Pandas DataFrame 的排行
要对 Pandas DataFrame 的行进行排名,我们可以使用DataFrame.rank()方法,该方法返回传递的系列的每个相应索引的排名。排序后根据位置返回排名。
示例 #1:
在这里,我们将创建电影的 DataFrame 并根据它们的收视率对它们进行排名。
# import the required packages
import pandas as pd
# Define the dictionary for converting to dataframe
movies = {'Name': ['The Godfather', 'Bird Box', 'Fight Club'],
'Year': ['1972', '2018', '1999'],
'Rating': ['9.2', '6.8', '8.8']}
df = pd.DataFrame(movies)
print(df)
输出: 
# Create a column Rating_Rank which contains
# the rank of each movie based on rating
df['Rating_Rank'] = df['Rating'].rank(ascending = 1)
# Set the index to newly created column, Rating_Rank
df = df.set_index('Rating_Rank')
print(df)
输出: 
# Sort the dataFrame based on the index
df = df.sort_index()
print(df)
输出:  示例 #2
示例 #2
让我们以 4 名学生的分数为例。我们将根据学生的最高分数对他们进行排名。
# Create a dictionary with student details
student_details = {'Name':['Raj', 'Raj', 'Raj', 'Aravind', 'Aravind', 'Aravind',
'John', 'John', 'John', 'Arjun', 'Arjun', 'Arjun'],
'Subject':['Maths', 'Physics', 'Chemistry', 'Maths', 'Physics',
'Chemistry', 'Maths', 'Physics', 'Chemistry', 'Maths',
'Physics', 'Chemistry'],
'Marks':[80, 90, 75, 60, 40, 60, 80, 55, 100, 90, 75, 70]
}
# Convert dictionary to a DataFrame
df = pd.DataFrame(student_details)
print(df)
输出: 
# Create a new column with Marks
# ranked in descending order
df['Mark_Rank'] = df['Marks'].rank(ascending = 0)
# Set index to newly created column
df = df.set_index('Mark_Rank')
print(df)
输出: 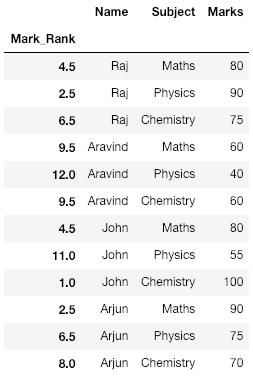
# Sort the DataFrame based on the index
df = df.sort_index()
print(df)
输出: 
解释:
请注意,我们让 Raj 和 Arjun 分别获得 90 分,因此他们的排名为 2.5(第二和第三排名的平均值,即他们共享的两个排名)。这也可以从表中的其他标记中看到。