Calinski-Harabasz 指数 – 集群有效性指数 |设置 3
先决条件:集群有效性指数
聚类验证被认为是聚类算法成功的重要因素之一。如何有效、高效地评估聚类算法的聚类结果是问题的关键。通常,集群有效性度量分为 3 类(内部集群验证、外部集群验证和相对集群验证)。
在本文中,我们关注内部集群验证索引,即Calinski-Harabasz 索引。
Calinski-Harabasz 指数:
Calinski-Harabasz (CH) 指数(由 Calinski 和 Harabasz 于 1974 年引入)可用于在不知道真实标签的情况下评估模型,其中使用数据固有的数量和特征来验证聚类的效果。数据集。 CH 指数(也称为方差比标准)是衡量一个对象与其自己的集群(内聚力)与其他集群(分离)相比的相似程度。这里的内聚力是基于集群中的数据点到其集群质心的距离来估计的,而分离度是基于集群质心与全局质心的距离。 CH 指数的形式为(a . Separation)/(b . Cohesion) ,其中 a 和 b 是权重。
Calinski-Harabasz 指数的计算:
数据集 D =[ d 1 , d 2 , d 3 , ... d N ] 上 K 个簇的 CH 索引定义为,
![$\left.C H=\left[\frac{\sum_{k=1}^{K} n_{k}\left\|c_{k}-c\right\|^{2}}{K-1}\right] / \frac{\sum_{k=1}^{K} \sum_{i=1}^{n_{k}}\left\|d_{i}-c_{k}\right\|^{2}}{N-K}\right]$](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Calinski-Harabasz_Index_%E2%80%93_Cluster_Validity_indices_%7C_Set_3_0.jpg "由 QuickLaTeX.com 渲染")
其中, n k 和c k是没有。分别为第k个簇的点和质心,c是全局质心,N是总数。的数据点。
CH 指数值较高意味着簇密集且分离良好,尽管没有“可接受的”截止值。我们需要选择在 CH 指数的线图上给出一个峰值或至少一个突然弯头的解决方案。另一方面,如果线条是平滑的(水平或上升或下降),那么就没有理由偏爱一个解决方案而不是其他解决方案。
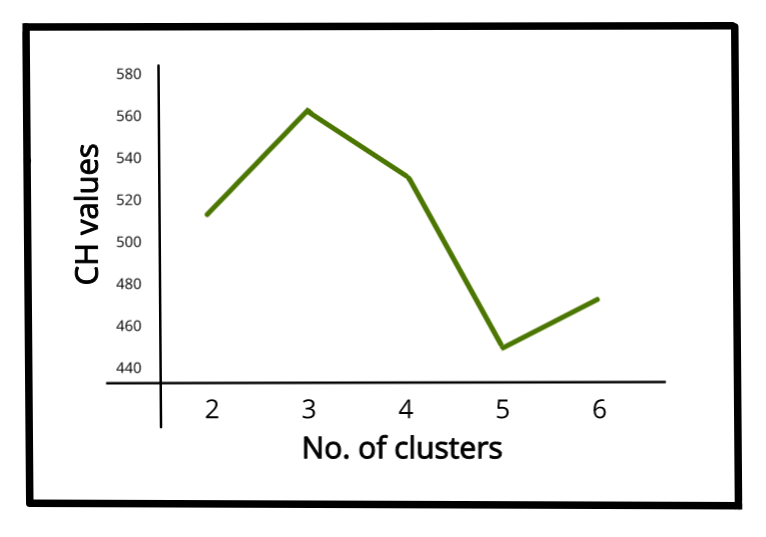
IRIS 数据集的 CH 值与簇数的线图
下面是使用 sklearn 库对上述 CH 索引的Python实现:
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics import pairwise_distances
import numpy as np
# loading the dataset
X, y = datasets.load_iris(return_X_y=True)
# K-Means
kmeans = KMeans(n_clusters=3, random_state=1).fit(X)
# we store the cluster labels
labels = kmeans.labels_
print(metrics.calinski_harabasz_score(X, labels))
输出:
561.62参考资料: https ://scikit-learn.org/stable/modules/clustering.html#calinski-harabasz-index