R 编程中的层次聚类
R 编程语言中的层次聚类是一种无监督的非线性算法,其中创建的聚类具有层次结构(或预先确定的顺序)。例如,考虑一个多达三代的家庭。祖父和母亲的孩子成为他们孩子的父亲和母亲。因此,它们都被归为同一个家族,即它们形成一个层次结构。
R - 层次聚类
层次聚类有两种类型:
- 凝聚层次聚类:它从单个叶子开始并成功地将集群合并在一起。它是一种自下而上的方法。
- Divisive Hierarchical clustering:它从根开始并递归地拆分集群。这是一种自上而下的方法。
理论:
在层次聚类中,对象被分类成类似于树形结构的层次结构,用于解释层次聚类模型。算法如下:
- 将每个数据点放在一个单点簇中,形成N个簇。
- 取两个最近的数据点,使它们成为一个集群,形成N-1个集群。
- 取两个最近的簇,使它们成为一个簇,形成N-2 个簇。
- 重复步骤 3,直到只有一个集群。
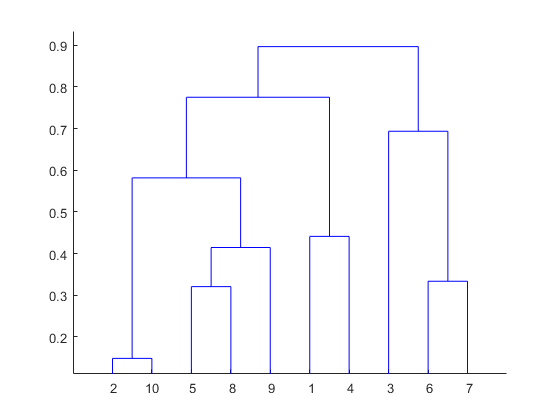
树状图是一种将距离转换为高度的聚类层次结构。它将n 个单元或对象聚集成更小的组,每个单元或对象具有p个特征。同一集群中的单元由一条水平线连接。底部的叶子代表单个单元。它提供了集群的可视化表示。
拇指规则:不切割任何水平线的最大垂直距离定义了最佳聚类数。
数据集
mtcars (motor trend car road test)包括油耗、性能、32辆汽车的10个汽车设计方面。它预装了 R 中的 dplyr 包。
R
# Installing the package
install.packages("dplyr")
# Loading package
library(dplyr)
# Summary of dataset in package
head(mtcars)R
# Finding distance matrix
distance_mat <- dist(mtcars, method = 'euclidean')
distance_mat
# Fitting Hierarchical clustering Model
# to training dataset
set.seed(240) # Setting seed
Hierar_cl <- hclust(distance_mat, method = "average")
Hierar_cl
# Plotting dendrogram
plot(Hierar_cl)
# Choosing no. of clusters
# Cutting tree by height
abline(h = 110, col = "green")
# Cutting tree by no. of clusters
fit <- cutree(Hierar_cl, k = 3 )
fit
table(fit)
rect.hclust(Hierar_cl, k = 3, border = "green")输出:

对数据集执行层次聚类
使用hclust()在数据集上使用层次聚类算法,该算法在安装 R 时预装在 stats 包中。
R
# Finding distance matrix
distance_mat <- dist(mtcars, method = 'euclidean')
distance_mat
# Fitting Hierarchical clustering Model
# to training dataset
set.seed(240) # Setting seed
Hierar_cl <- hclust(distance_mat, method = "average")
Hierar_cl
# Plotting dendrogram
plot(Hierar_cl)
# Choosing no. of clusters
# Cutting tree by height
abline(h = 110, col = "green")
# Cutting tree by no. of clusters
fit <- cutree(Hierar_cl, k = 3 )
fit
table(fit)
rect.hclust(Hierar_cl, k = 3, border = "green")
输出:
- 距离矩阵:
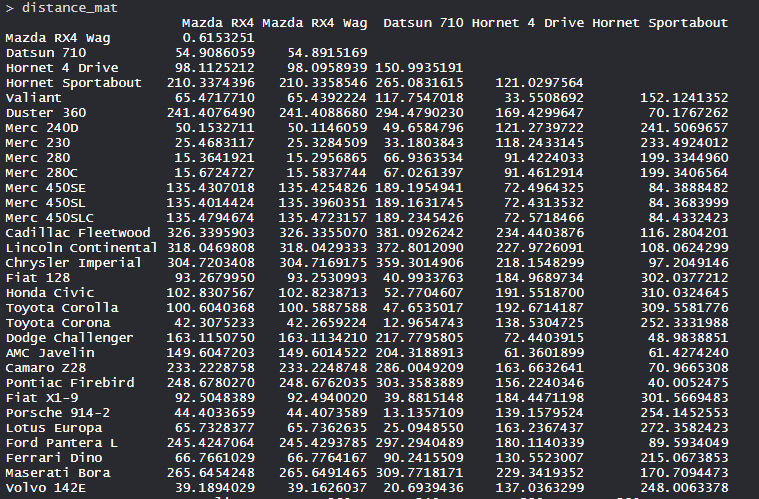
- 这些值根据距离矩阵计算显示,方法为欧几里得。
- 模型 Hierar_cl:
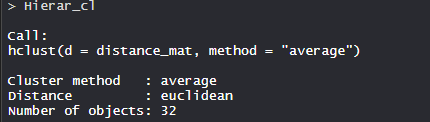
- 在模型中,聚类方法是平均的,距离是欧式的,没有。对象为 32。
- 绘制树状图:

- 绘图树状图显示为 x 轴作为距离矩阵,y 轴作为高度。
- 砍树:
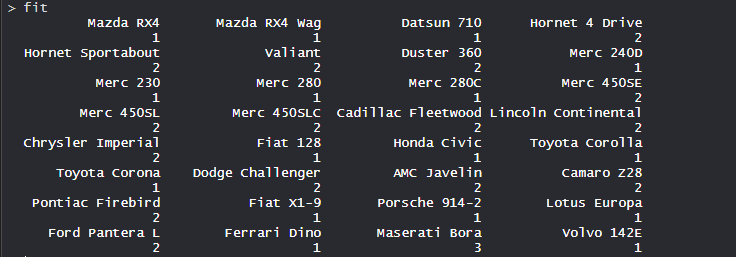
- 因此,在 k = 3 处切割树,每个类别代表其聚类数。
- 切割后绘制树状图:

- 该图表示切割后的树状图。绿线根据拇指规则显示集群的数量。