机器学习中的 DBSCAN 聚类 |基于密度的聚类
聚类分析或简称聚类,基本上是一种无监督学习方法,将数据点划分为若干特定的批次或组,使得同一组中的数据点具有相似的属性,而不同组中的数据点在某种意义上具有不同的属性。它包括许多基于差异进化的不同方法。
例如 K-Means(点之间的距离)、Affinity 传播(图距离)、Mean-shift(点之间的距离)、DBSCAN(最近点之间的距离)、高斯混合(到中心的马氏距离)、光谱聚类(图距离)等.
从根本上说,所有的聚类方法都使用相同的方法,即首先我们计算相似度,然后我们用它来将数据点聚类成组或批次。在这里,我们将重点关注基于密度的噪声应用空间聚类(DBSCAN)聚类方法。
簇是数据空间中的密集区域,由点密度较低的区域分隔。 DBSCAN 算法基于这种直观的“集群”和“噪声”概念。关键思想是,对于集群的每个点,给定半径的邻域必须至少包含最少数量的点。
为什么选择 DBSCAN?
分区方法(K-means、PAM 聚类)和层次聚类用于寻找球形簇或凸簇。换句话说,它们仅适用于紧凑且分离良好的集群。此外,它们还受到数据中存在的噪声和异常值的严重影响。
现实生活中的数据可能包含违规行为,例如:
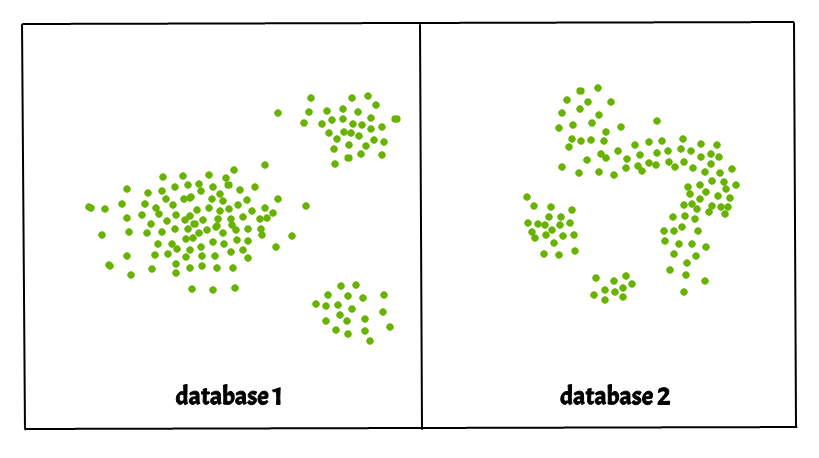
- 簇可以是任意形状,如下图所示。
- 数据可能包含噪音。

下图显示了一个包含非凸聚类和异常值/噪声的数据集。给定这样的数据,k-means 算法很难识别这些具有任意形状的簇。
DBSCAN 算法需要两个参数:
- eps :它定义了数据点周围的邻域,即如果两点之间的距离小于或等于“eps”,则它们被视为邻居。如果 eps 值选择得太小,那么大部分数据将被视为异常值。如果选择的非常大,则集群将合并,并且大多数数据点将位于相同的集群中。找到 eps 值的一种方法是基于k 距离图。
- MinPts : eps 半径内的最小邻居数(数据点)。数据集越大,必须选择更大的 MinPts 值。作为一般规则,最小 MinPts 可以从数据集中的维数 D 中得出,MinPts >= D+1。 MinPts 的最小值必须至少选择 3。
In this algorithm, we have 3 types of data points.
Core Point: A point is a core point if it has more than MinPts points within eps.
Border Point: A point which has fewer than MinPts within eps but it is in the neighborhood of a core point.
Noise or outlier: A point which is not a core point or border point.

DBSCAN 算法可以抽象为以下步骤:
- 找到 eps 内的所有相邻点并识别核心点或访问过的超过 MinPts 个相邻点。
- 对于尚未分配给集群的每个核心点,请创建一个新集群。
- 递归查找其所有密度连接点,并将它们分配给与核心点相同的集群。
如果存在一个点c ,它的邻居中有足够数量的点,并且点a和b都在eps 距离内,则称点a和b是密度连通的。这是一个链接过程。因此,如果b是c 的邻居,c是d的邻居, d是e的邻居,而 e 又是a 的邻居,这意味着b是a的邻居。 - 遍历数据集中剩余的未访问点。那些不属于任何簇的点是噪声。
下面是伪代码中的 DBSCAN 聚类算法:
DBSCAN(dataset, eps, MinPts){
# cluster index
C = 1
for each unvisited point p in dataset {
mark p as visited
# find neighbors
Neighbors N = find the neighboring points of p
if |N|>=MinPts:
N = N U N'
if p' is not a member of any cluster:
add p' to cluster C
}上述算法在Python中的实现:
在这里,我们将使用Python库 sklearn 来计算 DBSCAN。我们还将使用 matplotlib.pyplot 库来可视化集群。
使用的数据集可以在这里找到。
Python3
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
# Load data in X
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.50, random_state=0)
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print(labels)
# Plot result
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = ['y', 'b', 'g', 'r']
print(colors)
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = 'k'
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
markeredgecolor='k',
markersize=6)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
markeredgecolor='k',
markersize=6)
plt.title('number of clusters: %d' % n_clusters_)
plt.show()输出:
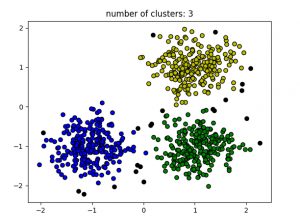
黑点代表异常值。通过更改eps和MinPts ,我们可以更改集群配置。
现在应该提出的问题是——我们为什么要使用 DBSCAN,而 K-Means 是聚类分析中广泛使用的方法?
K-MEANS的缺点:
- K-Means 仅形成球形簇。当数据不是球形时(即所有方向的方差相同),该算法会失败。
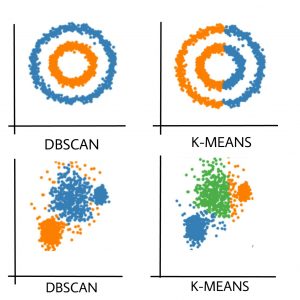
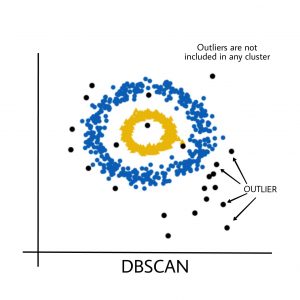
- K-Means 算法对异常值很敏感。异常值可以在很大程度上扭曲 K-Means 中的集群。
- K-Means 算法需要一个指定先验聚类的数量等。
基本上,DBSCAN 算法克服了 K-Means 算法的上述所有缺点。 DBSCAN 算法通过将基于距离测量的彼此接近的数据点组合在一起来识别密集区域。
可以在此处找到不使用 sklearn 库的上述算法的Python实现 dbscan_in_python。参考 :
https://en.wikipedia.org/wiki/DBSCAN
https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html