使用 OLS 摘要解释线性回归的结果
这篇文章就是告诉你回归汇总表的整体解读。用于回归分析的统计软件有很多,如 Matlab、Minitab、spss、R 等,但本文使用的是Python。其他工具的解释也相同。本文需要统计的基础知识,包括回归、自由度、标准差、残差平方和(RSS)、ESS、t统计等基础知识。
在回归中有两种类型的变量,即因变量(也称为解释变量)和自变量(解释变量)。
这里使用的回归线是,

下面给出了回归的汇总表。
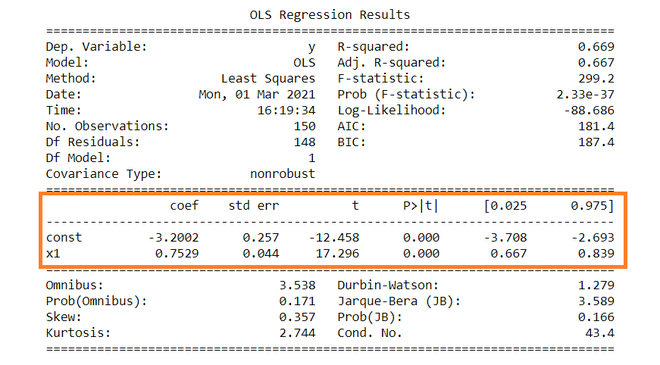
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.669
Model: OLS Adj. R-squared: 0.667
Method: Least Squares F-statistic: 299.2
Date: Mon, 01 Mar 2021 Prob (F-statistic): 2.33e-37
Time: 16:19:34 Log-Likelihood: -88.686
No. Observations: 150 AIC: 181.4
Df Residuals: 148 BIC: 187.4
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.2002 0.257 -12.458 0.000 -3.708 -2.693
x1 0.7529 0.044 17.296 0.000 0.667 0.839
==============================================================================
Omnibus: 3.538 Durbin-Watson: 1.279
Prob(Omnibus): 0.171 Jarque-Bera (JB): 3.589
Skew: 0.357 Prob(JB): 0.166
Kurtosis: 2.744 Cond. No. 43.4
==============================================================================因变量:因变量是依赖于其他变量的变量。在这个回归分析中, Y是我们的因变量,因为我们要分析X对Y的影响。
模型:普通最小二乘法(OLS)因其效率而成为最广泛使用的模型。该模型给出了真实人口回归线的最佳近似值。 OLS 的原理是最小化误差的平方 ( ∑e i 2 )。
观察次数:观察次数是我们样本的大小,即N = 150。
残差的自由度(df):
自由度是独立观察的数量,在此基础上计算平方和。
Df 残差 = 150 – (1+1) = 148
自由度(Df)计算如下,
自由度, D。 f = N – K
其中, N =样本量(观察数), K =变量数 + 1
模型的df:
模型的 Df = K – 1 = 2 – 1 = 1 ,
其中, K =变量数 + 1
常数项:常数项是回归线的截距。从回归线 (eq…1) 来看,截距是 -3.002。在回归中我们省略了一些对因变量没有太大影响的自变量,截距告诉了这些省略变量的平均值和模型中存在的噪声。
系数项:系数项表示X单位变化时Y的变化,即如果X增加 1 个单位,则Y增加 0.7529。如果您熟悉导数,那么您可以将其与Y相对于X的变化率联系起来。
参数的标准误差:标准误差也称为标准偏差。标准误差显示了这些参数的抽样变异性。标准误差的计算方式为 -
截距项 (b1) 的标准误差:
系数项的标准误差(b2):

这里,σ 2是回归的标准误差 (SER)。并且σ 2等于RSS(Residual Sum Of Square,即∑e i 2 )。
t – 统计:
理论上,我们假设误差项服从正态分布,因此参数b 1和 b 2也有正态分布,方差在上节计算。
那是 ,
- b 1 ∼ N(B 1 , σ b1 2 )
- b 2 ∼ N(B 2 , σ b2 2 )
这里B 1和B 2是b1 和b2 的真均值。
t – 通过假设以下假设来计算统计数据 –
- H 0 : B 2 = 0(变量 X 对 Y 没有影响)
- H a : B 2 ≠ 0(X 对 Y 有显着影响)
t – 统计量的计算:
t = ( b 1 – B 1 ) / se (b 1 )
从汇总表中,b 1 = -3.2002 和 se(b 1 ) = 0.257,所以,
t = (-3.2002 – 0) / 0.257 = -12.458
类似地, b 2 = 0.7529 ,se(b 2 ) = 0.044
t = (0.7529 – 0) / 0.044 = 17.296
p - 值:
理论上,我们读到 p 值是获得 t 统计量的概率,该统计量至少与假设原假设为真计算得出的 H 0矛盾。在汇总表中,我们可以看到两个参数的 P 值都等于 0。这不完全是 0,但由于我们有非常大的 t 统计量(-12.458 和 17.296),p 值将近似为 0。
如果您了解显着性水平,那么您会发现我们几乎可以在每个显着性水平上拒绝原假设。
置信区间:
有许多方法可以检验假设,包括上面提到的 p 值方法。置信区间方法就是其中之一。 5% 是制作 CI 的标准显着性水平 (∝)。
B 1 的CI 是( b 1 – t ∝/2 se(b 1 ) , b 1 + t ∝/2 se(b 1 ) )
由于 ∝ = 5 %, b 1 = -3.2002, se(b 1 ) =0.257,来自 t 表,t 0.025,148 = 1.655,
输入值后,B 1的 CI 约为。 ( -3.708 , -2.693 )。对于 b 2也可以这样做。
在计算 p 值时,我们拒绝了原假设,我们也可以在 CI 中看到相同的情况。由于 0 不在任何区间内,因此我们将拒绝原假设。

R - 平方值:
R 2是决定系数,它告诉我们自变量可以解释多少百分比变异。在这里,Y 中 66.9% 的变化可以用 X 来解释。R 2的最大可能值可以是 1,这意味着 R 2值越大,回归越好。
F——统计:
F 检验说明回归的拟合优度。该检验类似于我们为假设所做的 t 检验或其他检验。 F – 统计量计算如下 –

插入 R 2 、n 和 k 的值,F = (0.669/1) / (0.331/148) = 229.12。
您可以计算 1 和 148 df 的 F >229.1 的概率,大约为0. 由此,我们再次拒绝上述原假设。
其余术语不常使用。 Skewness 和 Kurtosis 等术语说明了数据的分布。正态分布的偏度和峰度分别为 0 和 3。 Jarque-Bera 测试用于检查错误是否具有正态分布。