潜在语义分析
潜在语义分析是一种自然语言处理方法,它使用统计方法来识别文档中单词之间的关联。 LSA 处理以下类型的问题:
示例:手机、电话、手机、电话都相似,但如果我们提出“手机一直在响”这样的查询,则只检索包含“手机”的文档,而包含手机、电话、电话的文档未检索。
LSA 的假设:
- 在同一上下文中使用的词彼此相似。
- 由于所选词的歧义,数据的隐藏语义结构不清楚。
奇异值分解:
奇异值分解是一种统计方法,用于查找散布在整个文档中的单词的潜在(隐藏)语义结构。
让
C = collection of documents.
d = number of documents.
n = number of unique words in the whole collection.
M = d X n SVD将M矩阵即word to document矩阵分解为三个矩阵如下
M = U∑VT
在哪里
U = distribution of words across the different contexts
∑ = diagonal matrix of the association among the contexts
VT = distribution of contexts across the different documents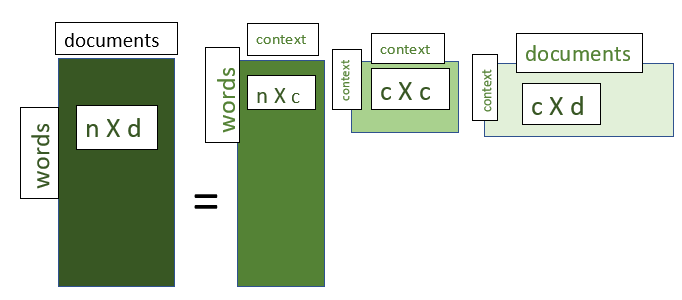
nxd 矩阵的 SVD
SVD 的一个非常重要的特性是它允许我们截断一些我们不一定需要的上下文。 ∑ 矩阵为我们提供了从高到低代表上下文重要性的对角线值。通过使用这些值,我们可以降低维度,因此这也可以用作降维技术。
如果我们选择 ∑ a 矩阵中的 k 个最大对角线值,我们得到
M k = U k ∑ k V T K
在哪里
Mk = approximated matrix of M
Uk, ∑k, VTk are the matrices containing only the k contexts from U, ∑, VT respectively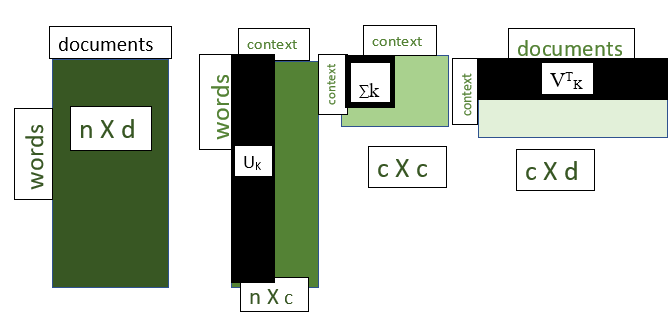
选择 k 值后截断的 SVD