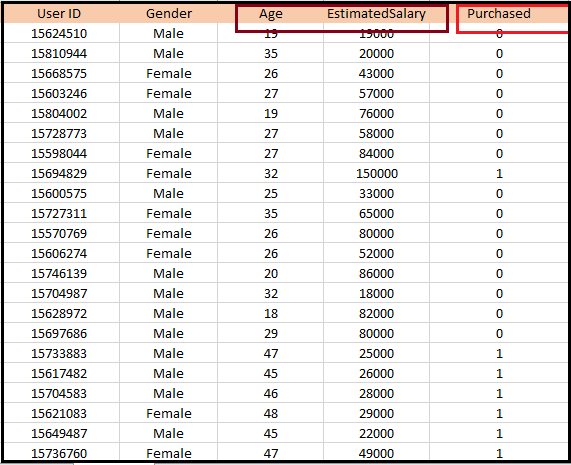
对于这个问题,我们将使用Logistic回归算法构建机器学习模型。数据集如下图所示。在这个问题中,我们将通过使用年龄和薪水(因变量)来预测购买的变量(因变量)。
Logistic回归中的步骤:要使用Python实现Logistic回归,我们将使用与前面的回归主题相同的步骤。步骤如下:
- 数据预处理步骤
- 将Logistic回归拟合到训练集
- 预测测试结果
- 测试结果的准确性(创建混淆矩阵)
- 可视化测试集结果。
1.数据预处理步骤:在此步骤中,我们将预处理/准备数据,以便我们可以在代码中有效地使用它。它将与我们在“数据预处理”主题中所做的相同。下面给出了此代码:
#Data Pre-procesing Step
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('user_data.csv')
通过执行以上代码行,我们将获得数据集作为输出。考虑给定的图像:
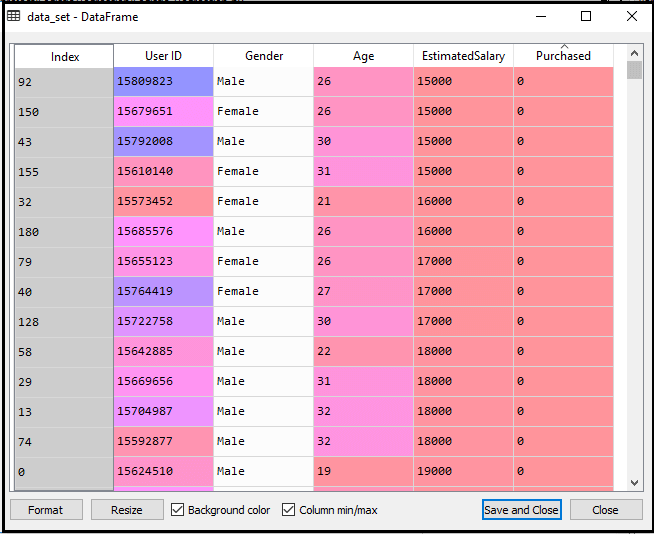
现在,我们将从给定的数据集中提取因变量和自变量。下面是它的代码:
#Extracting Independent and dependent Variable
x= data_set.iloc[:, [2,3]].values
y= data_set.iloc[:, 4].values
在上面的代码中,我们对x取[2,3],因为我们的自变量是年龄和薪水,它们在索引2、3处。对于y变量,我们取4是因为我们的因变量在索引4处。输出将是:
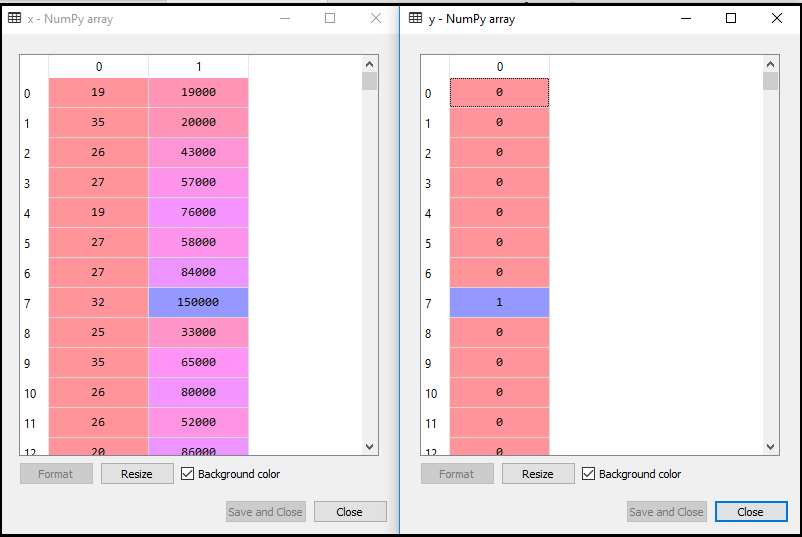
现在,我们将数据集分为训练集和测试集。下面是它的代码:
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.25, random_state=0)
输出如下:
对于测试集:
对于训练集:
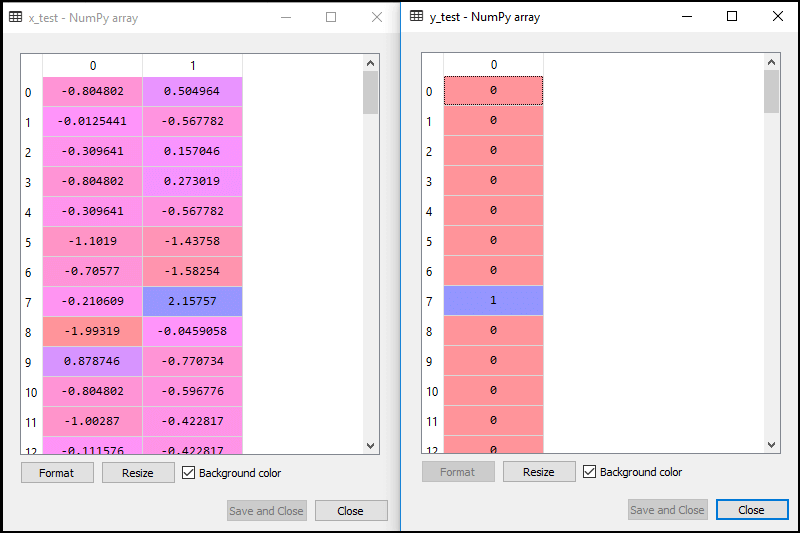
在逻辑回归中,我们将进行特征缩放,因为我们想要准确的预测结果。在这里,我们将仅缩放自变量,因为因变量只有0和1的值。下面是它的代码:
#feature Scaling
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
缩放后的输出如下:
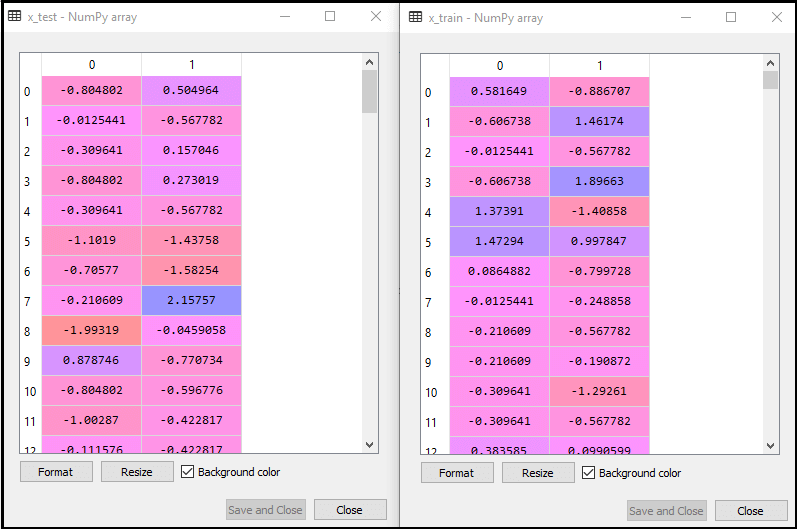
2.使逻辑回归适合训练集:
我们已经准备好了数据集,现在我们将使用训练集来训练数据集。为了提供训练或使模型适合训练集,我们将导入sklearn库的LogisticRegression类。
导入类后,我们将创建一个分类器对象,并使用它来使模型适合逻辑回归。下面是它的代码:
#Fitting Logistic Regression to the training set
from sklearn.linear_model import LogisticRegression
classifier= LogisticRegression(random_state=0)
classifier.fit(x_train, y_train)
输出:通过执行以上代码,我们将获得以下输出:
出[5]:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=0, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
因此,我们的模型非常适合训练集。
3.预测测试结果
我们的模型在训练集上训练有素,因此我们现在将使用测试集数据来预测结果。下面是它的代码:
#Predicting the test set result
y_pred= classifier.predict(x_test)
在上面的代码中,我们创建了y_pred向量来预测测试集结果。
输出:通过执行上述代码,将在变量资源管理器选项下创建一个新的向量(y_pred)。可以看作是:
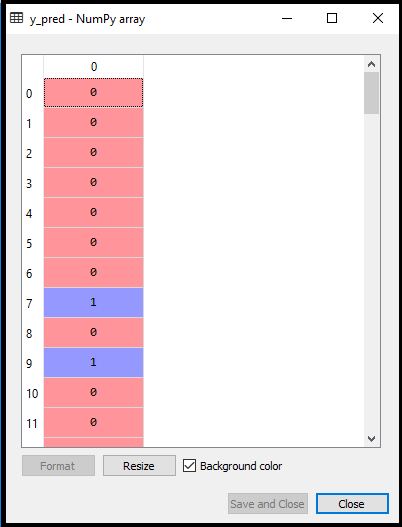
上面的输出图像显示了想要购买或不购买汽车的相应预测用户。
4.测试结果的准确性
现在,我们将在此处创建混淆矩阵以检查分类的准确性。要创建它,我们需要导入sklearn库的confusion_matrix 函数 。导入函数,我们将使用新变量cm调用它。该函数有两个参数,主要是y_true(实际值)和y_pred(分类器返回的目标值)。下面是它的代码:
#Creating the Confusion matrix
from sklearn.metrics import confusion_matrix
cm= confusion_matrix()
输出:
通过执行以上代码,将创建一个新的混淆矩阵。考虑下图:
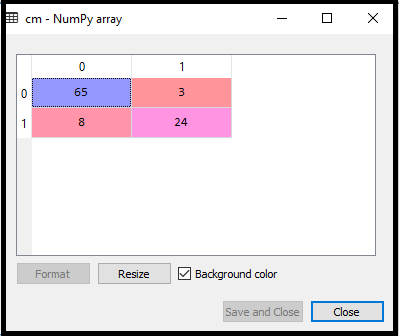
我们可以通过解释混淆矩阵来找到预测结果的准确性。通过以上输出,我们可以解释为65 + 24 = 89(正确的输出)和8 + 3 = 11(错误的输出)。
5.可视化训练集结果
最后,我们将可视化训练集结果。为了可视化结果,我们将使用matplotlib库的ListedColormap类。下面是它的代码:
#Visualizing the training set result
from matplotlib.colors import ListedColormap
x_set, y_set = x_train, y_train
x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
alpha = 0.75, cmap = ListedColormap(('purple','green' )))
mtp.xlim(x1.min(), x1.max())
mtp.ylim(x2.min(), x2.max())
for i, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Logistic Regression (Training set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
在上面的代码中,我们导入了Matplotlib库的ListedColormap类,以创建用于可视化结果的颜色图。我们创建了两个新变量x_set和y_set来替换x_train和y_train。之后,我们使用nm.meshgrid命令创建一个矩形网格,其范围为-1(最小)到1(最大)。我们拍摄的像素点的分辨率为0.01。
为了创建填充轮廓,我们使用了mtp.contourf命令,它将创建提供颜色(紫色和绿色)的区域。在此函数,我们传递了classifier.predict来显示分类器预测的预测数据点。
输出:通过执行以上代码,我们将获得以下输出:
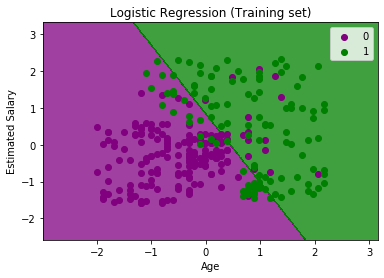
该图可以在以下几点进行说明:
- 在上图中,我们可以看到绿色区域中有一些绿色点 ,紫色区域中有一些紫色点 。
- 所有这些数据点都是训练集中的观察点,显示了购买变量的结果。
- 该图是通过使用两个独立变量制作的,即x轴上的Age和y轴上的估算薪水 。
- 所购买的紫色点观测值 (因变量)可能为0,即,未购买SUV汽车的用户。
- 所购买的绿点观察值 (因变量)可能为1表示购买SUV汽车的用户。
- 我们还可以从图中估算出,低薪的年轻用户没有购买汽车,而高薪的老年人则购买了汽车。
- 但是绿色区域中有一些紫色点(买车),紫色区域中有一些绿色点(不买车)。因此,可以说估算工资较高的年轻用户购买了汽车,而估算工资较低的老用户则没有购买汽车。
分类器的目标:
我们已经成功地可视化了Logistic回归的训练集结果,并且我们的分类目标是对购买SUV汽车和未购买汽车的用户进行划分。因此,从输出图中,我们可以清楚地看到带有观察点的两个区域(紫色和绿色)。紫色区域适用于未购买汽车的用户,绿色区域适用于那些购买汽车的用户。
线性分类器:
从图中可以看出,分类器本质上是直线或线性,因为我们已将线性模型用于Logistic回归。在其他主题中,我们将学习非线性分类器。
可视化测试集结果:
我们使用训练数据集对模型进行了很好的训练。现在,我们将可视化结果以用于新观察(测试集)。测试集的代码将与上面相同,除了这里我们将使用x_test和y_test代替x_train和y_train。下面是它的代码:
#Visulaizing the test set result
from matplotlib.colors import ListedColormap
x_set, y_set = x_test, y_test
x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
alpha = 0.75, cmap = ListedColormap(('purple','green' )))
mtp.xlim(x1.min(), x1.max())
mtp.ylim(x2.min(), x2.max())
for i, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Logistic Regression (Test set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
输出:
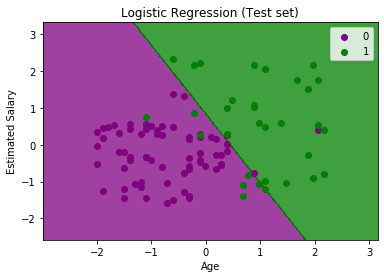
上图显示了测试设置结果。可以看到,该图分为两个区域(紫色和绿色)。绿色观测值位于绿色区域,而紫色观测值位于紫色区域。因此,可以说这是一个很好的预测和模型。一些绿色和紫色数据点位于不同的区域,可以忽略不计,因为我们已经使用混淆矩阵(11错误输出)计算了此误差。
因此,我们的模型非常好,可以为该分类问题做出新的预测。