Julia中DataFrames的拆分应用组合策略
Julia 是一种具有高级语法的高性能动态编程语言。它也可能被认为是Python语言的一种新的、更简单的变体。可以使用 Julia 以各种方式创建、操作和可视化数据框,以用于数据科学和机器学习。
分应用组合策略
对于数据分析中的一些任务,需要拆分数据帧以应用多个函数,并组合最终结果。我们必须访问必要的包,并且可以使用by或聚合函数来实现此策略。
首先,我们必须添加必要的包以使用 DataFrame、CSV 文件和所需的函数。
Julia
# Adding Packages for using DataFrames,
# CSV files, and statistical functions
using Pkg
Pkg.add("DataFrames")
Pkg.add("CSV")
Pkg.add("Statistics")Julia
# Enabling use of necessary packages
using DataFrames, CSV, Statistics
# Reading a CSV file into a DataFrame
ds = CSV.read("C:\\Users\\metal\\vgsales.csv");Julia
# Displaying the first few rows of the DataFrame
head(ds)Julia
# Displaying the last few rows of the DataFrame
tail(ds)Julia
# Calculating the number of rows and columns
# for each of the publishers in the DataFrame
by(ds, :Publisher, size)Julia
# Calculating the mean of the global sales of each Publisher
by(ds, :Publisher, df -> mean(df.Global_Sales))Julia
# Calculating number of entries for each publisher
by(ds, :Publisher, df -> DataFrame(N = size(df, 1)))Julia
# Calculating the mean and variance
# of global sales of each publisher
by(ds, :Publisher) do df
DataFrame(Mean = mean(df.Global_Sales), Variance = var(df.Global_Sales))
endJulia
# Calculating the number of entries
# in each column for each publisher
aggregate(ds, :Publisher, length)Julia
# Creating a subset of entries for each publisher
for subdf in groupby(ds, :Publisher)
println(size(subdf, 1))
end现在我们将 CSV 文件读入 DataFrame。这里使用了位于本地内存中的视频游戏销售信息数据集。
朱莉娅
# Enabling use of necessary packages
using DataFrames, CSV, Statistics
# Reading a CSV file into a DataFrame
ds = CSV.read("C:\\Users\\metal\\vgsales.csv");
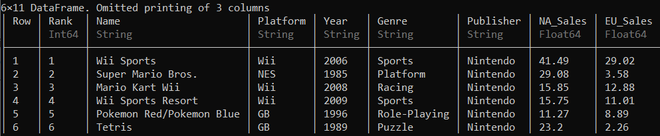
该数据帧现在使用预定义函数head()和tail() 分为两部分。
朱莉娅
# Displaying the first few rows of the DataFrame
head(ds)
朱莉娅
# Displaying the last few rows of the DataFrame
tail(ds)

现在,我们使用by函数,可以在函数中传递的三个参数是:
- 数据框
- 用于拆分 DataFrame 的列
- 拆分 DataFrame 后要应用的函数
现在 DataFrame 被拆分为一列,我们将对其执行各种功能。
朱莉娅
# Calculating the number of rows and columns
# for each of the publishers in the DataFrame
by(ds, :Publisher, size)

朱莉娅
# Calculating the mean of the global sales of each Publisher
by(ds, :Publisher, df -> mean(df.Global_Sales))

朱莉娅
# Calculating number of entries for each publisher
by(ds, :Publisher, df -> DataFrame(N = size(df, 1)))

我们还可以将函数和表达式放在do块中,如下所示:
朱莉娅
# Calculating the mean and variance
# of global sales of each publisher
by(ds, :Publisher) do df
DataFrame(Mean = mean(df.Global_Sales), Variance = var(df.Global_Sales))
end

如前所述, aggregate()函数也可用于实现策略,该策略接受与by()函数相同的三个参数。在使用特定函数传递参数后,它会创建新列作为结果,使用语法“column.name_function”命名。
朱莉娅
# Calculating the number of entries
# in each column for each publisher
aggregate(ds, :Publisher, length)

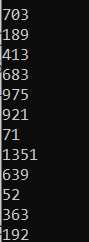
我们还可以通过使用groupby()函数拆分数据集来创建子集
朱莉娅
# Creating a subset of entries for each publisher
for subdf in groupby(ds, :Publisher)
println(size(subdf, 1))
end
各种其他函数可以作为by()和aggregate()函数的参数传递,以实现拆分-应用-组合策略,以实现所需的结果和见解。