从 Pandas DataFrame 中删除行列表
让我们看看如何在 Pandas DataFrame 中删除行列表。我们可以使用drop()函数来做到这一点。我们还将传递 inplace = True ,因为它确保我们在实例中所做的更改存储在该实例中而不进行任何分配
这里是如何从表中删除行列表的代码实现:
示例 1:
Python3
# import the module
import pandas as pd
# creating a DataFrame
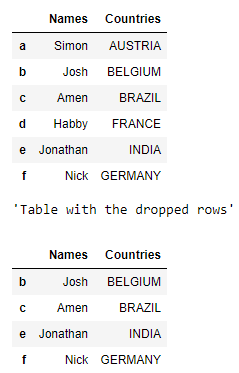
dictionary = {'Names':['Simon', 'Josh', 'Amen', 'Habby',
'Jonathan', 'Nick'],
'Countries':['AUSTRIA', 'BELGIUM', 'BRAZIL',
'FRANCE', 'INDIA', 'GERMANY']}
table = pd.DataFrame(dictionary, columns = ['Names', 'Countries'],
index = ['a', 'b', 'c', 'd', 'e', 'f'])
display(table)
# gives the table with the dropped rows
display("Table with the dropped rows")
display(table.drop(['a', 'd']))
# gives the table with the dropped rows
# shows the reduced table for the given command only
display("Reduced table for the given command only")
display(table.drop(table.index[[1, 3]]))
# it gives none but it makes changes in the table
display(table.drop(['a', 'd'], inplace = True))
# final table
print("Final Table")
display(table)
# table after removing range of rows from 0 to 2(not included)
table.drop(table.index[:2], inplace = True)
display(table)Python3
# creating a DataFrame
data = {'Name' : ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age' : [27, 24, 22, 32],
'Address' : ['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification' : ['Msc', 'MA', 'MCA', 'Phd']}
table = pd.DataFrame(data)
# original DataFrame
display("Original DataFrame")
display(table)
# drop 2nd row
display("Dropped 2nd row")
display(table.drop(1))输出 :

示例 2:
Python3
# creating a DataFrame
data = {'Name' : ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age' : [27, 24, 22, 32],
'Address' : ['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification' : ['Msc', 'MA', 'MCA', 'Phd']}
table = pd.DataFrame(data)
# original DataFrame
display("Original DataFrame")
display(table)
# drop 2nd row
display("Dropped 2nd row")
display(table.drop(1))
输出 :
