线性回归:
它是预测分析的常用类型。这是一种统计方法,用于建模因变量和给定的一组自变量之间的关系。
线性回归有两种类型。
- 简单线性回归
- 多元线性回归
让我们讨论使用R的简单线性回归。
简单线性回归:
这是一种统计方法,可让我们总结和研究两个连续(定量)变量之间的关系。标记为x的一个变量被视为自变量,标记为y的另一个变量被视为因变量。假定这两个变量是线性相关的。因此,我们试图找到预测的响应值(y)的尽可能准确地作为特征或独立变量(x)的函数的线性函数。
为了理解这个概念,让我们考虑一个薪水数据集,其中为每个自变量(工作年限)提供因变量(薪水)的值。
薪水数据集
Years experienced Salary
1.1 39343.00
1.3 46205.00
1.5 37731.00
2.0 43525.00
2.2 39891.00
2.9 56642.00
3.0 60150.00
3.2 54445.00
3.2 64445.00
3.7 57189.00
出于一般目的,我们定义:
x作为特征向量,即x = [x_1,x_2,…。,x_n],
y作为响应向量,即y = [y_1,y_2,…。,y_n]
对于n个观察值(在上面的示例中,n = 10)。
给定数据集的散点图: 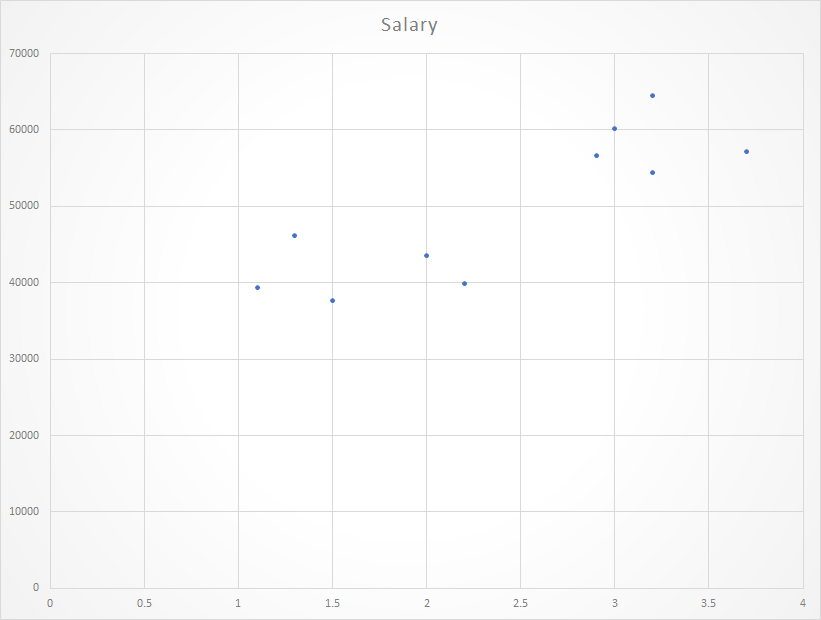
现在,我们必须找到一条适合上述散点图的线,通过该线我们可以预测y的任何值或x的任何值的响应
最合适的线称为回归线。
回归线的方程式为:
y = a + bx 其中y是预测的响应值,a是y截距,x是特征值,b是斜率。
为了创建模型,让我们评估回归系数a和b的值。一旦完成这些系数的估计,就可以预测响应模型。在这里,我们将使用最小二乘技术。
最小二乘法的原理是找到适合给定数据的曲线的流行方法之一。说(x1,y1),(x2,y2)….(xn,yn)是实验中的n个观察值。我们有兴趣找到一条曲线
![]()
紧密拟合大小为’n’的给定数据。现在,在x = x1处,当y的观测值为y1时,曲线(1)的y的预期值为f(x1)。那么残差可以由…定义。 ![]()
类似地,x2,x3…xn的残差由…给出
![]()
![]()
![]()
在评估残差时,我们会发现一些残差为正,而有些则为负。我们期待找到适合给定数据的曲线,以使任何xi处的残差最小。由于某些残差为正,而其他残差为负,并且由于我们希望对所有残差给予同等的重视,因此考虑这些残差的平方和是可取的。因此,我们考虑:
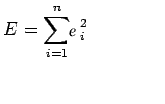
并找到最佳的代表曲线。
直线的最小二乘拟合
假设给定一个数据集(x1,y1),(x2,y2),(x3,y3)…..(xn,yn),来自一个实验的n个观测值。我们对拟合直线感兴趣。 ![]()
给定的数据。
现在考虑: ![]()
现在考虑ei的平方和
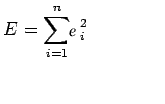
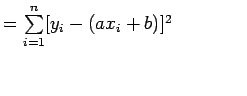
注意: E是参数a和b的函数,我们需要找到a和b使得E最小,而E最小的必要条件如下:
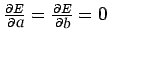
此条件产生: 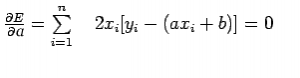
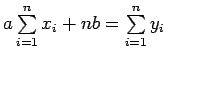
上面的两个方程称为正态方程,可以求解它们以获得a和b的值。
E的表达式可以重写为: 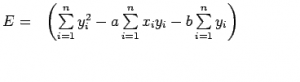
R中回归分析的基本语法是
lm(Y ~ model) 其中Y是包含要预测的因变量的对象,而model是所选数学模型的公式。
命令lm()提供了模型的系数,但没有提供进一步的统计信息。
以下R代码用于实现SIMPLE LINEAR REGRESSION :
# Simple Linear Regression
# Importing the dataset
dataset = read.csv('salary.csv')
# Splitting the dataset into the
# Training set and Test set
install.packages('caTools')
library(caTools)
split = sample.split(dataset$Salary, SplitRatio = 0.7)
trainingset = subset(dataset, split == TRUE)
testset = subset(dataset, split == FALSE)
# Fitting Simple Linear Regression to the Training set
lm.r= lm(formula = Salary ~ YearsExperience,
data = trainingset)
coef(lm.r)
# Predicting the Test set results
ypred = predict(lm.r, newdata = testset)
install.packages("ggplot2")
library(ggplot2)
# Visualising the Training set results
ggplot() + geom_point(aes(x = trainingset$YearsExperience,
y = trainingset$Salary), colour = 'red') +
geom_line(aes(x = trainingset$YearsExperience,
y = predict(lm.r, newdata = trainingset)), colour = 'blue') +
ggtitle('Salary vs Experience (Training set)') +
xlab('Years of experience') +
ylab('Salary')
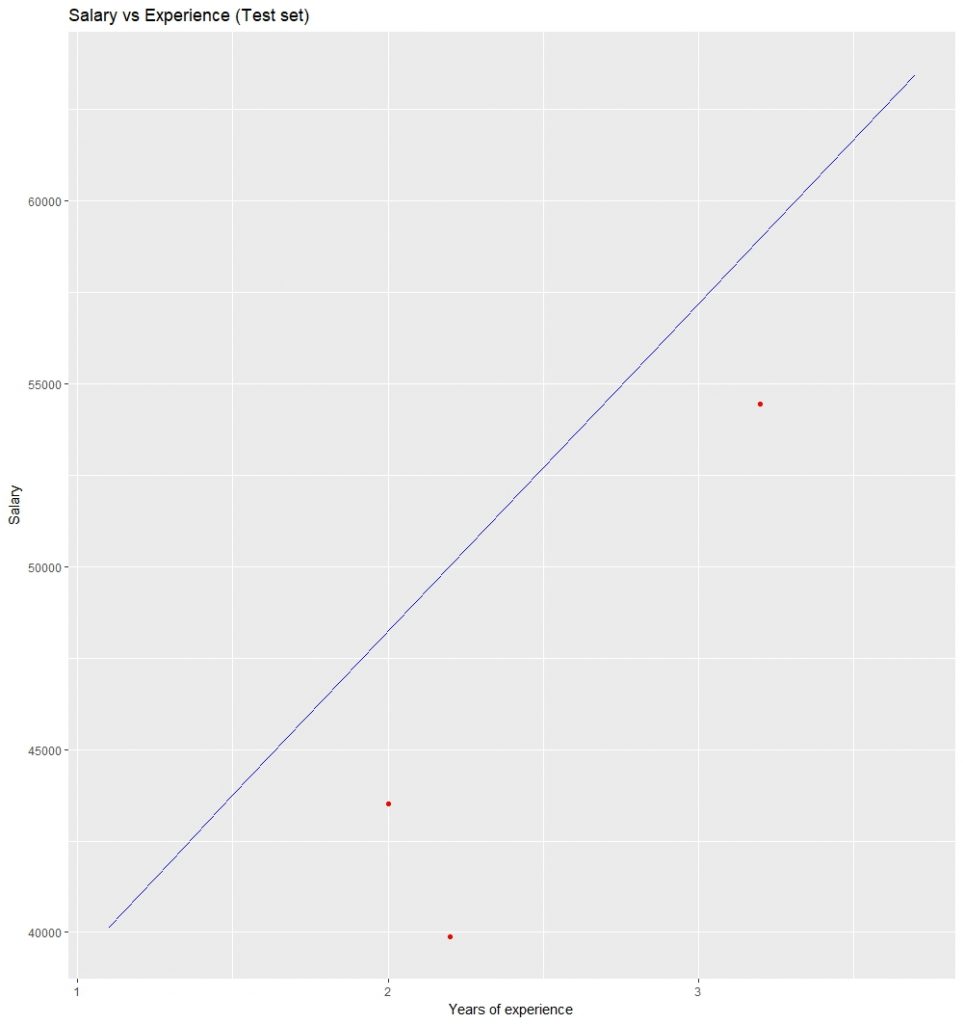
# Visualising the Test set results
ggplot() +
geom_point(aes(x = testset$YearsExperience, y = testset$Salary),
colour = 'red') +
geom_line(aes(x = trainingset$YearsExperience,
y = predict(lm.r, newdata = trainingset)),
colour = 'blue') +
ggtitle('Salary vs Experience (Test set)') +
xlab('Years of experience') +
ylab('Salary')
coef(lm.r)的输出:
拦截年经验
24558.39 10639.23
可视化训练集结果: 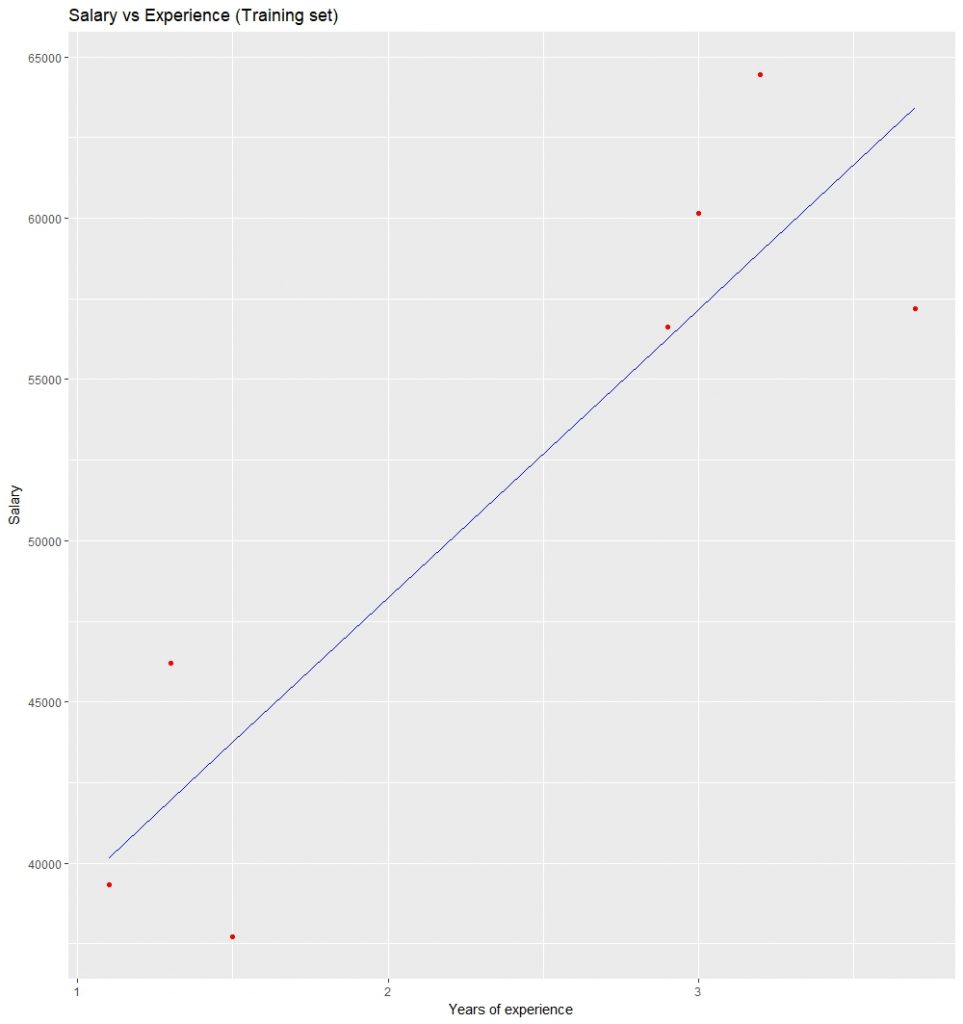
可视化测试集结果: