- r中的层次聚类图 (1)
- 机器学习中的聚类
- 机器学习中的聚类
- r中的层次聚类图 - 无论代码示例
- R 编程中的层次聚类(1)
- R 编程中的层次聚类
- 数据挖掘中的层次聚类(1)
- 数据挖掘中的层次聚类
- 层次聚类凝聚 - Python (1)
- 层次聚类凝聚 - Python 代码示例
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类
- 机器学习中的 DBSCAN 聚类 |基于密度的聚类(1)
- 机器学习中的 P 值(1)
- 机器学习中的 P 值
- 机器学习 (1)
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习之K-means聚类算法(1)
- 机器学习之K-means聚类算法
- 毫升 |层次聚类(凝聚和分裂聚类)(1)
- 毫升 |层次聚类(凝聚和分裂聚类)
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 机器学习-什么是P值(1)
- 在机器学习中什么是“i” (1)
- 什么是机器学习?
- 机器学习-什么是P值
- 什么是机器学习?(1)
📅 最后修改于: 2020-09-29 01:27:03 🧑 作者: Mango
机器学习中的层次聚类
分层聚类是另一种无监督的机器学习算法,用于将未标记的数据集分组为一个聚类,也称为分层聚类分析或HCA。
在该算法中,我们以树的形式开发了簇的层次结构,这种树形结构被称为树状图。
有时,K均值聚类和分层聚类的结果可能看起来很相似,但是它们的工作方式却有所不同。由于不需要像我们在K-Means算法中那样预先确定簇的数量。
层次聚类技术有两种方法:
- 集聚:集聚是一种自下而上的方法,该算法从将所有数据点作为单个聚类并将其合并到剩下一个聚类开始。
- 分裂算法:分裂算法与凝聚算法相反,因为它是一种自顶向下的方法。
为什么要分层聚类?
由于我们已经有了其他聚类算法,例如K-Means聚类,那么为什么我们需要分层聚类?因此,正如我们在K均值聚类中看到的那样,该算法存在一些挑战,即预定数目的聚类,并且它总是尝试创建相同大小的聚类。为了解决这两个挑战,我们可以选择分层聚类算法,因为在这种算法中,我们不需要了解预定义的聚类数量。
在本主题中,我们将讨论聚集层次聚类算法。
聚集层次聚类
聚集层次聚类算法是HCA的流行示例。要将数据集分组,请遵循自下而上的方法。这意味着,该算法在开始时将每个数据集视为一个单独的群集,然后开始将最接近的群集对组合在一起。直到所有的聚类合并到包含所有数据集的单个聚类中为止。
群集的这种层次结构以树状图的形式表示。
聚集层次聚类如何工作?
可以使用以下步骤来解释AHC算法的工作原理:
- 步骤1:将每个数据点创建为单个群集。假设有N个数据点,因此簇数也将为N。
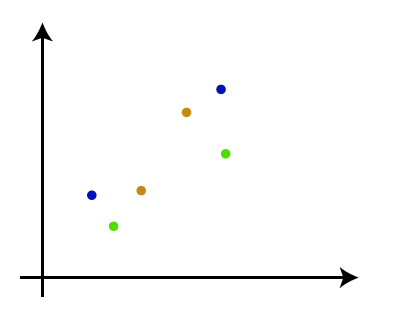
- 步骤2:获取两个最近的数据点或群集,然后将它们合并以形成一个群集。因此,现在将有N-1个集群。
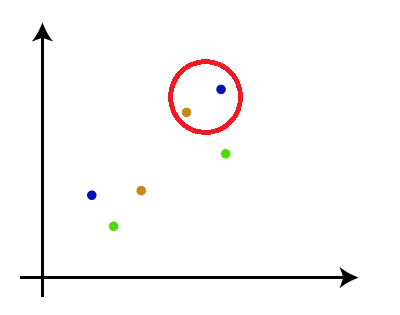
- 步骤3 :再次,选取两个最接近的群集并将它们合并在一起以形成一个群集。将有N-2个群集。
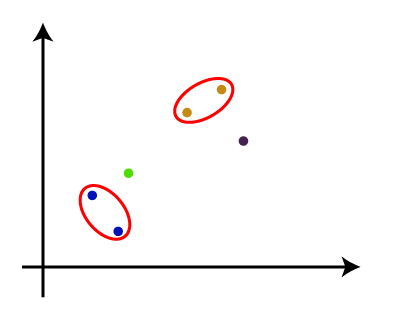
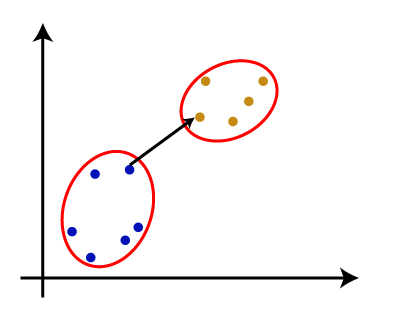
- 步骤4:重复步骤3,直到只剩下一个群集。因此,我们将获得以下集群。考虑以下图像:
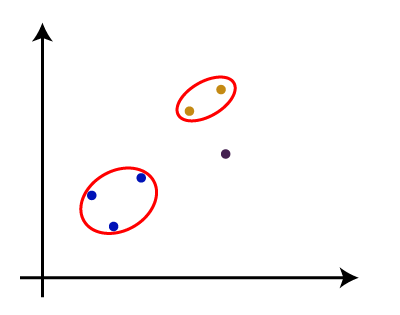
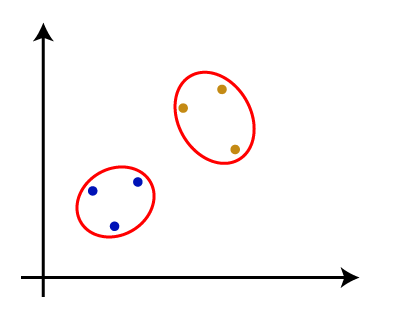
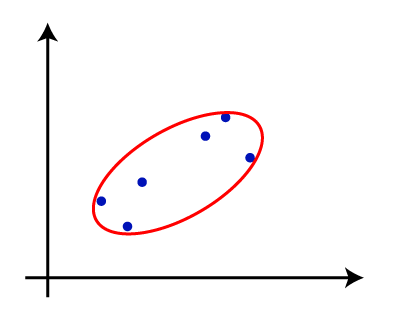
- 步骤5:将所有群集组合到一个大群集中之后,展开树状图以根据问题将群集划分。
注意:为了更好地理解层次聚类,建议先看一下k均值聚类
测量两个群集之间的距离
如我们所见,两个群集之间的最接近距离对于分层群集至关重要。有两种方法可以计算两个聚类之间的距离,这些方法决定了聚类的规则。这些措施称为链接方法。一些流行的链接方法如下:
- 单一链接:这是群集最近点之间的最短距离。考虑下图:
- 完全链接:这是两个不同群集的两点之间的最远距离。它是一种流行的链接方法,因为它比单链接形成更紧密的簇。
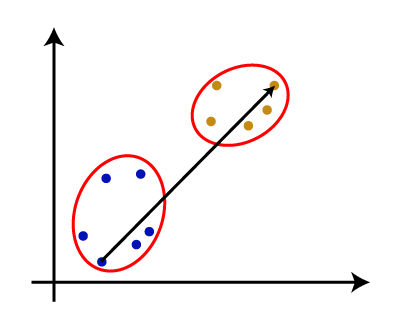
- 平均链接:这是一种链接方法,其中将每对数据集之间的距离相加,然后除以数据集总数,以计算两个聚类之间的平均距离。它也是最流行的链接方法之一。
- 质心链接:这是一种链接方法,其中计算群集的质心之间的距离。考虑下图:
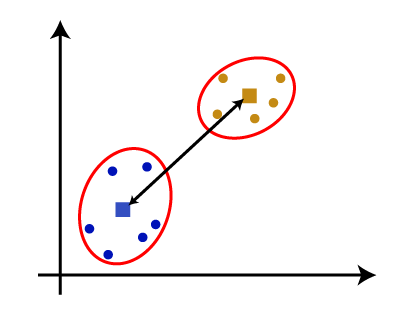
从上述方法中,我们可以根据问题类型或业务需求来应用其中任何一种。
树状图在层次聚类中的作用
树状图是树状结构,主要用于将每个步骤存储为HC算法执行的内存。在树状图中,Y轴显示数据点之间的欧几里得距离,x轴显示给定数据集的所有数据点。
可以使用下图说明树状图的工作方式:
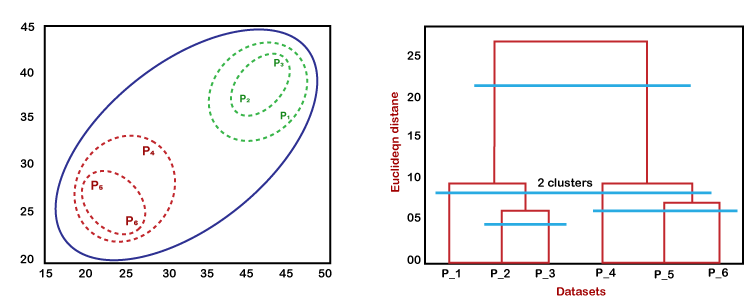
在上图中,左侧显示了如何在聚类聚类中创建聚类,右侧显示了相应的树状图。
- 如上所述,首先,数据点P2和P3组合在一起形成一个簇,相应地创建了树状图,该树状图将P2和P3连接为矩形。高是根据数据点之间的欧式距离确定的。
- 在下一步中,P5和P6组成一个簇,并创建相应的树状图。它比以前更高,因为P5和P6之间的欧几里得距离比P2和P3稍大。
- 同样,将创建两个新的树状图,它们在一个树状图中组合P1,P2和P3,在另一个树状图中组合P4,P5和P6。
- 最后,创建最终的树状图,将所有数据点组合在一起。
我们可以根据需要在任何级别上切割树状图树结构。
聚集层次聚类的Python实现
现在,我们将看到使用Python的凝聚式分层聚类算法的实际实现。为了实现这一点,我们将使用与K-means聚类的上一个主题相同的数据集问题,以便我们可以轻松比较这两个概念。
数据集包含访问过购物中心购物的顾客的信息。因此,购物中心所有者希望使用数据集信息找到其客户的某些模式或某些特定行为。
使用Python实现AHC的步骤:
实施步骤将与k-means聚类相同,除了一些更改(例如查找聚类数量的方法)外。步骤如下:
- 数据预处理
- 使用树状图查找最佳聚类数
- 训练分层聚类模型
- 可视化集群
数据预处理步骤:
在此步骤中,我们将导入模型的库和数据集。
- 导入库
# Importing the libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
上面的代码行用于导入库以执行特定任务,例如numpy用于数学运算,matplotlib用于绘制图形或散点图以及pandas用于导入数据集。
- 导入数据集
# Importing the dataset
dataset = pd.read_csv('Mall_Customers_data.csv')
如上所述,我们导入了Mall_Customers_data.csv相同的数据集,就像在k均值聚类中所做的那样。考虑以下输出:
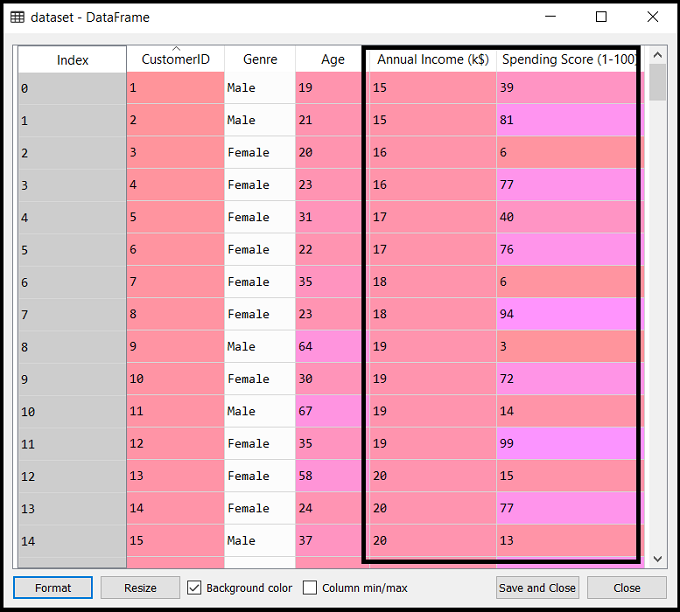
- 提取特征矩阵
在这里,我们将仅提取特征矩阵,因为我们没有关于因变量的更多信息。代码如下:
x = dataset.iloc[:, [3, 4]].values
在这里,我们仅提取了3列和4列,因为我们将使用2D图查看聚类。因此,我们将“年度收入和支出得分”作为特征矩阵。
步骤2:使用树状图找到最佳的簇数
现在,我们将使用树状图为我们的模型找到最佳的聚类数。为此,我们将使用scipy库,因为它提供了一个函数 ,该函数将直接返回代码的树状图。考虑下面的代码行:
#Finding the optimal number of clusters using the dendrogram
import scipy.cluster.hierarchy as shc
dendro = shc.dendrogram(shc.linkage(x, method="ward"))
mtp.title("Dendrogrma Plot")
mtp.ylabel("Euclidean Distances")
mtp.xlabel("Customers")
mtp.show()
在上面的代码行中,我们导入了scipy库的层次结构模块。该模块为我们提供了一种方法shc.denrogram(),该方法将linkage()作为参数。链接函数用于定义两个聚类之间的距离,因此在这里,我们通过了x(要素矩阵)和方法“ ward”,这是分层聚类中流行的链接方法。
其余代码行将描述树状图的标签。
输出:
通过执行以上代码行,我们将获得以下输出:
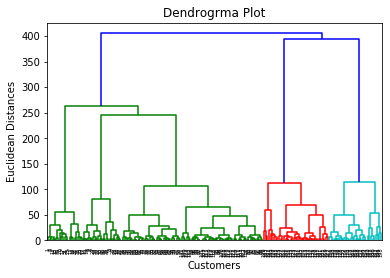
现在,使用该树状图,我们将为模型确定最佳聚类数。为此,我们将找到不切割任何水平条的最大垂直距离。考虑下图:
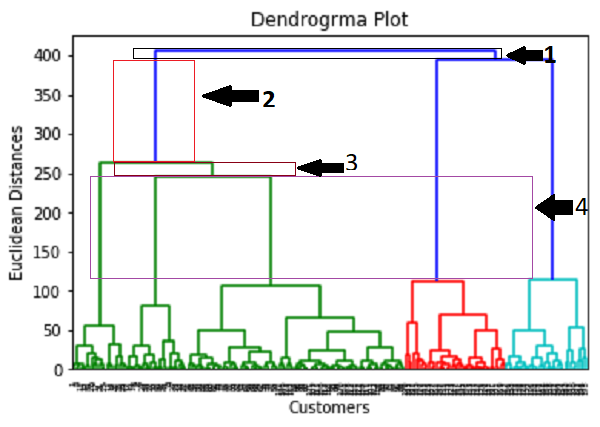
在上图中,我们显示了没有切割其水平线的垂直距离。正如我们可以看到的那样,第四个距离是最大的,因此根据此,聚类的数量将为5(此范围内的垂直线)。我们也可以采用第二个数字,因为它大约等于第四个距离,但是我们将考虑5个聚类,因为我们在K-means算法中计算出的聚类相同。
因此,群集的最佳数量将为5,我们将在下一步中使用该模型训练模型。
步骤3:训练分级聚类模型
由于我们知道所需的最佳集群数,因此我们现在可以训练模型。代码如下:
#training the hierarchical model on dataset
from sklearn.cluster import AgglomerativeClustering
hc= AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward')
y_pred= hc.fit_predict(x)
在上面的代码中,我们导入了scikit学习库的集群模块的AgglomerativeClustering类。
然后,我们创建了名为hc的此类的对象。 AgglomerativeClustering类采用以下参数:
- n_clusters = 5 :它定义了簇数,我们在这里取5,因为它是最优的簇数。
- finity =’euclidean’ :这是用于计算链接的度量。
- 链接=“病房” :它定义了链接标准,这里我们使用“病房”链接。该方法是我们已经用于创建树状图的流行链接方法。它减少了每个群集中的方差。
在最后一行,我们创建了因变量y_pred来拟合或训练模型。它不仅训练模型,而且还返回每个数据点所属的簇。
执行完上述代码后,如果我们在Sypder IDE中使用变量资源管理器选项,则可以检查y_pred变量。我们可以将原始数据集与y_pred变量进行比较。考虑下图:
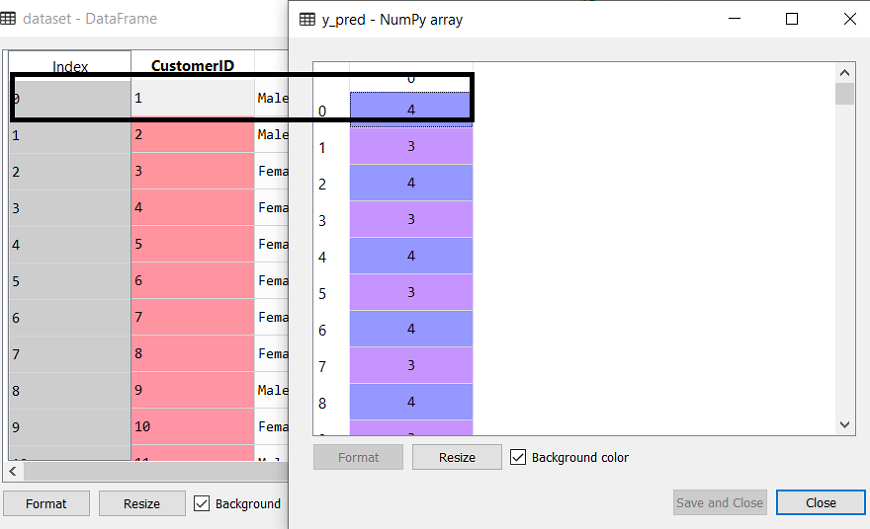
如上图所示,y_pred显示了clusters值,这意味着客户id 1属于第5个集群(索引从0开始,所以4表示第5个集群),客户id 2属于第4个集群,等等。
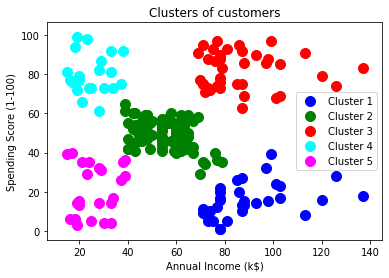
步骤4:可视化集群
由于我们已经成功地训练了模型,现在我们可以可视化对应于数据集的聚类。
在这里,我们将使用与k-means聚类相同的代码行,唯一的区别就是更改。在这里,我们不会绘制以k均值表示的质心,因为在这里,我们已使用树状图来确定最佳聚类数。代码如下:
#visulaizing the clusters
mtp.scatter(x[y_pred == 0, 0], x[y_pred == 0, 1], s = 100, c = 'blue', label = 'Cluster 1')
mtp.scatter(x[y_pred == 1, 0], x[y_pred == 1, 1], s = 100, c = 'green', label = 'Cluster 2')
mtp.scatter(x[y_pred== 2, 0], x[y_pred == 2, 1], s = 100, c = 'red', label = 'Cluster 3')
mtp.scatter(x[y_pred == 3, 0], x[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
mtp.scatter(x[y_pred == 4, 0], x[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
mtp.title('Clusters of customers')
mtp.xlabel('Annual Income (k$)')
mtp.ylabel('Spending Score (1-100)')
mtp.legend()
mtp.show()
输出:通过执行以上代码行,我们将获得以下输出: